Словари¶
Часто перед нами встает задача по какому-то, нечисленному, значению, найти соответствующее ему другое значение. Например, по ФИО человека номер его паспорта
Словарь (dict) – это тип данных, хранящий соответствие одних значений другим (ключам словаря). Самым простым способом создания словаря является задание его при помощи фигурных скобок ({})
my_dict = { "Dmitry" : 5,
"Alexander" : 10,
"Jupyter": 20}
my_dict
Соответственно, чтобы получить значение, соответствующее ключу, необходимо набрать имя словаря и ключ в квадратных скобках.
my_dict['Jupyter']
В случае, если ключа с таким значением нет, получите ошибку:
my_dict['Dogs']
Можно использовать метод dict.get(key, default_value=None) для того, чтобы в случае отсутствия ключа в словаре получать какое-то значение по-умолчанию
print (my_dict.get("Dogs")) # return None
my_dict.get("Dogs", 5)
my_dict.get("Jupyter", 5)
Проверка наличия ключа в словаре¶
Как и для других коллекций, для проверки наличия ключа в словаре используется слово in
if "Dogs" in my_dict:
print("Hello")
else:
print("World")
Проход по ключам словаря¶
Проход по ключам словаря можно сделать двумя способами
Учтите, что методы словаря, "возвращающие" хранимое в нем, возвращают не-совсем-списки, с этим нельзя работать как со списком
my_dict.keys()
for key in my_dict.keys():
print (key)
for key in my_dict:
print (key)
Проход по значениям словаря¶
my_dict.values()
for value in my_dict.values():
print (value)
Проход по ключам и значениям словаря
for key in my_dict.keys():
value = my_dict[key]
print (key, value)
my_dict.items()
for key, value in my_dict.items():
print (key, value)
list(my_dict.keys())
list(my_dict.values())
list(my_dict.items())
Добавление элементов в словарь¶
Словарь может хранить любой объект в качестве значения, однако в качестве ключа ему необходимы особые объекты, в первом приближении неизменяемые - числа и строки, например.
d = dict() # another way to create dict
# d = {}
d[10] = "Hello"
d
d["hello"] = "world"
d
my_key = "hi"
my_value = [1,2,3]
d[my_key] = my_value
d
d[[1,2,3]] = 5
# error, list is mutable (unhashable, to be precise)
to_i_key = (1,2,3)
to_i_value = "art"
a = {'ac': 33, 'gw': 20, 'ap': 102, 'za': 321, 'bs': 10, "acccccc": 10}
a[to_i_key] = to_i_value
a
Дополнительная информация¶
В модуле collections есть несколько модификаций стандартного словаря, позволяющих делать некоторые действия значительно проще (к примеру, подсчет разных элементов в списке)
Например, Counter легко может помочь в решении некоторых домашних работ:)
from collections import Counter
nucleotides = ["A", "T", "G", "C"]
seq = "ATAATATATATGAGGCGGCGCGCGCG"
cnt = Counter(seq)
print(cnt)
for n in nucleotides:
print (cnt[n])
Порядок ключей в словаре¶
До версии Python3.5 включительно никто не гарантировал вам никакого порядка ключей в словаре. То есть то, как они вам выдавались функцией keys и т.д не зависело ни от порядка вставки элементов, не от результата их сравнения напрямую.
Однако с версии Python3.6 в наиболее распространненой реализации (CPython), а с версии Python3.7 - в любой, порядок ключей в словаре соответствует порядку их вставки в него. Если ключ уже существовал в словаре и вы его перезаписали, то порядок ключей не изменится.
Преимущества словарей¶
Получение значения по ключу и добавление нового ключа в словарь происходит значительно быстрее, чем если бы вам пришлось перебирать список в поисках нужного значения. Вследствие этого есть огромный набор задач, где словари использовать можно и нужно. Вместе со списками — возможность представить структуру данных любой сложности (дополнительная информация — json).
Недостатки словарей¶
Словари "кушают" много памяти. Все операции на словарях быстры в среднем — отдельная операция может длиться очень долго.
Кортежи¶
Если очень хочется сделать ключом словаря список, то нужно использовать не list, а другой тип данных — кортеж (tuple). Кортеж, на первый взгляд, отличается от списка только заменой квадратных скобок на круглые, например:
ta = (1, 2, 5, 4)
ta[0]
a = (1)
print (a)
a = (1, )
print(a)
Кортеж во многом похож на список, но главным отличием является то, что кортеж неизменяем.
ta[0] = 5
dt = {}
dt[(1, 2)] = "Hello"
dt[(2, 1)] = "world"
dt
dt[(1,2)]
Кроме возможности служить ключом словаря, в случае кортежей, операции доступа (получить элемент кортежа, срез и т.д.) выполняются для кортежа быстрее. Python может оптимизировать работу программы, в которой создается множество кортежей малой длины, что для списков недоступно. С другой стороны, любая операция редактирования кортежа приводит к созданию нового кортежа, что в больших количествах может замедлить работу программы и съесть память вашего компьютера.
Множество¶
В некоторых случаях удобно пользоваться типом данных "множество" (set). Это именно множество в математическом смысле этого слова, то есть его элементы уникальны и не могут повторяться (в отличие от списка и кортежа).
s = {-10, 20, 45}
s.add(348)
s.add(-100000)
s
s = {-10:0, 20:0, 45:0}
s[348] = 0
s[-100000] = 0
s
my_set1 = {1, 7, 9} # first way to create set
my_set2 = set([0, -4, 10, 1]) # second way
lst = [1, 10, -5, -5, 20]
my_set = set(lst)
my_set
Множества используются в типичном решении того, как оставить в списке только уникальные элементы
lst = [1, 10, -5, -5, 20, -10, 20, 0, 0, 0]
my_set = set(lst)
unique_lst = list(my_set)
unique_lst
На множествах определены операции объединения, пересечения и разности.
my_set1 & my_set2 # intersection
my_set1 | my_set2 # join
my_set1 - my_set2 # difference
my_set1.symmetric_difference(my_set2)
Проверку на наличие элемента в множестве можно провести при помощи уже известного вам ключевого слова in
5 in my_set1
nucleotides = {"A", "G", "T", "U", "C"}
n = input()
if not (n in nucleotides):
print ("error")
nucleotides = {"A", "G", "T", "U", "C"}
n = input()
if n not in nucleotides:
print ("error")
Множество — изменяемый тип (не может быть ключом словаря, но может быть значением словаря, что можно применить в задании 6). Изменяемость нужна, чтобы использовать удобные в некоторых ситуациях методы add, pop и remove (см. help(set.add) и т.п.).
print (my_set1.pop())
my_set1
my_set1.add(5)
my_set1
Порядок элементов в множестве¶
Порядок элементов в множестве по-прежнему не гарантирован и не зависит ни от чего. У вас результат запуска может отличаться, к примеру)
s = {-10, 20, 45}
s.add(348)
s.add(-100000)
s
Frozenset¶
Неизменяемым аналогом set является frozenset. В отличии от обычного множества его можно использовать в качестве ключа в словаря.
my_frozen = frozenset([4, 5, 6])
my_frozen
my_frozen.add(4)
Повторение пройденного. Файлы¶
Немного копипасты из моих же подсказок прошлого года:)
Все открытые файлы автоматически закрываются, когда программа заканчивает работу. И потому все будет прекрасно работать, пока вы не решите создавать в своей программе промежуточные файлы, информация из которых затем используется в программе. Тут внезапно выяснится, что вы что-то записали в файл, не закрыв его, этого там не оказалось, ваша программа не нашла, чего искала, и упала. Потому файлы надо закрывать.
Дело в том, что операции чтения/записи с жесткого диска не являются самыми быстрыми в мире. Потому система предпочитает записывать на жесткий диск не каждый раз, когда вы указали ей это сделать, а ждать, пока не наберется достаточно большой кусок данных. Потому в незакрытый файл вполне возможно запись произведена до конца работы программы и не будет.
Если программа в середине работы упадет, то тем более никто не обещает, что в выходной файл запишется вся информация, которую программа всё же успела обработать.
Более того, часто в биоинформатике вам приходится писать программы, работающие долгое время, возможно, отвечая на тысячи задач. Если так случится, что вы забываете на каждый запрос закрыть файл, то в какой-то момент вы не сможете открыть новый файл и ваша программа завершится аварийно. По-умному такая ситуация называется "утечка файловых дескрипторов".
Демонстрация того, что будет, если открыть слишком много файлов (допустим, на запись, но это верно и для чтения):
# не запускайте этот код, если не готовы перезагружать тетрадь
opened_files = []
for i in range(1, 10000):
fl = open(str(i), "w")
opened_files.append(fl)
К сожалению, в IPython Notebook мы просто зависнем, однако в консоли, где мы его открыли (она и на Windows появляется), вылетит исключение zmq.error.ZMQError: Too many open files.
Для более наглядного поведения можете запустить скрипт с подобным кодом. Заметьте, что даже открытие одного и того же файла на чтение, но много раз, приводит к проблемам, т.к система позволяет иметь файл открытым множество раз.
scr = '''
opened_files = []
for i in range(1, 10000):
fl = open('Python_basics_Lecture3.ipynb', "r")
opened_files.append(fl)
''' # another way to define multiline strings in Python
with open('script.py', 'w') as outfile:
outfile.write(scr)
outfile
Запуск команды в jupyter, как в командной строке - для этого просто в начале клетки ставите восклицательный знак
!python script.py
Теперь посмотрим на то, что будет, если мы пишем в файл, но не смогли его закрыть (забыли или случилось исключение)
fl = open('example.txt', "w")
for i in range(1000, -1000, -1):
1 / i
fl.write(str(i) + "\n")
fl.close()
Открываем этот же файл на чтение
fl1 = open('example.txt', 'r')
И в нем ничего нет:)
fl1.readline() # no info....
Теперь закроем файл (на запись)
fl.close()
Информация появилась
fl1.readline()
Функции¶
Функция - фрагмент программного кода, к которому можно обратиться из другого места программы
В Python функции задаются ключевым словом def.
def say_hello():
print ("Hello")
say_hello()
def mod(a, b):
return a % b
print (mod(3,4))
def wrong_mod(a, b):
a % b
print (wrong_mod(3,4))
Функция может возвращать несколько значений, в этом случае она вернет их в качестве кортежа.
def s_pats(string, pats):
ind = -1
for p in pats:
ind = string.find(p)
if ind != -1:
break
return ind, p
res = s_pats("Hello, world", ["Hell", "world",
"happiness"])
print (type(res))
ind, p = res
print(ind, p)
Пример функции, реализующей факториал и вычисление n-го числа Фибоначчи
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
print (factorial(5))
print (fibonacci(5))
Рекурсия¶
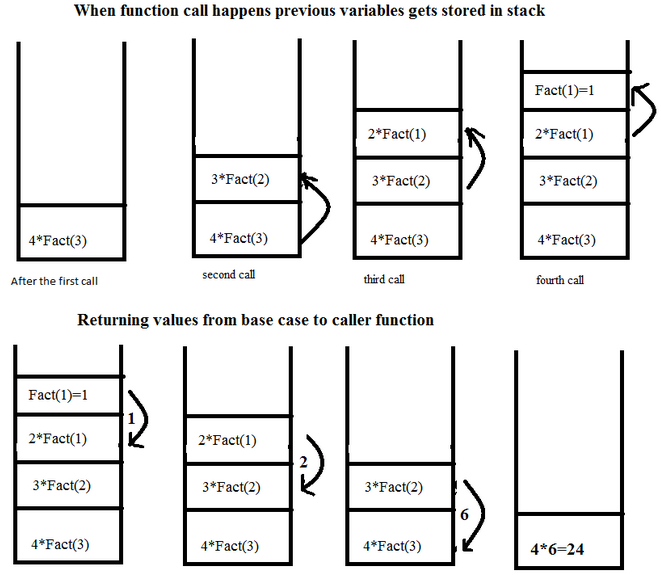
Python поддерживает механизм рекурсии - вызов функцией самой себя. Перепишем, например, предыдущие функции в рекурсивной форме
def factorial_rec(n):
if n <= 1:
return 1
return n * factorial_rec(n - 1)
def fibonacci_rec(n):
if n < 0:
return 0
if n == 0:
return 0
if n == 1:
return 1
return fibonacci_rec(n - 1) + fibonacci_rec(n - 2)
print (factorial_rec(5))
print (fibonacci_rec(5))
Как это работает. Знать не обязательно, но может помочь пониманию рекурсии. Вначале при вызове рекурсии мы приостанавливаем выполнение текущей функции (так как пока не можем ее вычислить) и запускаем новую функцию с переданными ей параметрами. Так происходит несколько раз, пока на каком-то этапе мы не можем вычислить значение без обращения к рекурсии. Мы его вычисляем и возвращаем в приостановленную последней функцию. И так далее.
Замедление из-за использования рекурсии¶
Здесь это объясняется тем, что рекурсия - допронительные расходы для приостановки работы функции и возвращении в нее после.
%%timeit
factorial(1000)
%%timeit
factorial_rec(1000)
Здесь же все еще хуже
%%timeit
fibonacci(20)
%%timeit
fibonacci_rec(20)
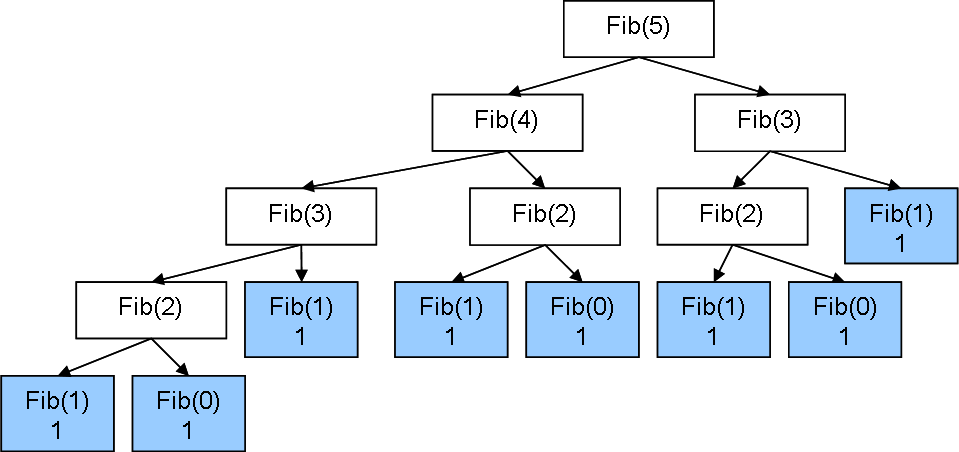
У fibonacci сразу две проблемы - то, что есть необходимость приостановки функций, и то, что мы повторяем многие вычисления множество раз. Например, вычисление второго числа Фибоначчи на картинке будет осуществлено 3 раза.
С этим можно бороться, но это не тема этой лекции
Бесконечная рекурсия¶
Если забыть про условие выхода из рекурсии (когда мы можем посчитать значение без обращения к ней), то получаем классическую ошибку
def factorial_rec_no_exit(n):
return n * factorial_rec_no_exit(n - 1)
factorial_rec_no_exit(10) # good night, sweet prince
Аргументы по-умолчанию¶
Достаточно часто встречается ситуация, когда большинство предпочтительных аргументов для функции известно (например, вы знаете, что ваш алгоритм лучше всего запускать с lambda = 0.73, а n_samples = 143). В таком случае, конечно, можно написать в комментариях к своей функции, но лучше воспользоваться аргументами по-умолчанию.
import random
def make_random_sequence(length=200,
alphabet="ATGC"):
seq_lst = []
for i in range(length):
seq_lst.append(random.choice(alphabet))
seq = "".join(seq_lst)
return seq
make_random_sequence()
make_random_sequence(length=100)
make_random_sequence(alphabet="AUGC", length=100)
Также часто вы просто хотите задать поведение функции по-умолчанию/наиболее частое поведение.
def login(username="anonymous", password=None):
"""Some action"""
pass
# we can call function in different ways
login("root", "ujdyzysqgfhjkm")
login("guest")
login()
# Also you can specify the name of argument
login(password="nobody@mail.com")
Можно комбинировать обязательный аргументы с аргументами, заданными по умолчанию. При этом обязательные должны идти первыми.
def write_random_fasta(out_file_path,
name="random",
length=200,
alphabet="ATGC"):
out_file = open(out_file_path, "w") # it is better to use with-construction here
seq = make_random_sequence(length=length, alphabet=alphabet)
out_file.write(">{}\n".format(name))
out_file.write("{}\n".format(seq))
out_file.close()
write_random_fasta("random.fasta")
write_random_fasta()
write_random_fasta("random2.fasta", length=10)
def add_to_list(el, lst = []):
lst.append(el)
return lst
print (add_to_list(5, [1,2,3])) # OK
print (add_to_list(5, [])) # OK
print (add_to_list(5)) # OK
print (add_to_list(5)) # WHAT???

Дело в том, что значение по-умолчанию создавалось один раз. И вначала оно равно пустому списку. Но в третьем случае мы добавляем в этот список элемент. И после возвращения из функции изменения не пропадают. Потому на следующем вызове элемент добавляется не к пустому списку, а к списку, содержащему один элемент. И так далее. Как это лечить? - не использовать в значениях по-умолчанию изменяемые объекты (списки, словари и т.д), а использовать None
def add_to_list_wsmf(el, lst = None):
if lst == None:
lst = []
lst.append(el)
return lst
print (add_to_list_wsmf(5, [1,2,3])) # OK
print (add_to_list_wsmf(5, [])) # OK
print (add_to_list_wsmf(5)) # OK
print (add_to_list_wsmf(5)) # Still OK
Форматирование строк¶
Конкатенация¶
Грубый, но самый простой способ форматирования, в котором мы просто склеиваем несколько строк с помощью операции сложения:
name = "Дмитрий"
age = 25
print("Меня зовут " + name + ". Мне " + str(age) + " лет.")
%-форматирование¶
Ранее самый популярный способ, который перешел в Python из языка С. Передавать значения в строку можно через кортежи
print("Меня зовут %s. Мне %d лет." % (name, age))
Можно также передавать значения с помощью словаря. В этом случае значения помещаются не по позиции, а в соответствии с именами.
print("Меня зовут %(name)s. Мне %(age)d лет." % {"name": name, "age": age})
Форматирование с помощью метода format()¶
Этот способ появился в качестве замены %-форматированию. Он также поддерживает передачу значений по позиции и по имени.
print("Меня зовут {}. Мне {} лет.".format(name,
age))
Можно явно указывать позицию аргумента, который здесь надо вставить.
print("Меня зовут {0}. Мне {1} лет.".format(name,
age))
Можно использовать один и тот же аргумент несколько раз
print("Меня зовут {0}. Точно ли меня зовут {0}... Кажется, меня все же зовут {0}".format(name))
f-strings¶
f-строки. Форматирование, которое появилось в Python 3.6 (PEP 498). Этот способ похож на форматирование с помощью метода format(), но гибче, читабельней и быстрей.
f-строки делают очень простую вещь — они берут значения переменных, которые есть в текущей области видимости, и подставляют их в строку. В самой строке вам лишь нужно указать имя этой переменной в фигурных скобках.
name = "Алексей"
age = 35
print(f"Меня зовут {name}. Мне {age} лет.")
Их и рассмотрим подробнее (часть из их функционала есть и в других методах, тем не менее)
f-строки также поддерживают расширенное форматирование чисел. Это удобно, например, когда мы хотим вывести число с заданной точностью
from math import pi
print(f"Значение числа pi: {pi:.02f}")
Они поддерживают базовые арифметические операции
x = 10
y = 5
print(f"{x} x {y} / 2 = {x * y / 2}")
Индексацию списков:
planets = ["Меркурий", "Венера", "Земля", "Марс"]
print(f"Мы живем на планете {planets[2]}")
А также к элементам словаря по ключу:
planet_radius = {"Земля": 6378000}
planet = "Земля"
print(f"Планета {planet}. Радиус {planet_radius[planet]/1000} км.")
Заметьте, что при обращении к словарю по ключу мы можем использовать переменные тоже) Можно и строки, конечно
planet_radius = {"Земля": 6378000}
print(f"Планета Земля. Радиус {planet_radius['Земля']/1000} км.")
Вы можете вызывать в f-строках методы объектов:
replic1 = "Вот они - смертные"
replic2 = "Все, что у них есть, - это совсем немного лет в этом мире. И они проводят драгоценные годы жизни за усложнением всего, к чему прикасаются. Очаровательно."
print(f"{replic1.upper()}, - продолжал Смерть. - {replic2.upper()}")
Модули¶
Чужие модули¶
Вы уже встречались с модулями в Python.
Импорт всего модуля - теперь можно использовать все, что в нем определено, но с указанием имени этого модуля
import random
random.randint(0, 100) # получить случайное число от 0 до 100 включительно
Можно импортировать только нужную нам функцию
from random import choice
choice("ATGC") # выбрать случайную букву
import random as rnd # импортировать модуль и использовать в программе для него другое имя
rnd.random() # получить случайно число от 0 до 1
Cвои модули¶
Вы можете написать модуль и сами. На самом деле, любой файл Python может использоваться как модуль
Допустим, мы написали код и хотим его использовать как модуль
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
Самим так, как я сейчас (и немного ранее), писать в файл .py чаще всего не надо, можно просто сразу писать в файле .py, но так можно добиться автономности данной лекции
our_code = '''
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
'''
with open("fibfact.py", "w") as outfile:
outfile.write(our_code)
Теперь мы можем это использовать:
import fibfact
fibfact.factorial(5)
Можем мы и использовать from
from fibfact import factorial
factorial(5)
Можем и назначить модулю имя
import fibfact as fct
fct.fibonacci(5)
Небольшая проблема появляется в тот момент, когда мы хотим использовать файл и как модуль, и как скрипт
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
print (factorial(5))
print (fibonacci(10))
our_code = '''
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
print (factorial(5))
print (fibonacci(10))
'''
with open("fibfact.py", "w") as outfile:
outfile.write(our_code)
Если мы меняем модуль, а где-то он загружен, мы должны его перезагрузить (можете сами найти, как это делать), либо перезагрузить notebook (на верхней панели: Kernel->Restart)
import fibfact
То есть при импорте модуля этот код выполняется. Это нехорошо, т.к засоряет исполнение, кроме того, может привести к ошибкам при импорте модуля, например:
# Полученный скрипт будет принимать два аргумента из командной строки и для первого вычислять значение факториала,
# а для второго - соответствующее число Фибоначчи
our_code = '''
import sys
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
print (factorial(int(sys.argv[1])))
print (fibonacci(int(sys.argv[2])))
'''
with open("fibfact.py", "w") as outfile:
outfile.write(our_code)
Надо перезагрузить notebook
Получаем ошибку, т.к sys.argv берется из jupyter-notebook. В общем сложно и неправильно все.
import fibfact
import sys
print (f"{sys.argv[1]}, {sys.argv[2]}") # вот эти аргументы он использовал..
Для того, чтобы предотвратить ситуацию существует специальный механизм, основанный на переменной, видимой только в данном файле - __name__
Если наш файл запустили, как скрипт, то его имя - "__main__".
Если его использовали как модуль, то его имя - не "__main__", этого достаточно:)
# Как выглядит код с подсветкой, запускать это не надо
import sys
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
print(f"My name is {__name__}")
if __name__ == "__main__":
print (factorial(sys.argv[1]))
print (fibonacci(sys.argv[2]))
# Полученный файл при вызове как скрипт будет принимать два аргумента из командной строки и для первого вычислять значение факториала,
# а для второго - соответствующее число Фибоначчи. Кроме того, он напечатает свое имя.
# При импортировании в качестве модуля - только напечатает свое имя
our_code = '''
import sys
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
print(f"My name is {__name__}")
if __name__ == "__main__":
print (factorial(int(sys.argv[1])))
print (fibonacci(int(sys.argv[2])))
'''
with open("fibfact.py", "w") as outfile:
outfile.write(our_code)
Надо перезагрузить notebook
Для импорта в качестве модуля работает
import fibfact
Работает и при запуске как самостоятельный скрипт
! python fibfact.py 5 5
Исключения¶
В работе с Python мы часто сталкивались с ситуациями, в которых мы получали ошибки - исключения. Необработанное приходит к завершению Python-программы
В Python существует специальный механизм для отлова исключений - try: ... except: ...
1 / 0
try:
1 / 0
except ZeroDivisionError:
print ("HI")
Порой нам необходимо отловить несколько исключений. В этом случае просто пишем несколько блоков except
int("1.1")
a = input()
b = input()
try:
a = int(a) # possible error
b = int(b) # possible error
print (a / b)
except ValueError:
print ("a and b must be integers")
except ZeroDivisionError:
print ("b must be different from 0")
Дополнительно про исключения¶
Так же может возникнуть ситуация, когда мы хотим отлавливать исключения, которые являются подтипами друг друга. В этом случае необходимо указывать наиболее частое исключение первым.
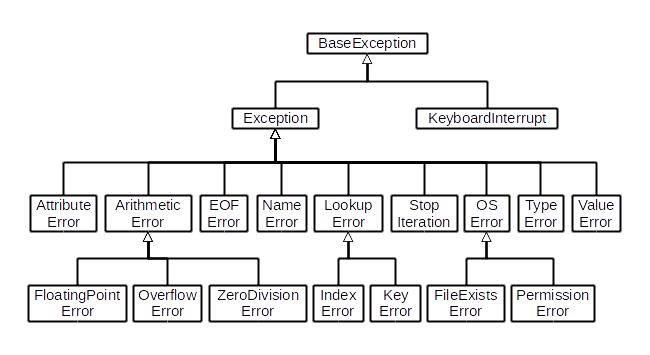
Так не будет работать так, как хотим
a = input()
b = input()
try:
a = int(a) # possible error
b = int(b) # possible error
print (a / b)
print (a[0])
except Exception: # Exception usually is the most general Exception, it's highly recommended not to use more general exceptions
print ("Other exception")
except ValueError:
print ("a and b must be integers")
except ZeroDivisionError:
print ("b must be different from 0")
А это уже правильная последовательность
a = input()
b = input()
try:
a = int(a) # possible error
b = int(b) # possible error
print (a / b)
print (a[0])
except ValueError:
print ("a and b must be integers")
except ZeroDivisionError:
print ("b must be different from 0")
except Exception: # Exception usually is the most general Exception, it's highly recommended not to use more general exceptions
print ("Other exception")
А что делать, если мы хотим что-то сделать только если исключения не произошло? Так не работает:
a = input()
b = input()
try:
a = int(a) # possible error
b = int(b) # possible error
result = a / b
except ValueError:
print ("a and b must be integers")
except ZeroDivisionError:
print ("b must be different from 0")
except Exception: # Exception usually is the most general Exception, it's highly recommended not to use more general exceptions
print ("Other exception")
print (result)
Существуют еще ветвь else в try except, которая выполняется только если исключения не произошло
a = input()
b = input()
try:
a = int(a) # possible error
b = int(b) # possible error
result = a / b
except ValueError:
print ("a and b must be integers")
except ZeroDivisionError:
print ("b must be different from 0")
except Exception: # Exception usually is the most general Exception, it's highly recommended not to use more general exceptions
print ("Other exception")
else:
print (result)
И последним словом, которое можно использовать в try.. except является finally - оно говорит совершать что-то в любом случае, даже если мы не обработали какую-то ошибку и прекращаем работу
a = input()
b = input()
try:
a = int(a) # possible error
b = int(b) # possible error
result = a / b
print(result[0])
except ValueError:
print ("a and b must be integers")
except ZeroDivisionError:
print ("b must be different from 0")
else:
print (result)
finally:
print ("Hi")
Обычно в finally освобождаются ресурсы, которые мы брали в блоке try и хотим несмотря ни на что освободить (ресурсами, например, являются файлы). Например, если бы мы не имели блока with для файла, то вынуждать его к закрытию пришлось бы следующим образом
a = input()
b = input()
try:
fl = open("infile.txt", "w")
a = int(a) # possible error
b = int(b) # possible error
result = a / b
fl.write(f"{result}\n")
except ValueError:
print ("a and b must be integers")
except ZeroDivisionError:
print ("b must be different from 0")
else:
print (result)
finally:
print("Closing file")
fl.close()