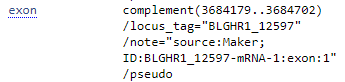
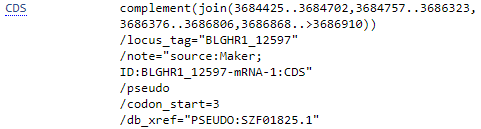
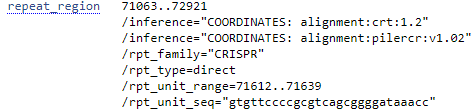
Для рассмотрения был выбран геном Japanese macaque(Японский макак). Японские макаки являются самыми северными в мире обезьянами, ареал их обитания простирается до севера острова Хонсю.
На севере Японии, где снег может лежать до четырёх месяцев в году, а средняя температура зимы составляет ?5 °C,
обезьяны проводят морозы в горячих источниках. В холодные дни снежные обезьяны, находящиеся в тёплой воде, становятся
её заложниками: когда они выходят за едой, из-за мокрой шерсти они мёрзнут ещё больше. Тогда у обезьян срабатывает своеобразная
система дежурства для пропитания сидящей в воде группы: двое животных с сухой шерстью подносят пищу, пока другие сидят в воде.
Был найден всего одина сборка генома японской макаки: macFus_1.0. macFus_1.0.
Таблица 1:характеристика сборки генома Японской макаки.
Организм |
Macaca fuscata fuscata (Japanese macaque) |
|---|---|
Сборка |
macFus_1.0 |
Общая длина сборки |
2,930,706,173 |
Число контигов сборки |
90,905 |
Число скэффолдов сборки |
25,136 |
N50 |
94,905 |
L50 |
8,516 |
В данном проекте не аннотированы белки, всего на NCBI опубликована информация о 75 белках японской макаки.
Ссылка на публикацию с описанием проекта.
Ссылка на последовательность одного из контигов..
Таблица 2:примеры ключей, используемых в таблицах особенностей INCDS.
Название |
Определение |
Примеры квалификаторов-qualifiers |
Примеры |
|---|---|---|---|
exon |
Участок ДНК, копия которого входит в состав зрелой РНК. |
/product="text" |
UNSH01000041.1 |
intron |
Сегмент ДНК, не несущий информацию о первичной структуре белка и расположенный между кодирующими участками - экзонами. Транскрибируется в РНК, но вырезается из продукта транскрипции. |
/experiment="[CATEGORY:]text" |
AB364238.1 |
CDS |
Последовательность нуклеотидов, соответсвующая последовательности аминокислот в белке. !Включает стоп-кодон! |
/protein_id=" |
UNSH01000041.1 |
mat_peptide |
"Зрелая", кодирующая белок, последовательность, то есть последовательность прошедшая пострансляционные модификации, готовая дя трансляции. !Не включает стоп-кодон! |
/db_xref=" |
X01787.1 |
repeat_region |
Фрагмент генома, содержащий повторяющиеся участки |
/rpt_family="text" |
NZ_RDDF01000022.1 |
S_region |
Участок переключения тяжелой цепи иммуноглобулина: участвует в перегруппировке ДНК тяжелой цепи, вызывающей выработку другого класса иммуноглобулина в той же В-клетке. |
/experiment="[CATEGORY:]text" |
MG904684.1 |
misc_feature |
Регион, который не может быть описан другими ключами особенностей(новая или редкая последовательность) |
/db_xref=" |
NM_001366603.1 |
100 тысяч геномов патогенов(100K Pathogen Project)- массовый геномные проект запущенный в 2012 году Бартом Веймером. Проэкт возглавляется
лабораторией Веймера.
Целью проекта является отсеквенировать 100 тысяч геномов патогенных бактерий. В данном проектов основном рассматриваются бактерии, попадающие
в организм человека с зараженной пищей. По результатам проекта планируется создать базу данных геномов патогенных микроорганизмов, а также выявить генетические маркеры
определенных групп бактерий. Информация, полученная по результатам исследований должна ускорить определение причин пищевых отравлений, а так же
сделать более надежным анализ пищи на пригодность и безопасность.
На данный момент отсиквеноровано более 35 000 геномов. Последняя публикация по проекту связана с
определением генов-маркеров листерии(ссылка на публикацию).
Подробнее о проекте можно узнать на их
главном сайте.
Поиск производился по ENA (EMBL) на сайте EBI, текст запроса:tax_tree(10197) AND mol_type="genomic DNA" AND topology="CIRCULAR" AND organelle="mitochondrion". По
результатам поиска всего 8 находок и все в Release.
Для рассмотрения был выбран Beroe forskalii (AC митохондриального генома:MG655622.1).

Таблица 2:гены белков, закодированных в митохондриальном геноме:
Короткое название гена |
Координаты в геноме |
Полное название |
Индентификатор белка |
|---|---|---|---|
COX1 |
1..1524 |
cytochrome c oxidase subunit I |
AWK60573.1 |
ND1 |
3099..3302 |
NADH dehydrogenase subunit 1 |
AWK60584.1 |
COX3 |
3308..4051 |
cytochrome c oxidase subunit III |
AWK60579.1 |
ND3 |
4324..4698 |
NADH dehydrogenase subunit 3 | AWK60583.1 |
ND4 |
4699..5781 |
NADH dehydrogenase subunit 4 |
AWK60575.1 |
ND4L |
5799..5969 |
NADH dehydrogenase subunit 4L |
AWK60585.1 |
ND5 |
5981..7459 |
NADH dehydrogenase subunit 5 |
AWK60574.1 |
- |
7608..8672 |
NADH dehydrogenase subunit 2-like protein |
AWK60576.1 |
- |
9200..9868 |
hypothetical protein |
AWK60581.1 |
ND2 |
10016..10744 |
NADH dehydrogenase subunit 2 |
AWK60580.1 |
CYTB |
10863..11918 |
cytochrome b |
AWK60577.1 |
ND1 |
11837..12751 |
NADH dehydrogenase subunit 1 |
AWK60578.1 |
COX2 |
12757..13320 |
cytochrome c oxidase subunit II |
AWK60582.1 |
Третий семестр(осенний семестр 2018)