Сборка последовательности, секвенированной по Сэнгеру
Результат сборки
При помощи программы Ugene была собрана консенсусная последовательность из прямого и обратного ридов, полученных методом секвенирования по
Сэнгеру. Консенсус можно скачать по ссылке.
Основой проблемой было получение референсной последовательности. Для этого алгоритм получения консенсуса на основе хроматограмм запустили дважды.
Консенсус первого запуска стал референсной последовательностью для второго (в первый раз референсом выбрали последовательность хроматограммы с прямого праймера).
Выравнивание референсной последовательности (2-ой консенсус) и последовательностей хроматограмм можно скачать по ссылке.
Характеристика хроматограмм
Прямая хроматограмма. Нечитаемые участки 1-18 и 376-379.
В среднем примерный уровень шумов на хроматограмме низкий по отношению к сигналу. Их высокий уровень наблюдается ожидаемо в начале и конце хроматограммы. Редки случаи
возникновения посторонего сигнала в хроматограмме. Можно сказать, что качество данных хорошее.
Обратная хроматограмма. Нечитаемые участки 1-32 и 380-384.
В данной хроматограмме "на глаз" средний уровень шумов выше, чем в предыдущей, по отношению к сигналу. Наиболее трудно читаемые участки из-за шума расположены в начале и
конце хроматограммы. Также прочтение содержит участок с повышенным уровнем ошибочного сигнала, может быть, в следствие отрыва отрыва флуорофора.
Некоторые проблемы
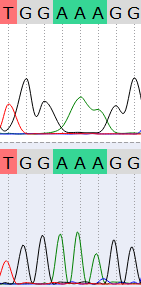
На хроматограмме выше видно пропущен один адениновый нуклеотид. Поскольку на хроматограмме ниже имеется 3 четких пика аденина, то было принято решение
оставить 3 аденина, а не 2.
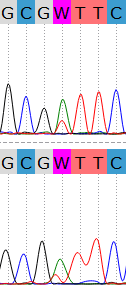
На двух хроматограммах происходит наложение сигналов тимина и аденина. Можно это посчитать шумом и оставить в позиции аденин, однако, на мой взгляд,
одновременное появление одинакового сигнала в двух разных хроматограммах не случайно, в данном случае это полимофизм.
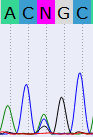
Данный участок представлен только одной хроматограммой, поэтому возникает проблема в разрешении позиции с 3 разными пиками. Выхода из этой ситуации нет,
кроме повторного секвенирования, поэтому позиция осталась неразрешенной.
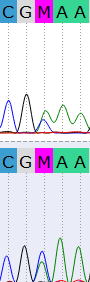
Данная ситуация аналогична 2, только в данном случае полиморфизм болеее очевиден, так как на нижней хроматограмме пики аденина и
цитозина почти равной высоты.
Примеры нечитаемых фрагментов
Пример проблемной хроматограммы
Проблема данной хроматограммы в том, что происходит наложение множества пиков на другие. Эта ситуация наблюдается на протяжение всей хроматограммы, поэтому
можно предположить контаминицию, в образце была ДНК нескольких организмов.