Практическая работа 7
Задание 1
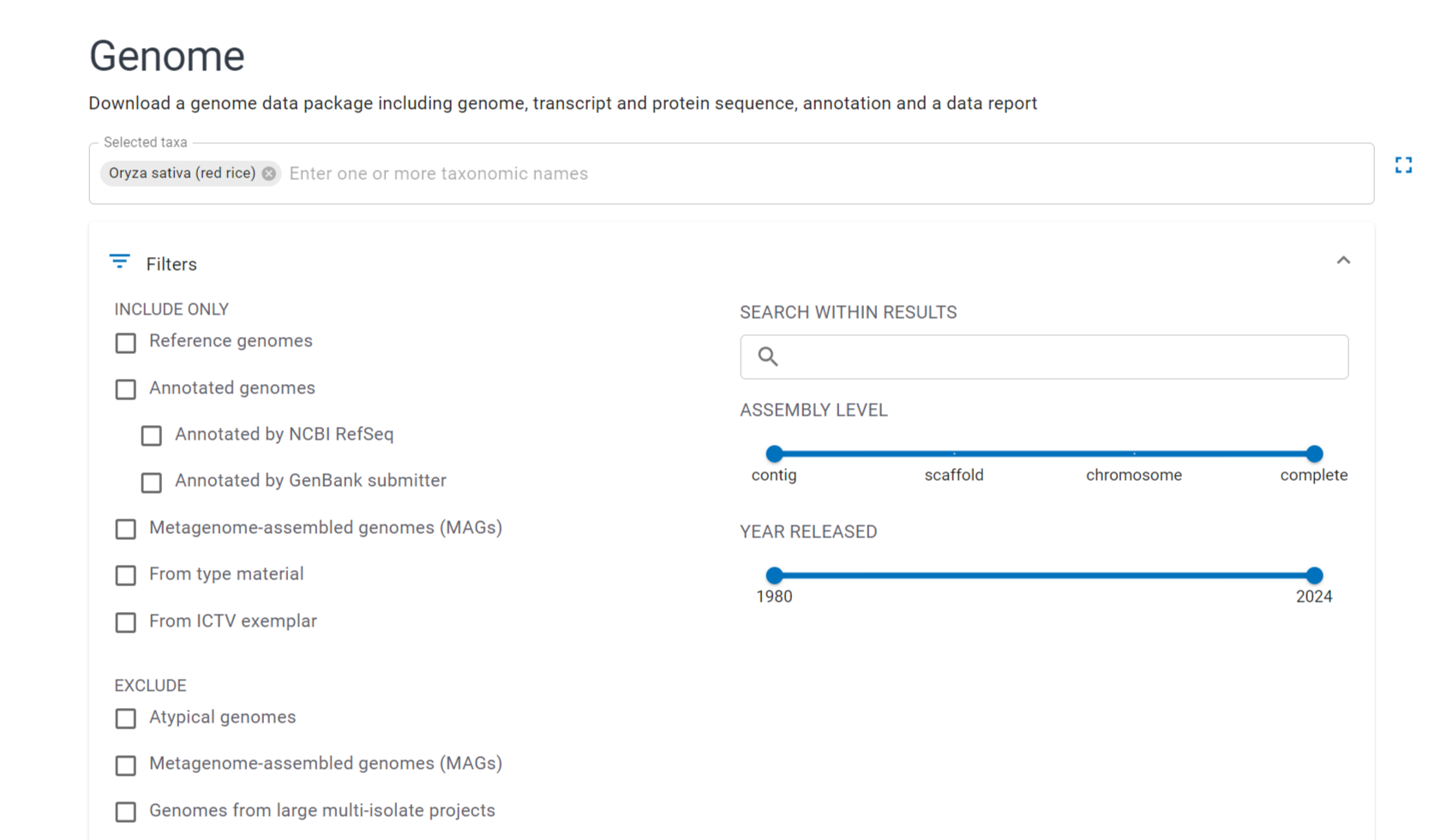
Для анализа сборки генома я выбрал растение Oryza sativa Japonica Group (Japanese rice). Ботаническая иллюстрация Oryza sativa из книги Köhler’s Medizinal-Pflanzen представлена на Рис. 1, а на Рис. 2 – поисковый запрос в NCBI Datasets, с помощью которого была найдена информация о геноме риса. Всего было найдено 114 сборок, уровень сборки – полный геном, то есть известны полные последовательности всех хромосом, а также последовательности ДНК митохондрий и пластид.
Задание 2
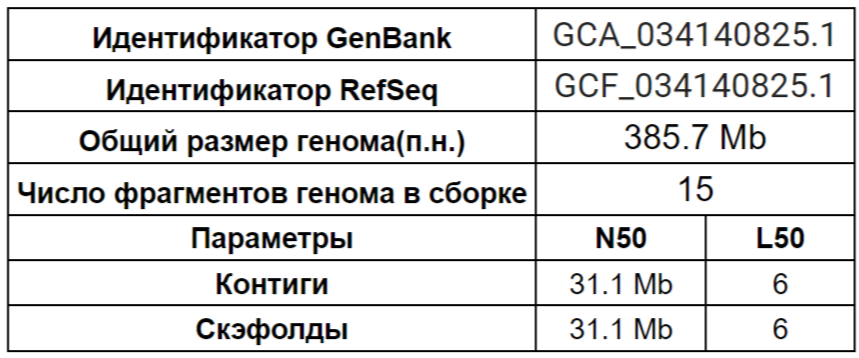
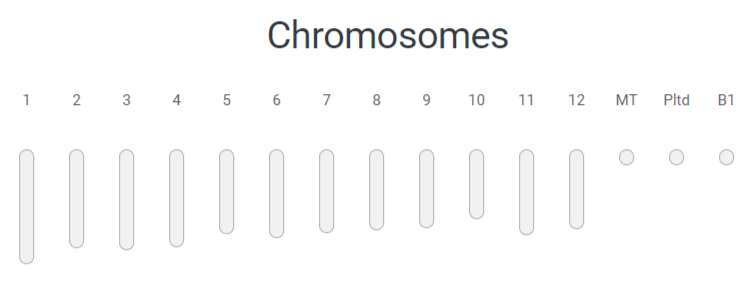
В Табл. 1 приведена некоторая информация о сборке генома Oryza sativa. Как можно увидеть на Рис. 3 геном состоит из 12 хромосом(гаплоидный набор), а так же митохиндриальной(MT) и пластидной(Pltd) ДНК, причем в митохондриях помимо основной молекулы ДНК находится также плазмида(B1). Далее рассмотрим смысл некоторых параметров, приведенных в Табл. 1 . Представим, что мы упорядочили множество всех контигов в порядке убывания. Теперь будем рассматривать различные срезы полученного списка, начиная от первого контига. Среди них выберем минимальный по числу контигов список, суммарная длина контигов которого составляет 50% всего генома или более. Число контигов в этом списке будем обозначать L50, а длину минимального контига – N50. Аналогичную процедуру проведем для скэфолдов и получим значения N50 и L50 для них.
Эта сборка представляет из себя полный геном Oryza sativa вместе с геномом митохондрий и пластид, а также является референсной(то есть неплохо аннотированна). Поэтому я выбрал именно её.
Задание 3
- genome.fna – содержит нуклеотидную последовательность всего генома, включая ДНК митохондрий и пластид.
- protein.faa – содержит аминокислотную последовательность всех белков организма.
- gen.gbff – помимо об организме(таксономию, идентификаторы и т.д.), также содержит информацию об расположении генов, особенностей их продуктов, последовательности хромосом.