Распределение длин белков, синтезируемых Oceanobacillus iheyensis штамм HTE831
С помощью скрипта, написанного на языке программирования Python, из файла, содержащего информацию о геноме Oceanobacillus iheyensis штамм HTE831 (запись NC_004193 базы данны RefSeq) мною были получены хромосомные талицы, содержащие информацию о генах, кодирующих белки, транспортные, рибосомальные и ядерные РНК. Используя Microsoft Excel я проанализировал некоторые закономерности в распределении длин белков, синтезируемых данной бактерией.
Первым шагом было нахождение максимальных, минимальных длин белков, их медианы и среднее арифмитическое. Для всех белков и отдельно для белков, кодируемых на прямой и обратной цепях:
Таблица 1. информация о длин белков, синтезируемых Oceanobacillus iheyensis штамм HTE831| Направление кодирования | Минимальная длина | Максимальная длина | Средняя длина | Медиана |
| Все белки | 27 | 2373 | 290,8588571 | 261 |
| Кодируемые на прямой цепи | 27 | 2373 | 283,7963282 | 248 |
| Кодируемые на обратной цепи | 34 | 1530 | 297,865111 | 275 |
Как видно из таблицы 1, медиана и среднее значение всегда близки друг другу, следовательно большинство значений нахоидтся в области длин, соответствующих среднему значения, причём эти значения ближе к минимальному, чем к максимальному, следовательно длинные белки встречаются редко и являются "еденичными случаями". Средние значени и медианы белков, кодируемых на прямой и обратной цепи, а также всех белков вместе практически не различаются. Отсюда можно предположить, что их распределения по направлению кодирования случайно.
Следующим шагом было нахождение и построение графика эмпирической функции распределения, в данном случае показывающей, какую долю от всего числа белков занимают белки, короче определённой длины. Был получен следующий график:
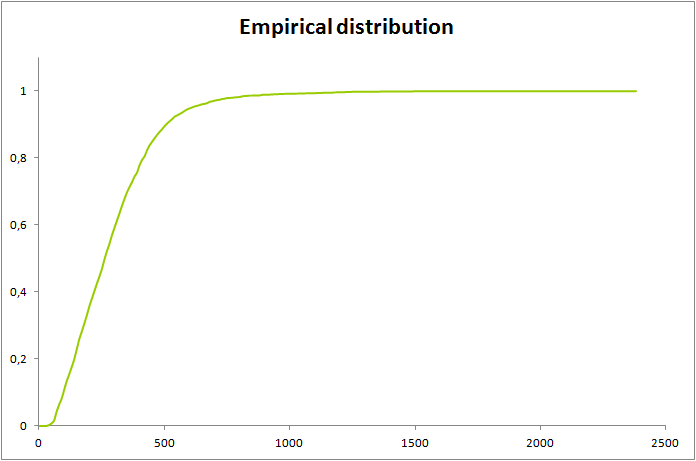 Рис.1. график эмпирической функции распределения длин белков, синтезируемых Oceanobacillus iheyensis штамм HTE831
Рис.1. график эмпирической функции распределения длин белков, синтезируемых Oceanobacillus iheyensis штамм HTE831
Который подтверждает предположение о том, как распределены длины белков - длины большинства не превышают 500 аминокислотных остатков.
Следующим шагом было построение столбчатых диаграмм, показывающих распределение длин белков. Для удобства были взяты интервалы в 70 аминокислотных остатков. Для всех белков получилась такая диаграмма:
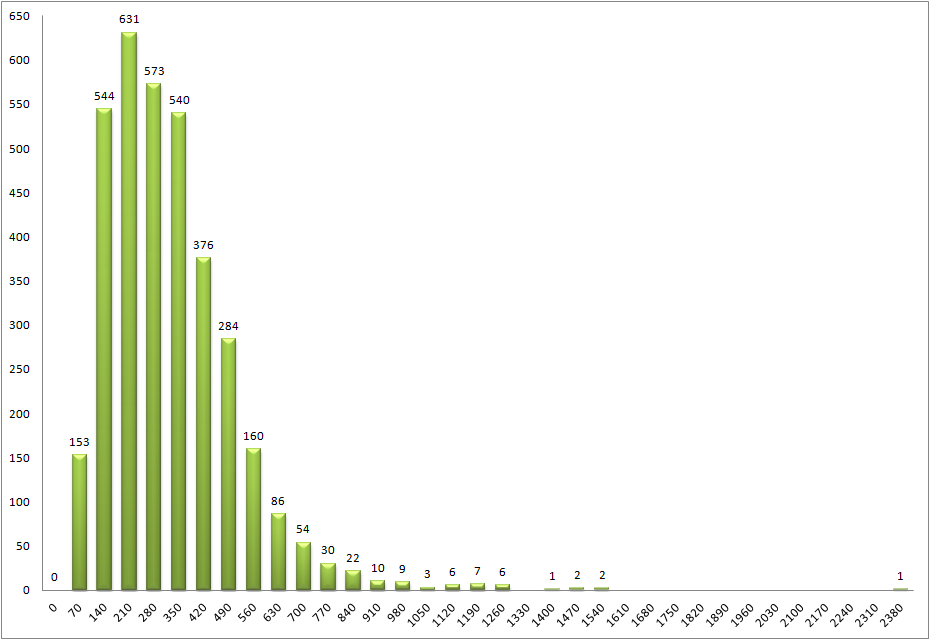 Рис.2. распределение длин всех белков
Рис.2. распределение длин всех белков
Как видно из рисунка 2, больше всего встречается белков с длиной от 210 до 280 аминокислотных остатков.
Также была построена столбчатая диаграмма, показывающая аналогичные данные, но для беков, кодируемый на прямой и обратной цепи отдельно:
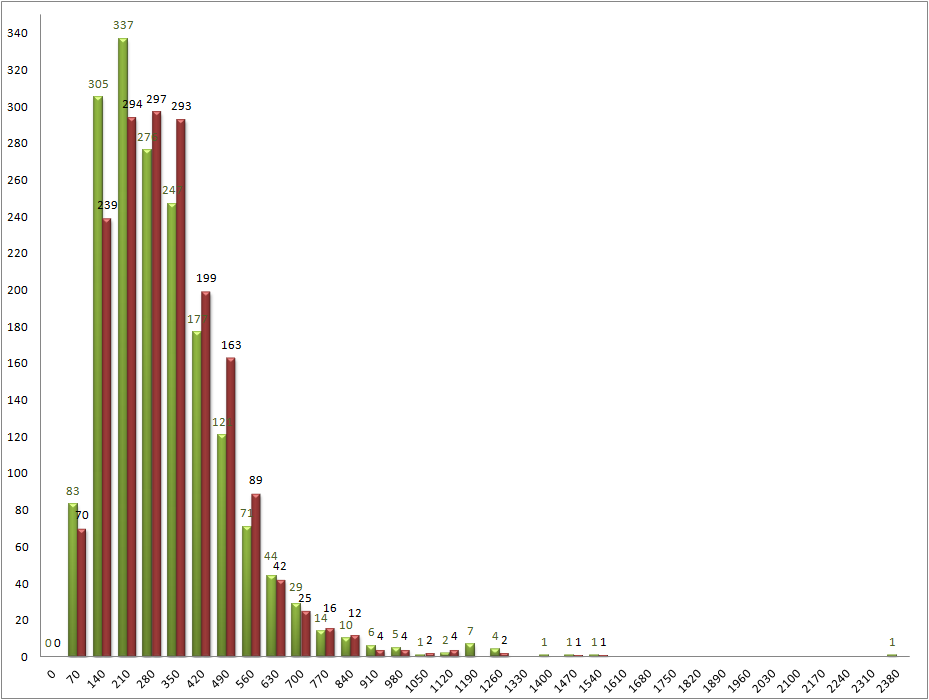 Рис.3 распределение длин белков, отдельно для закодированных на прямой и обратной цепях. Зелёные столбики - белки, закодированные на прямой цепи, красные - на обратной.
Рис.3 распределение длин белков, отдельно для закодированных на прямой и обратной цепях. Зелёные столбики - белки, закодированные на прямой цепи, красные - на обратной.
На рисунке 3 видно, что интервалы длин с максимальным числом белков несколько меняются для прямой цепи это интервал также 210-280, а для обратной цепи это интервал 210-420. Такое распределение длин белков выглядит случайным. Но можно расчитать, является ли такое распределение случаным или нет с помощью величины Χ2, показывающей вероятность того, что отклонение полученного результата от ожидаемого результата (а данном случае - от распределения, общего для всех белков) не случайно.
В случае прямой цепи значение "хи-квадрат" составило 19,09316687, а случае обратной 18,94103008. Так как мы суммировали 36 членов, следовательно степень свободы равна 35. В соответствии с таблицей распределения велицин хи-квадрат получаем, что вероятность неслучайного рапределения значений длин белков меньше, чем 0,025. Отсюда можно сделать вывод, что распределение белков по кодированию на прямой и обратной цепи случайно.