Все файлы по данному практикуму находяться в папке Practice11.
Для проведения 3DQSAR анализа мы будем использовать программы Open3DQSAR и Open3DALIGN (open3dqsar.sourceforge.net). Чтобы использовать их на kodomo, добавляем к переменной PATH директорию /home/preps/grishin/open3dtools/bin):
export PATH=$PATH:/home/preps/grishin/open3dtools/binЭти программы поддерживают как работу в интерактивном режиме, так и выполнение скриптов. Можно выбрать то, что больше удобно.
Итак, нам дан набор из 88 веществ – ингибиторов тромбина (compounds.sdf). Для 85 из них активность известна, для трех – нам предстоит предсказать.
Для начала необходимо построить пространственное выравнивание активных конформаций исследуемых веществ.
Будем считать активной конформацией (то есть конформацией, в которой вещество-ингибитор взаимодействует с белком-мишенью)
наиболее энергетически выгодную конформацию (часто это вполне соответствует истине).
Попробуем сгенерировать эти конформации, используя программу obconformer из пакета OpenBabel:
obconformer 100 100 compounds.sdf> compounds_best_conformer.sdfК сожалению, это занимает порядка 40 минут, поэтому лучше взять уже готовый файл (compounds_best_conformer.sdf).
Далее необходимо сделать выравнивание полученных конформеров. Попробуем сделать это с помощью программы Open3DALIGN (open3dalign.sourceforge.net). Документацию смотрите на сайте. Запустите программу:
open3dalign.sh
Чтобы сделать выравнивание нужно загрузить ваш SDF файл со структурами веществ:
import type=SDF file=compounds_best_conformer.sdfИ выполнить выравнивание:
align object_list=1 save file=aligned.sdf
Перекодировать из юникода в ascii:
Iconv -C -F UTF-8-Т ASCII aligned.sdf> aligned_ascii.sdfУдалить ненужную информацию из заголовков и добавить $$$$ в конец каждой записи:
SED-E 'S /. * заголовке. * \ ([0-9] [0-9] \). * / \ 1 /' -E 'S / \ (. * M END. * \) / \ 1 \ п $ $ $ $ / ' aligned_ascii.sdf> Temp но-N '/ ^ [0-9-Za-Z \ $ \ -.] * $ / р' TEMP> aligned_ok.sdf RM Temp
Полученный файл можно открыть и визуально проанализировать в Pymol
Теперь мы можем попробовать выполнить непосредственно 3DQSAR анализ и посмотреть, получается ли построить регрессионную модель с помощью такого выравнивания. Запускаем программу:
open3dqsar.shВсе дальнейшие команды вводим в командной строке open3dqsar. Загружаем файл со структурами:
import type=sdf file=aligned_ok.sdfЗагружаем файл с данными об активности исследуемых соединений (activity.txt):
import type=dependent file=activity.txtАктивности трех последних соединений нам предстоит предсказать, поэтому для них пока что указана нулевая активность. Задаем решетку вокруг исследуемых соединений:
boxДополнительные параметры команд можно посмотреть в разделе документация на сайте программы. Оставим часть наших соединений в качестве тестового набора, и не будем использовать их для построения модели, а также исключим (пока что) соединения с неизвестной активностью:
set object_list=60-85 attribute=TEST set object_list=86-88 attribute=EXCLUDEDРассчитаем значения энергии ван-дер-Ваальсовых взаимодействий в узлах решетки:
calc_field type=VDW force_field=MMFF94 probe_type=CRВ некоторых узлах решетки псевдо-атом зонда (probe) находится слишком близко к атомам исследуемых содеинений, и дает слишком большую по модулю энергию. Установим ограничения на значения энергии:
cutoff type=max level=5.0 field_list=1 cutoff type=min level=-5.0 field_list=1Слишком маленькие значения энергии приравняем к 0:
zero type=all level=0.05Исключим из анализа ячейки, в которых вариабельность в энергии взаимодействия с зондом для разных соединений мала:
sdcut level=0.1 Nlevel remove_x_vars type=nlevelНаконец, построим регрессионную модель:
PlsПолучили коэффициенты корреляции для разного количества компонент, выделенных PLS.
Exp. Cum. exp. Exp. Cum. exp.
PC var. X % var. X % var. Y % var. Y % SDEC r2
--------------------------------------------------------------------------
0 0.0000 0.0000 0.0000 0.0000 0.9494 0.0000
1 7.3852 7.3852 39.6551 39.6551 0.7375 0.3966
2 4.5272 11.9123 34.6556 74.3107 0.4812 0.7431
3 4.0303 15.9427 15.9744 90.2851 0.2959 0.9029
4 4.6388 20.5814 4.8265 95.1116 0.2099 0.9511
5 4.4540 25.0354 2.9577 98.0692 0.1319 0.9807
Все коэффициенты корреляции получились больше 0, 4 из них стремятся к 1, так что модель можно
считать хорошей.
Попробуем выполнить кросс-валидацию:
cv type=loo runs=20Кросс-валидация:
PC SDEP q2 -------------------------- 0 0.9658 -0.0348 1 1.0194 -0.1529 2 1.1152 -0.3798 3 1.0963 -0.3334 4 1.0994 -0.3410 5 1.0744 -0.2808 Elapsed time: 1.5306 seconds.Если q2 это новый коэффициент корреляции, то он не очень хороший, так как везде меньше 0.
Предсказать активность для тестовой выборки:
predictПредсказанные коэффициенты корреляции
PC r2(pred) SDEP -------------------------- 0 0.0000 1.0362 1 -0.0525 1.0631 2 0.0627 1.0032 3 -0.0352 1.0543 4 -0.0669 1.0703 5 0.0162 1.0278 Elapsed time: 0.0260 seconds.Предсказанные коэффициенты корреляции совсем невелики, половина из них меньше 0. Полученные значения это что-то среднее между коэффициентами нашей модели и кросс-валидации.
Теперь попробуем выполнить тот же анализ, но используя выравнивание и конформации, полученные с учетом структуры активного центра белка-мишени (на самом деле они находятся в исходном файле compounds.sdf). Для постороения выравнивания пользуемся программой open3dalign.sh:
open3dalign.sh import type=SDF file=compounds.sdf align object_list=1 save file=aligned_2.sdfТеперь снова модифицируем для просмотра в Pymil
iconv -c -f utf-8 -t ascii aligned_2.sdf > aligned_ascii_2.sdf sed -e 's/.*HEADER.*\([0-9][0-9]\).*/\1/' -e 's/\(.*M END.*\)/\1\n$$$$/' aligned_ascii_2.sdf > temp sed -n '/^[0-9a-zA-Z \$\.-]*$/ p' temp > aligned_ok_2.sdf rm tempВ результате получаем выравнивание с учетом структуры активного центра белка-мишени
Повторяем анализ open3dqsar.sh с этим выравниванием
open3dqsar.sh import type=sdf file=aligned_ok_2.sdf import type=dependent file=activity.txt box set object_list=60-85 attribute=TEST set object_list=86-88 attribute=EXCLUDED calc_field type=VDW force_field=MMFF94 probe_type=CR cutoff type=max level=5.0 field_list=1 cutoff type=min level=-5.0 field_list=1 zero type=all level=0.05 sdcut level=0.1 nlevel remove_x_vars type=nlevel pls cv type=loo runs=20 predictКоэффициенты корреляции для разного количества компонент, выделенных PLS
Exp. Cum. exp. Exp. Cum. exp.
PC var. X % var. X % var. Y % var. Y % SDEC r2
--------------------------------------------------------------------------
0 0.0000 0.0000 0.0000 0.0000 0.9494 0.0000
1 12.1342 12.1342 48.4736 48.4736 0.6815 0.4847
2 13.2295 25.3637 14.5885 63.0621 0.5770 0.6306
3 7.6412 33.0049 13.2040 76.2661 0.4625 0.7627
4 8.0257 41.0305 4.3684 80.6345 0.4178 0.8063
5 6.0521 47.0827 3.8642 84.4987 0.3738 0.8450
Elapsed time: 0.1512 seconds.
Кросс-валидация
PC SDEP q2 -------------------------- 0 0.9658 -0.0348 1 0.8027 0.2851 2 0.7664 0.3484 3 0.7061 0.4468 4 0.6735 0.4968 5 0.6401 0.5454 Elapsed time: 0.1422 seconds.Предсказанные коэффициенты корреляции
PC r2(pred) SDEP -------------------------- 0 0.0000 1.0362 1 0.3451 0.8385 2 0.3226 0.8529 3 0.2998 0.8671 4 0.3012 0.8662 5 0.2693 0.8858 Elapsed time: 0.0067 seconds.В целом коэффициенты PLS получились неплохие, все больше 0, но сами значения хуже, чем в случае первого выравнивания. А вот кросс-валидация получилась лучше, только одно значение меньше 0. Предсказанные коэффициенты тоже получились лучше, отрицательных значений нет, хотя сами значения и далеки от 1.
Попробуем использовать получившуюся модель для предсказания активности. Для начала, переделаем модель с использованием всех имеющихся данных, а вещества с неизвестной активностью обозначим как тестовую выборку:
set object_list=60-85 attribute=TRAINING set object_list=86-88 attribute=TESTПостроим модель и предскажем активность трех веществ:
Pls predictКоэффициенты корреляции для разного количества компонент, выделенных PLS
Exp. Cum. exp. Exp. Cum. exp.
PC var. X % var. X % var. Y % var. Y % SDEC r2
--------------------------------------------------------------------------
0 0.0000 0.0000 0.0000 0.0000 0.9749 0.0000
1 12.8375 12.8375 44.4004 44.4004 0.7269 0.4440
2 14.5264 27.3638 14.3748 58.7753 0.6260 0.5878
3 6.9607 34.3245 11.2007 69.9760 0.5342 0.6998
4 8.4659 42.7904 5.4939 75.4699 0.4828 0.7547
5 4.7600 47.5503 5.7466 81.2166 0.4225 0.8122
Elapsed time: 0.2075 seconds.
Предсказанные коэффициенты
PC r2(pred) SDEP -------------------------- 0 0.0000 6.6604 1 0.0294 6.5616 2 -0.0102 6.6942 3 0.0265 6.5717 4 -0.0480 6.8183 5 -0.0950 6.9696 Elapsed time: 0.0067 seconds.6*) Давайте теперь посмотрим на вашу модель в PyMOL. После того, как вы построили модель командой pls, набираем команду:
export type=coefficients pc=5 format=insight file=coefsОткрываем PyMOL, загружаем туда файл со структурами, а также получившийся в результате экспорта файл coefs_fld-01_y-01.grd. В этом файле находится информация о коэффициентах модели в каждой точки решетки. Такого рода данные можно визуализовать в PyMOL с помощью команды isosurface, которая рисует поверхность, построенную из всех точек, в которых коэффициенты равны заданному значению:
isosurface positive, coefs_fld-01_y-01, 0.00001для отображения области, соответствующей коэффициентам 0.00001, и
isosurface negative, coefs_fld-01_y-01, -0.00001соответственно, для -0.00001.
В результате получаем следующие изображения для положительных значений (слева) и отрицательных (справа)

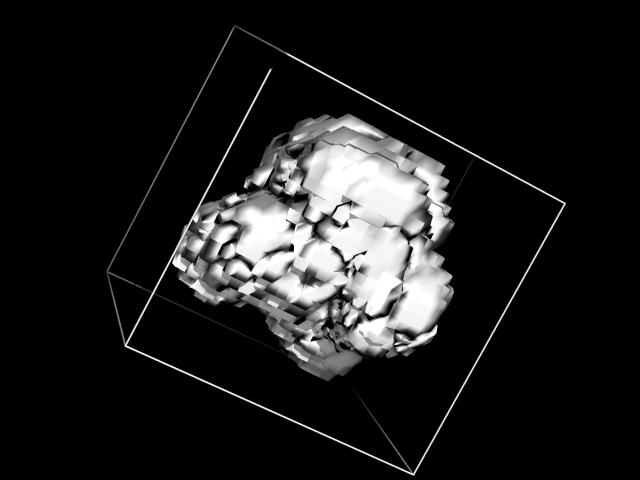 Визуализация наглядно демонстрирует, что точек, равных -0.00001 значительно больше, чем
0.00001.
Визуализация наглядно демонстрирует, что точек, равных -0.00001 значительно больше, чем
0.00001.