Алгоритм PSI-BLAST (Position-Specific Iterated BLAST) используется для поиска удаленных гомологов белков. В данном алгоритме применяется техника профилей, иными словами таблиц, где по строкам располагаются все возможные аминокислоты, а по столбцам - номера позиций в выравниавании, и числа в ячейках таблицы - это вес конкретной аминокислоты в конктретной позиции. Из этого логично предположить, что частота ее встречаемости в этом месте в гомологах прямо пропорциональна ее весу.
Смысл этих профилей заключается в поиске новых гомологов, то есть алгоритм представляет собой поиск по профилю, затем коррекция нового профиля, поиск по новому профилю и т.д.
По отношению к поиску профиль выполняет сходные функции с матрицей BLOSUM в классическом алгоритме BLAST (оценка веса выравниваний новых последовательностей с заданной нами последовательностью, то есть помогает выявить наилучшие хиты.
Пошаговый алгоритм:
Обычный белок-белковый BLAST (первая итерация)
Построение профиля (PSSM) на основе множественного выравнивания находок (E-value < 0,005)
Использование PSSM при поиске последующей итерации
Новые последовательности с E-value < 0,005 добавляются в выравнивание, по которому затем строится новая PSSM
Поиск проводится до тех пор, пока не сойдется
Поиск считается сошедшимся, если после очередной итерации список находок выше порога не изменился (это означает, что профиль тоже не изменится, и следующая итерация даст тот же результат)
Применение PSI-BLAST
Для работы был выбран случайный белок из списка. Им оказался Q65664 (SwissProt_ID белка: Q65664_BMV). При поиске использовался банк nr, так как хороших находок в Refseq нет.
Скорее всего это связано с тем, что последнее обновление Refseq было в 2008.
Идентификаторы "худшей из лучших" и "лучшей из худших" находок, их E-value, а также число лучших находок для каждой интерации представлены в таблице 1.
Таблица 1. Результаты PSI-BLAST для Q65664.
Номер итерации
Число находок выше порога (0,005)
Идентификатор худшей находки выше порога
E-value этой находки
Идентификатор лучшей находки ниже порога
E-value этой находки
1
19
NP_658998.1
4e-53
ENH80566.1
0.064
2
22
CAJ29330.1
0.004
ABU62578.1
0.005
3
24
AAK52425.1
0.004
AFX68428.1
0.005
4
24
AAK52425.1
0.004
AFX68428.1
0.005
Из данных, представленных в таблице 1 видно, что после первого раунда поиска было найдено 19 последовательностей белков с E-value выше установленного порога. Исходя из примера, приведенного в подсказках (если после находки с E=2E-10 идет находка E=0.001 (разница в 7 порядков), то стоит попробовать отключить вторую находку (и те, что ниже) от очередной итерации), были отобраны последовательности для построения профиля. На втором раунде поиска нашлось на 3 хита больше, чем в первом. После третьего раунда - на 2 хита больше по сравнению с предыдущим. Результаты дальнейших поисков повторяли результаты третьего раунда, что ожидаемо. Основываясь на данных последнего раунда поиска было построено
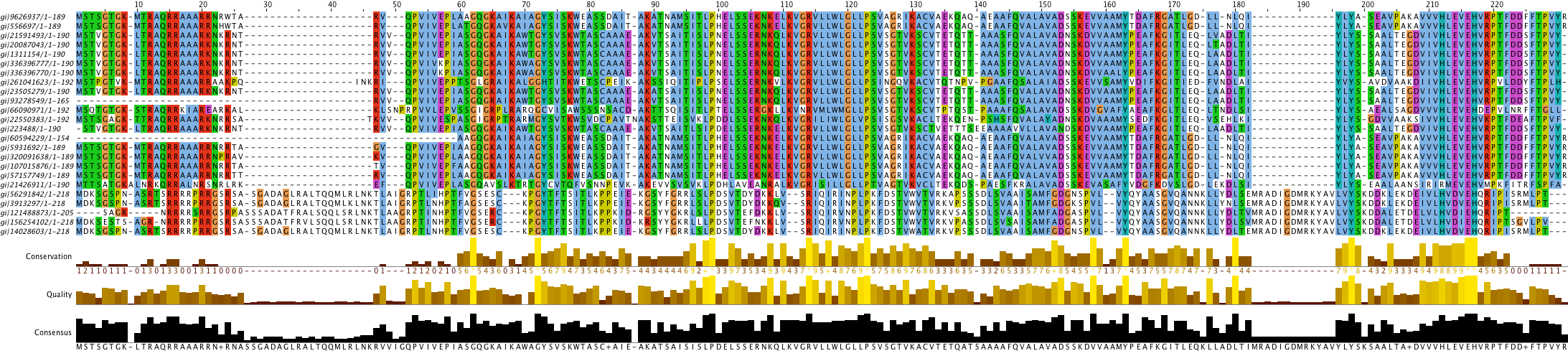
множественное выравнивание 24 хитов (рис.1).
Рисунок 1. Множественное выравнивание гомологов белка Q65664, включая саму последовательность изучаемого белка. Для окраски использована стандартная цветовая гамма Clustalx.
В целом, последовательности схожи между собой, четко можно выделить консервативные участки и петли. Однако, последние 4 последовательности достаточно сильно отличаются от остальных, но это и неудивительно, так как в таблиуе результатов поиска они идут с резко отличающимся E-value: находка №19 имеет E-value, равное 2е-63, между тем, как E-value последующих пяти находок колеблится в пределах от 0.002 до 0.004. Это различие и объясняет различную степень их гомологичности (ее снижение).