Вспоминаем Python!¶
Часть 4¶
Работа с файлами¶
Файлы¶
Работа с файлами -- неотделимая часть жизни биоинформатика. До 90% работы среднестатистического биоинформатика уходит на парсинг файлов и их конвертацию между форматами.
Что такое файл?
Файл - это данные, которые хранятся на некотором носителе, например, на жестком диске.
Чтение из файла¶
Как открыть файл для чтения?
Команда open(filename, "r") открывает ваш файл для чтения.
myfile = open('spring1.txt', "r")
myfile = open('spring1.txt', "r")
Объект myfile имеет интересный тип (название его мало о чем говорит, достаточно понимать, что такой тип объектов позволяет читать из себя данные).
type(myfile)
Как прочитать весь файл?
Можно прочитать весь файл разом методом .read
print(myfile.read())
Что необходимо сделать после работы с файлом?
Открытый файл после окончания работы НАДО закрыть командной close
myfile.close()
Как ещё можно читать из файла?
Из файла также можно читать построчно:
myfile2 = open("spring2.txt", "r")
print(myfile2.readline())
print(myfile2.readline())
myfile2.close()
Заметим, что прочитанная строка возвращается с \n на конце.¶
Как можно убрать \n в конце строки?
Метод .strip строки поможет нам!
myfile2 = open("spring2.txt", "r")
print(myfile2.readline().strip())
print(myfile2.readline().strip())
А что произойдёт, если прочитать строку после того, как мы дошли до конца файла?

Ответ:¶
Когда файл дочитан до конца, метод .readline возвращает пустую строку (без \n на конце)
print("Returning empty string : |", myfile2.readline(), "|", sep="")
myfile2.close()
Казалось бы, можно организовать чтение всего файла следующим образом:
myfile3 = open("spring3.txt", "r")
line = myfile3.readline()
while line != "":
print(line.strip())
line = myfile3.readline() #!
myfile3.close()
Почему не используем .strip сразу в строке, помеченной #!?
Однако в Python есть механизм, который помогает упростить код, написанный выше.
Для чтения файла можно использовать цикл for.
Если же нужно обработать все строки из файла одинаковым способом, то этот будет наиболее предпочтителен - он не только компактнее и соответствует стилю Python, но еще и работает быстрее.
myfile4 = open("spring4.txt", "r")
for line in myfile4:
print(line.strip())
myfile4.close()
Как можно догадаться, итерация идет по строкам!
Важно¶
Пройдя по файлу один раз, вы попадаете в конец файла.
Это означает, что вы не сможете пройтись по нему еще раз!
tabular = open("tab.txt", "r")
for line in tabular:
print(line.strip())
for line in tabular: #won't be executed
print("WOW!", line.strip())
tabular.close()
Аналогично, если из файла уже что-то читалось - второй раз оно прочитано не будет
infile = open("tab.txt", "r")
print("\t\tReading the first line")
print(infile.readline().strip())
print("\t\tReading by 'for' cycle")
for line in infile:
print(line.strip())
infile.close()
Что с этим поделать?
Можно переместиться в начало файла с помощью метода .seek.
infile = open("tab.txt", "r")
for line in infile:
print(line.strip())
print("\nReading file from the beginning\n")
infile.seek(0)
for line in infile:
print(line.strip())
infile.close()
Запись в файл¶
Как открыть файл на запись?
Открытие файла на запись - open(filename, "w") (эта команда создает новый пустой файл)
Запись в файл осуществляется методом .write
munch = open("Munchhausen.txt", "w")
phrase = """В свое время Сократ мне сказал:
"Женись непременно.
Попадется хорошая жена — станешь счастливым.
Плохая — станешь философом."
Не знаю, что лучше\n"""
munch.write(phrase)
munch.close()
Обратите внимание: метод .write не добавляет \n в конце строки!
Вам нужно добавлять перенос строки самостоятельно :^)
Проверим нашу запись:
munch = open("Munchhausen.txt", "r")
print(munch.read())
munch.close()
Можно также записать информацию в конец уже существующего файла, открыв его в режиме "a" - от "append".
f = open("Munchhausen.txt", "a")
s = """После свадьбы мы сразу уехали в свадебное путешествие.
Я в Турцию, жена в Швейцарию,
и прожили там три года в любви и согласии.\n"""
f.write("\n")
f.write(s)
f.write("@Тот самый Мюнхгаузен\n")
f.close()
f = open("Munchhausen.txt", 'r')
print(f.read())
f.close()
Почему важно закрывать файлы?¶
Все открытые файлы автоматически закрываются, когда программа заканчивает работу.
И потому все будет прекрасно работать, пока вы не решите создавать в своей программе промежуточные файлы, информация из которых затем используется в ней же.
cat = "cat.txt"
catfile = open(cat, "w")
catfile.write("Hello, ")
catfile.write("world\n")
catread = open(cat, "r")
print(catread.read())
Внезапно! Вы что-то записали в файл, не закрыв его, а этого там не оказалось => ваша программа не нашла то, что искала, и упала.
Почему так?
Дело в том, что операции чтения/записи с жесткого диска не являются самыми быстрыми в мире. Потому система предпочитает записывать на жесткий диск не каждый раз, когда вы указали ей это сделать, а ждать, пока не наберется достаточно большой кусок данных. Потому в незакрытый файл вполне возможно запись произведена до конца работы программы и не будет.
А вот если его все же закрыть, то:
catfile.close()
print(catread.read())
catread.close()
Более того, время от времени [даже] в биоинформатике вам приходится писать программы, работающие долгое время, возможно, отвечающие на тысячи задач.
Если вы забываете закрывать файлы, открытые разными запросами, то в какой-то момент вы просто не сможете открыть новый файл и ваша программа завершится аварийно.
По-умному такая ситуация называется "утечка файловых дескрипторов".
Демонстрация того, что будет, если открыть слишком много файлов (это верно как для чтения, так и для записи):
opened_files = []
for i in range(1, 10000):
fl = open(str(i), "w")
opened_files.append(fl)
К счастью, разработчики Python не дураки :^)
Существует способ автоматически закрывать файл, даже если в процессе у вас возникли ошибки, - о нем мы поговорим чуть позже.
Исключения¶
В работе с Python мы часто сталкивались с исключительными ситуациями, в которых мы получали ошибки - исключения. Необработанное исключение приходит к завершению Python-программы
Пример хорошей обработки исключений
Медведь убежал из зоопарка, не могут найти.
Наконец звонит бабуля:
— Ой, ко мне во двор медведь забрался и на дерево залез! Уберите его, мне страшно!
Приезжает мужик с маленькой собачкой, даёт бабуле ружье, показывает на собачку и говорит:
— Бабуля, это Кефирчик. Я сейчас залезу наверх, встряхну ветку, медведь свалится, Кефирчик схватит его за ляжку и потащит в зоопарк.
— Хорошо, сынок. А зачем же мне ружье?
— Если вместо медведя свалюсь я, стреляй в Кефирчика!
Супер. А как ловить исключения?
В Python существует специальный механизм для отлова исключений:
try:
pass
except:
pass
1 / 0
try:
1 / 0
except ZeroDivisionError:
print("Surprise, ьщерукагслук")
Порой нам необходимо отловить несколько исключений. В этом случае просто пишем несколько блоков except
a = 10
b = 5
try:
a = int(a) # probable error
b = int(b) # probable error
print(a / b) # probable error
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
Порой нам необходимо отловить несколько исключений. В этом случае просто пишем несколько блоков except
a = "1"
b = "6"
try:
a = int(a) # probable error
b = int(b) # probable error
print(a / b) # probable error
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
Порой нам необходимо отловить несколько исключений. В этом случае просто пишем несколько блоков except
a = "MCMXXCIV"
b = "MCDLXXXVIII"
try:
a = int(a) # probable error
b = int(b) # probable error
print(a / b) # probable error
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
Порой нам необходимо отловить несколько исключений. В этом случае просто пишем несколько блоков except
a = 2
b = 0
try:
a = int(a) # probable error
b = int(b) # probable error
print(a / b) # probable error
except ValueError:
print ("a and b must be integers")
except ZeroDivisionError:
print ("b must be different from 0")
Может возникнуть ситуация, когда мы хотим отлавливать исключения, которые являются подтипами друг друга. В этом случае необходимо указывать наиболее частное исключение первым.
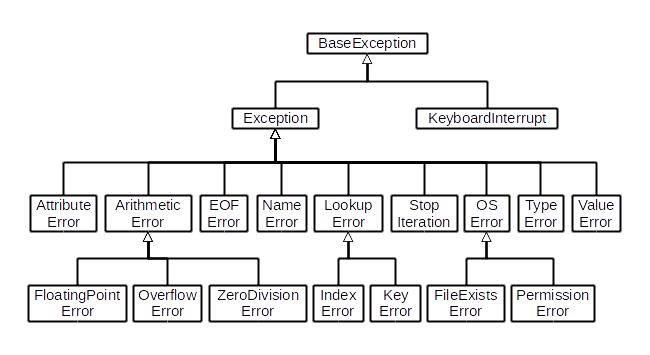
Такой код не будет работать так, как мы хотим:
a = 12
b = 0
try:
a = int(a) # probable error
b = int(b) # probable error
print(a / b) # probable error
print(a[0]) # probable error
except Exception:
print("Other exception")
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
В каких условиях и почему код не будет работать корректно?
Теперь код работает верно!
a = 12
b = 0
try:
a = int(a) # probable error
b = int(b) # probable error
print(a / b) # probable error
print(a[0]) # probable error
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
except Exception:
print("Other exception")
Нечасто используемые особенности¶
Как описать ситуацию, когда мы хотим что-то сделать только в случае, если исключения не произошло?
a = 23
b = 0
try:
a = int(a) # probable error
b = int(b) # probable error
result = a / b # probable error
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
except Exception:
print("Other exception")
print(result)
else¶
Существуют еще ветвь else в try/except, которая выполняется только в том случае, если исключения не произошло.
a = 14
b = 0
try:
a = int(a) # probable error
b = int(b) # probable error
result = a / b # probable error
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
except Exception:
print("Other exception")
else:
print(result)
finally¶
И последним оператором, который можно использовать в try/except, является finally.
Под ним перечисляются действия, которые должны быть совершены в любом случае, даже если мы не обрабатывали ошибки!
a = "XVII"
b = "LXI"
try:
a = int(a) # probable error
b = int(b) # probable error
result = a / b # probable error
print(result[0]) # probable error
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
else:
print(result)
finally:
print("...Well, at least we got there...")
Обычно в finally освобождаются ресурсы, которые мы брали в блоке try и хотим несмотря ни на что освободить. Например, если бы мы не имели блока with для файла, то вынуждать его к закрытию пришлось бы следующим образом:
a = 10
b = 0
try:
fl = open("outfile.txt", "w")
a = int(a) # probable error
b = int(b) # probable error
result = a / b # probable error
fl.write(f"{result}\n")
except ValueError:
print("a and b must be integers")
except ZeroDivisionError:
print("b must be different from 0")
else:
print(result)
finally:
print("Closing file")
fl.close()
with (менеджер контекста)¶
Казалось бы, почему реже используется последняя конструкция?
Ведь нам удобно иметь возможность закрыть открытый файл, даже если в нашем коде работы с ним произошла ошибка.
На самом деле, в Python есть специальная конструкция для этого - with
Эта конструкция использует finally.
in_file = open("spring5.txt", "r")
try:
print(in_file.read())
a = 5 / 0
finally:
in_file.close()
print(in_file.closed)
with open("spring5.txt", "r") as in_file2:
print(in_file2.read())
a = 5 / 0
print(in_file2.closed)
assert¶
assert позволяет проверить условие и вызвать ошибку, если условие не выполняется:
assert 10 == 10
assert 10 == 2
v1 = 10
v2 = 0
assert v2 != 0, 'You passed wrong denominator'
Многие используют assert при поиске ошибок в своей программе, что (вообще-то говоря) неверно, но всех это не очень задевает
Некоторые часто используемые файловые форматы¶
В работе с данными удобно использовать информацию, записанную в таблицы.
Чаще всего используется .csv -- Comma-Separated Values и .tsv -- Tab Separated Values форматы.
https://docs.python.org/3.4/library/csv.html

import csv
petal_widths = []
with open('example.csv') as csvfile:
iris_dataset = csv.reader(csvfile)
header = next(iris_dataset)
for row in iris_dataset:
petal_w = float(row[2])
petal_widths.append(petal_w)
print(sum(petal_widths) / len(petal_widths))
JSON [read: jeyson]¶
(JavaScript Object Notation, see https://www.json.org/ )
Создадим словарь и запишем его в json-файл:
d = {"name": "John", "age": 20, "os": "linux"}
import json
with open('example.json', 'w') as f:
json.dump(d, f)
%%bash
less example.json
Теперь прочтём данные из другого файла!
with open('complex.json', 'r') as f:
d = json.load(f)
d
d = json.load(open('complex.json', 'r'))
json.loads(open('example.json').read())
Формат имеет достаточно жесткий синтаксис:
json.loads(open('example.json').read() + ']')
pickle¶
Бинарные файлы меньше текстовых, их быстрее считывать и проще хранить.
import pickle
d = {"name": "John", "age": 20, "os": "linux"}
with open("example.pickle", "wb") as pickle_out:
pickle.dump(d, pickle_out)
with open("example.pickle", "rb") as pickle_in:
d2 = pickle.load(pickle_in)
d2
Чтение из сети.¶
Больше информации: https://docs.python.org/3/howto/urllib2.html
import urllib.request
with urllib.request.urlopen('http://python.org/') as response:
html = response.read()
with urllib.request.urlopen('http://humanstxt.org/humans.txt') as response:
txt = response.readlines()
txt[:5]
print(txt[2])
print(txt[2].decode())
Что делать при работе с неизвестным типом файла?¶
Есть расширение? Да (.bed, .fa, .pdb) -> Google: bed/fa/pdb/... format specification
Расширения нет. Читается ли файл как текстовый? Да -> Ищем информацию о формате или намеки в заголовке.
Файл не читается как текстовый. Despair.
Если формат всё-таки определен, не стоит сразу же бросаться писать его парсер, этот велосипед может быть уже избретен. Иногда удобнее конвертировать в другой формат и уже его читать.
Спецификации файлов, часто используемых для геномных данных: https://genome.ucsc.edu/FAQ/FAQformat.html Иногда спецификация хорошо описана на Википедии (https://en.wikipedia.org/wiki/Protein_Data_Bank_(file_format) ), но предпочтение стоит отдавать описанию формата от самих авторов.

Полезные модули для работы с файловой системой¶
glob и os являются незаменимыми для работы с файловой системой через Python.
glob.glob позволяет осуществлять поиск файлов по маске:
import glob
glob.glob('*.txt')
Модуль os позволяет работать с файловой системой одинаково, вне зависимости от платформы (Windows, Linux и т.д.)
import os
os.path.isfile('dummy_text.txt')
os.path.isdir('dummy_text.txt')
os.mkdir('tmp/')
Полезный способ правильно собрать путь по частям.
Способ не зависит от того, как пользователь ввел имя директории (с / или без), например.
os.path.join("Vasya", "hw72", "exercise89")
os.path.join("Vasya/", "hw72/", "exercise89")
os.path.join("Vasya/", "hw72", "exercise89")
Ну вот и всё!¶
