Коллекции¶
Коллекции - это какие-то наборы объектов разного или одного типа. 100 кошек, 10 собак, набор - [арбуз, тыква, голый землекоп], - все это является коллекцией.
В Python существует несколько разных типов, которые помогают вам хранить коллекции объектов в удобном для вас виде. Одним из базовых является список
Словари¶
Часто перед нами встает задача по какому-то, нечисленному, значению, найти соответствующее ему другое значение. Например, по ФИО человека номер его паспорта
Словарь (dict) – это тип данных, хранящий соответствие одних значений другим (ключам словаря). Самым простым способом создания словаря является задание его при помощи фигурных скобок ({})
my_dict = { "Dmitry" : 5,
"Alexander" : 10,
"Jupyter": 20}
my_dict
Соответственно, чтобы получить значение, соответствующее ключу, необходимо набрать имя словаря и ключ в квадратных скобках.
my_dict['Jupyter']
В случае, если ключа с таким значением нет, получите ошибку:
my_dict['Dogs']
Можно использовать метод dict.get(key, default_value=None) для того, чтобы в случае отсутствия ключа в словаре получать какое-то значение по-умолчанию
print (my_dict.get("Dogs")) # return None
my_dict.get("Dogs", 5)
my_dict.get("Jupyter", 5)
Проверка наличия ключа в словаре¶
Как и для других коллекций, для проверки наличия ключа в словаре используется слово in
if "Dogs" in my_dict:
print("Hello")
else:
print("World")
Проход по ключам словаря¶
Проход по ключам словаря можно сделать двумя способами
Учтите, что методы словаря, "возвращающие" хранимое в нем, возвращают не-совсем-списки, с этим нельзя работать как со списком
my_dict.keys()
for key in my_dict.keys():
print (key)
for key in my_dict:
print (key)
Проход по значениям словаря¶
my_dict.values()
for value in my_dict.values():
print (value)
Проход по ключам и значениям словаря
for key in my_dict.keys():
value = my_dict[key]
print (key, value)
my_dict.items()
for key, value in my_dict.items():
print (key, value)
list(my_dict.keys())
list(my_dict.values())
list(my_dict.items())
Добавление элементов в словарь¶
Словарь может хранить любой объект в качестве значения, однако в качестве ключа ему необходимы особые объекты, в первом приближении неизменяемые - числа и строки, например.
d = dict() # another way to create dict
# d = {}
d[10] = "Hello"
d
d["hello"] = "world"
d
d[10] = -100
d
my_key = "hi"
my_value = [1,2,3]
d[my_key] = my_value
d
d[[1,2,3]] = 5
# error, list is mutable (unhashable, to be precise)
Удаление элементов из словаря¶
a = {"A" : 0,
"T" : 1,
"G": 2,
"C" : 3,
"G" : 4,
"U" : 5}
a
del a['U']
a
del a['U']
Можно использовать метод pop - он правильнее
a = {"A" : 0, "T" : 1, "G": 2, "C" : 3, "G" : 4, "U" : 5}
a.pop('U')
a
a.pop('U')
a.pop('U', None)
А вот так делать нельзя!
a = {"A" : 0,
"T" : 1,
"G": 2,
"C" : 3,
"G" : 4,
"U" : 5}
for key in a.keys():
if key == "C":
a.pop(key)
Можно обойти проблему так:
a = {"A" : 0, "TC" : 1,
"G": 2, "CG" : 3,
"GC" : 4, "U" : 5}
keys = list(a.keys())
for key in keys:
if "C" in key:
a.pop(key)
a
Порядок ключей в словаре¶
До версии Python3.5 включительно никто не гарантировал вам никакого порядка ключей в словаре. То есть то, как они вам выдавались функцией keys и т.д не зависело ни от порядка вставки элементов, не от результата их сравнения напрямую.
Однако с версии Python3.6 в наиболее распространненой реализации (CPython), а с версии Python3.7 - в любой, порядок ключей в словаре соответствует порядку их вставки в него. Если ключ уже существовал в словаре и вы его перезаписали, то порядок ключей не изменится.
a = {}
a[2] = 20
a[-10] = 3
a
Преимущества словарей¶
Получение значения по ключу и добавление нового ключа в словарь происходит значительно быстрее, чем если бы вам пришлось перебирать список в поисках нужного значения. Вследствие этого есть огромный набор задач, где словари использовать можно и нужно. Вместе со списками — возможность представить структуру данных любой сложности (дополнительная информация — json).
Недостатки словарей¶
Словари "кушают" много памяти. Все операции на словарях быстры в среднем — отдельная операция может длиться очень долго.
Кортежи¶
Если очень хочется сделать ключом словаря список, то нужно использовать не list, а другой тип данных — кортеж (tuple). Кортеж, на первый взгляд, отличается от списка только заменой квадратных скобок на круглые, например:
ta = (1, 2, 5, 4)
ta[0]
a = (1)
print (a)
a = (1, )
print(a)
Кортеж во многом похож на список, но главным отличием является то, что кортеж неизменяем.
ta[0] = 5
dt = {}
dt[(1, 2)] = "Hello"
dt[(2, 1)] = "world"
dt
dt[(1,2)]
Кроме возможности служить ключом словаря, в случае кортежей, операции доступа (получить элемент кортежа, срез и т.д.) выполняются для кортежа быстрее. Python может оптимизировать работу программы, в которой создается множество кортежей малой длины, что для списков недоступно. С другой стороны, любая операция редактирования кортежа приводит к созданию нового кортежа, что в больших количествах может замедлить работу программы и съесть память вашего компьютера.
urllib.request¶
import urllib.request
handle = urllib.request.urlopen("https://istina.msu.ru/workers/232537526/")
print(handle.readline())
print(handle.readline())
print(handle.readline())
Возвращается строка в бинарном виде. Что с этим делать?
line = handle.readline()
print(line)
Нам хватает того, что это работает.
line.decode()
Функции¶
Функция - фрагмент программного кода, к которому можно обратиться из другого места программы
В Python функции задаются ключевым словом def.
def say_hello():
print ("Hello")
say_hello()
def mod(a, b):
return a % b
print (mod(3,4))
def wrong_mod(a, b):
a % b
print (wrong_mod(3,4))
Функция может возвращать несколько значений, в этом случае она вернет их в качестве кортежа.
def s_pats(string, pats):
ind = -1
for p in pats:
ind = string.find(p)
if ind != -1:
break
return ind, p
res = s_pats("Hello, world", ["Hell", "world",
"happiness"])
print (type(res))
ind, p = res
print(ind, p)
Пример функции, реализующей факториал и вычисление n-го числа Фибоначчи
def factorial(n):
acc = 1
for i in range(2,n + 1):
acc *= i
return acc
def fibonacci(n):
f0, f1 = 0, 1
for i in range(n):
f0, f1 = f1, f0 + f1
# temp = f0
# f0 = f1
# f1 = f1 + temp
return f0
print (factorial(5))
print (fibonacci(5))
Рекурсия¶
Python поддерживает механизм рекурсии - вызов функцией самой себя. Перепишем, например, предыдущие функции в рекурсивной форме
def factorial_rec(n):
if n <= 1:
return 1
return n * factorial_rec(n - 1)
def fibonacci_rec(n):
if n < 0:
return 0
if n == 0:
return 0
if n == 1:
return 1
return fibonacci_rec(n - 1) + fibonacci_rec(n - 2)
print (factorial_rec(5))
print (fibonacci_rec(5))
Как это работает. Знать не обязательно, но может помочь пониманию рекурсии. Вначале при вызове рекурсии мы приостанавливаем выполнение текущей функции (так как пока не можем ее вычислить) и запускаем новую функцию с переданными ей параметрами. Так происходит несколько раз, пока на каком-то этапе мы не можем вычислить значение без обращения к рекурсии. Мы его вычисляем и возвращаем в приостановленную последней функцию. И так далее.
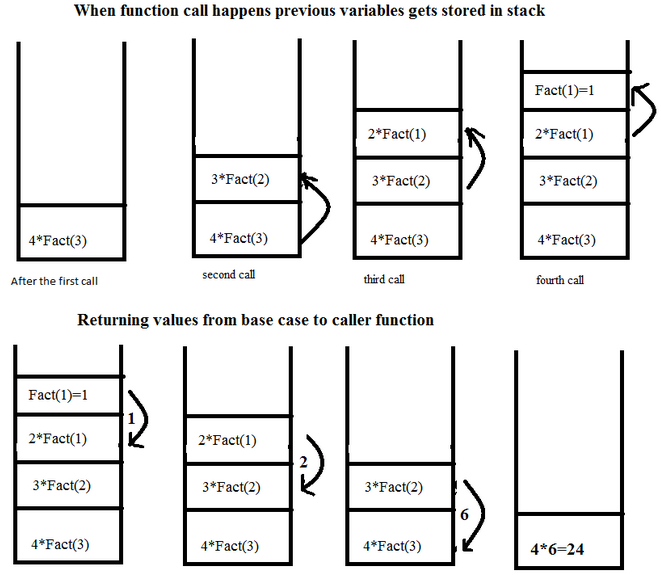
Замедление из-за использования рекурсии¶
Здесь это объясняется тем, что рекурсия - допронительные расходы для приостановки работы функции и возвращении в нее после.
%%timeit
factorial(1000)
%%timeit
factorial_rec(1000)
Здесь же все еще хуже
%%timeit
fibonacci(20)
%%timeit
fibonacci_rec(20)
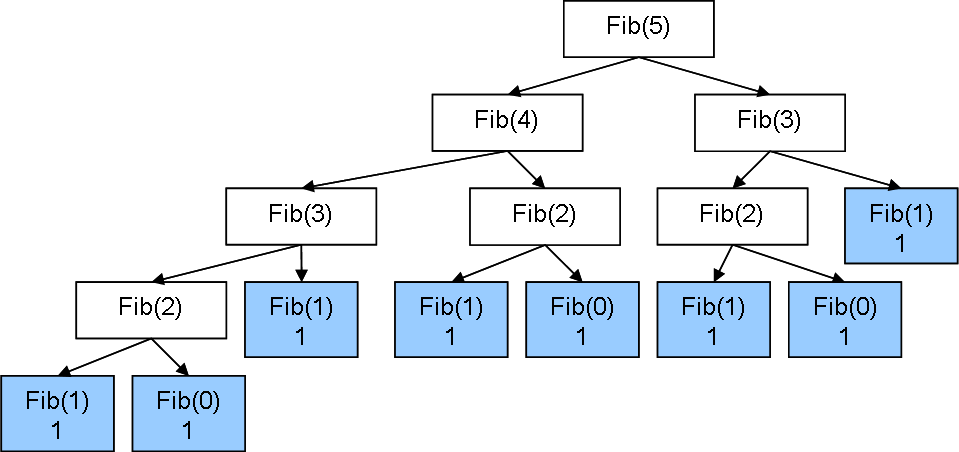
У fibonacci сразу две проблемы - то, что есть необходимость приостановки функций, и то, что мы повторяем многие вычисления множество раз. Например, вычисление второго числа Фибоначчи на картинке будет осуществлено 3 раза.
С этим можно бороться, но это не тема этой лекции
Бесконечная рекурсия¶
Если забыть про условие выхода из рекурсии (когда мы можем посчитать значение без обращения к ней), то получаем классическую ошибку
def factorial_rec_no_exit(n):
return n * factorial_rec_no_exit(n - 1)
factorial_rec_no_exit(10) # good night, sweet prince
Аргументы по-умолчанию¶
Достаточно часто встречается ситуация, когда большинство предпочтительных аргументов для функции известно (например, вы знаете, что ваш алгоритм лучше всего запускать с lambda = 0.73, а n_samples = 143). В таком случае, конечно, можно написать в комментариях к своей функции, но лучше воспользоваться аргументами по-умолчанию.
import random
def make_random_sequence(length=200,
alphabet="ATGC"):
seq_lst = []
for i in range(length):
seq_lst.append(random.choice(alphabet))
seq = "".join(seq_lst)
return seq
make_random_sequence()
make_random_sequence(length=100)
make_random_sequence(alphabet="AUGC", length=100)
Также часто вы просто хотите задать поведение функции по-умолчанию/наиболее частое поведение.
def login(username="anonymous", password=None):
"""Some action"""
pass
# we can call function in different ways
login("root", "ujdyzysqgfhjkm")
login("guest")
login()
# Also you can specify the name of argument
login(password="nobody@mail.com")
Можно комбинировать обязательный аргументы с аргументами, заданными по умолчанию. При этом обязательные должны идти первыми.
def write_random_fasta(out_file_path,
name="random",
length=200,
alphabet="ATGC"):
out_file = open(out_file_path, "w") # it is better to use with-construction here
seq = make_random_sequence(length=length, alphabet=alphabet)
out_file.write(">{}\n".format(name))
out_file.write("{}\n".format(seq))
out_file.close()
write_random_fasta("random.fasta")
write_random_fasta()
write_random_fasta("random2.fasta", length=10)
def add_to_list(el, lst = []):
lst.append(el)
return lst
print (add_to_list(5, [1,2,3])) # OK
print (add_to_list(5, [])) # OK
print (add_to_list(5)) # OK
print (add_to_list(5)) # WHAT???
 )
)
Дело в том, что значение по-умолчанию создавалось один раз. И вначала оно равно пустому списку. Но в третьем случае мы добавляем в этот список элемент. И после возвращения из функции изменения не пропадают. Потому на следующем вызове элемент добавляется не к пустому списку, а к списку, содержащему один элемент. И так далее. Как это лечить? - не использовать в значениях по-умолчанию изменяемые объекты (списки, словари и т.д), а использовать None
def add_to_list_wsmf(el, lst = None):
if lst == None:
lst = []
lst.append(el)
return lst
print (add_to_list_wsmf(5, [1,2,3])) # OK
print (add_to_list_wsmf(5, [])) # OK
print (add_to_list_wsmf(5)) # OK
print (add_to_list_wsmf(5)) # Still OK
Проверку на None правильнее делать так:
def add_to_list_wsmf(el, lst = None):
if lst is None:
lst = []
lst.append(el)
return lst
print (add_to_list_wsmf(5, [1,2,3])) # OK
print (add_to_list_wsmf(5, [])) # OK
print (add_to_list_wsmf(5)) # OK
print (add_to_list_wsmf(5)) # Still OK