| Наша задача: найти гомологов белка в базах данных последовательностей.
Мой белок YP_004659637.1 бактерии Thermotoga Thermarum, последовательность которого можно посмотреть в YP_004659637.1.Запускаем BLASTP на сайте NCBI по базе protein blast, с числом последовательностей равным 20000. Число находок - 13046.
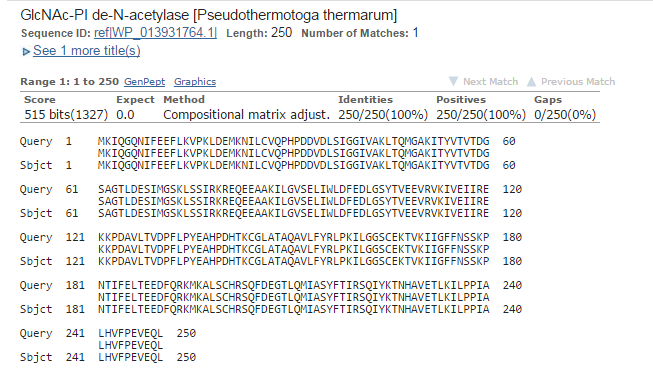 Рис1.Лучшее выравнивание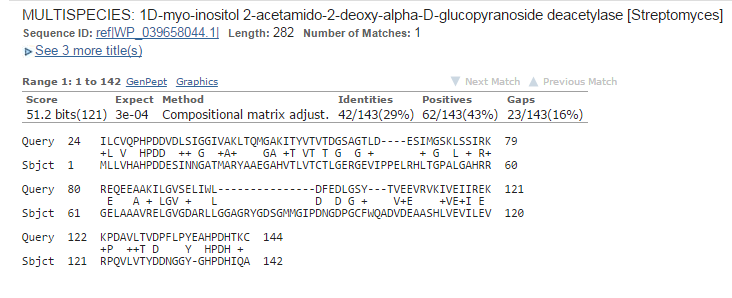 Рис2.Выравнивание из середины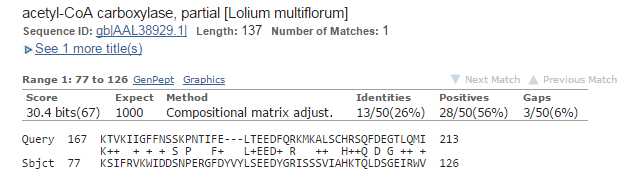 Рис3.Худшее выравнивание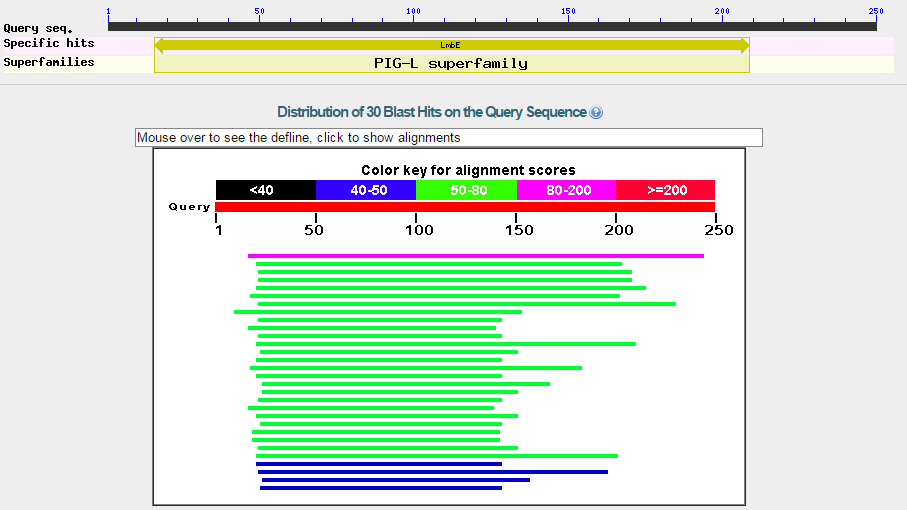 Рис4.Графическое отображение последовательностей с e-value < 1e-04E-value это ожидаемое число находок с таким же и лучшим score выравнивания в случайном банке. Для вычисления величины E нам требуются: входная последовательность, по которой будет проводиться поиск; вес выравнивания входной и найденной последовательностей; случайный банк. E-value показывает нам достоверность находки. Чем значение меньше, тем больше вероятность того, что находка достоверна. "Случайный" банк - иначе банк случайных последовательностей - это банк, который можно получить посредством перемешивания остатков в последовательностяъ оригинального, изначального банка. "Случайный" банк должен отвечать важному условию - он должен быть того же размера, что и изначальный банк, то есть все его последовательности должны сохранять длину и аналогию остатков. При наличии случайного банка можно попробовать найти E экспериментально. Создадим много случайных банков путем перемешивания последовательностей. Запустим поиск той же (входной) последовательности с теми же параметрами в каждом из этих банков. Соответственно, после каждого запуска у нас будет выводиться число находок с score лучше или равным изначальному. Тогда E определяется как среднее всех этих чисел. Однако в BLAST-е не используются случайные банки. Математик S.Karlin предложил формулу для расчета E только по весу выравнивания входной последовательности с находкой, числу букв во входной последовательности и суммарному размеру банка, в котором ведется поиск. Он доказал, что E, рассчитанное по формуле, мало отличается от E, которое получится в результате экспериментов со случайными банками. Именно эту формулу использует BLAST. |
||||||||||||||||||||||||||||
| Найдем сходные последовательности среди белков семейства Thermotogaceae. Запрос выдал 942 находки. Я нашла последовательность белка WP_012002441.1, которая была обнаружена в обоих поисках.Score этих находок одинаковый, но E-value разное ( Общий поиск - 0.24, по семейству - 9е-05).Такое различие связано с тем, что поиск проводится по банкам, которые имеют разный объем. В поиске по семейству банк меньше, значит данная находка менее случайна. | ||||||||||||||||||||||||||||
Возьмем последовательность белка WP_019910159.1 (которая была взята из находок) и построим выравнивание двух
последовательностей.Мы получили карту локального сходства, на которой видно 3 места разрыва.(Рис.4)Первый разрыв - на его
месте стоит 2 гепа, второй разрыв - только 1 геп, на месте третьего - 3 гепа.(Рис.5)
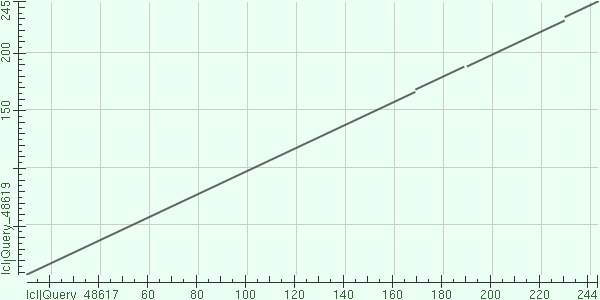 Рис4.Карта выравнивания белка Thermotoga Thermarum и белка Paenibacillus sp. HW567.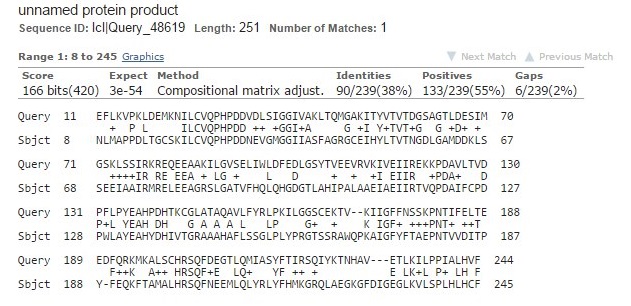 Рис5.Выравнивание белка Thermotoga Thermarum и белка Paenibacillus sp. HW567 |
||||||||||||||||||||||||||||
| Используя множественное выравнивание из практикума 8, создадим собственную базу данных( она состоит из 5 последовательностей)
Для это воспользуемся командой
makeblastdb и запишем нову базу, а уже командой blastp осуществим поиск в этой базе нужной последовательности.Лучшая
находка с E-value 0.033. Данные представлены в таблице ниже.
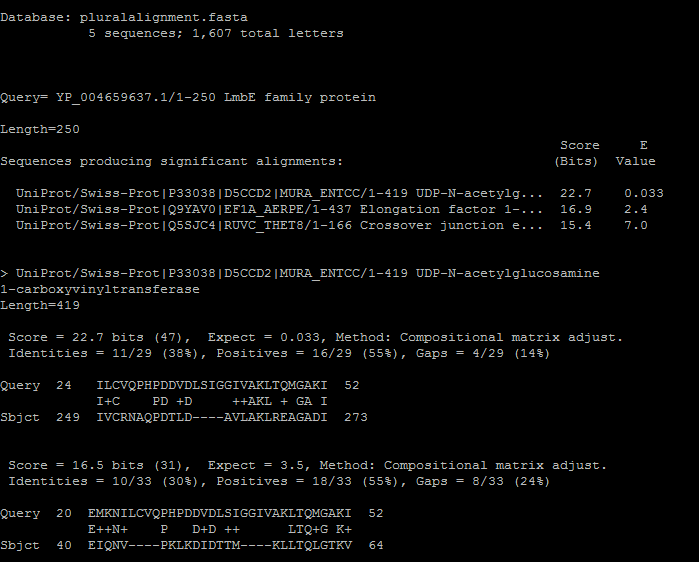 Рис.5 Выравнивание последовательности по моей базе |