
Мне достался набор генов среднего размера со следующими ID: AK1 TPK1 AK2 AK4 AK5 NTPCR AK7 AK8 NFS1 THTPA ALPP ALPL ACP1 ALPI ALPG
Сказать сразу что то сложно, поэтому обратимся в Gene Ontology & PANTHER
Запускаем GO Enrichment Analysis для этого сета генов со следующими параметрами (Рис 1). Получается довольно большая таблица на выходе. FOLD enrichment, количество белков в категориях и значения FDR говорят о том, что набор генов не совсем случайный.
Из output'a можно вытащить более полные названия белков:
ALPL, ALPG, ALPP, ALPI - Alkaline phosphatases (по-русски Щелочные фосфатазы)
THTPA - Thiamine-triphosphatase
TPK1 - Thiamin pyrophosphokinase 1
NTPCR - Cancer-related nucleoside-triphosphatase
NFS1 - Cysteine desulfurase, mitochondrial
ACP1 - Low molecular weight phosphotyrosine protein phosphatase
AK1, AK2, AK4, AK5, AK7, AK8 - Adenylate kinases
Если искать общность этих белков в биологических процессах то можно выделить следующие процессы в которых они участвуют: В ADP biosynthetic process: AK1, AK2, AK4, AK5 В thiamine diphosphate biosynthetic process: TPK1, THTPA В nucleoside monophosphate phosphorylation: AK1, AK2, AK4, AK5, AK7, AK8 dephosphorylation: ALPL, ALPG, ALPP, THTPA, ALPI
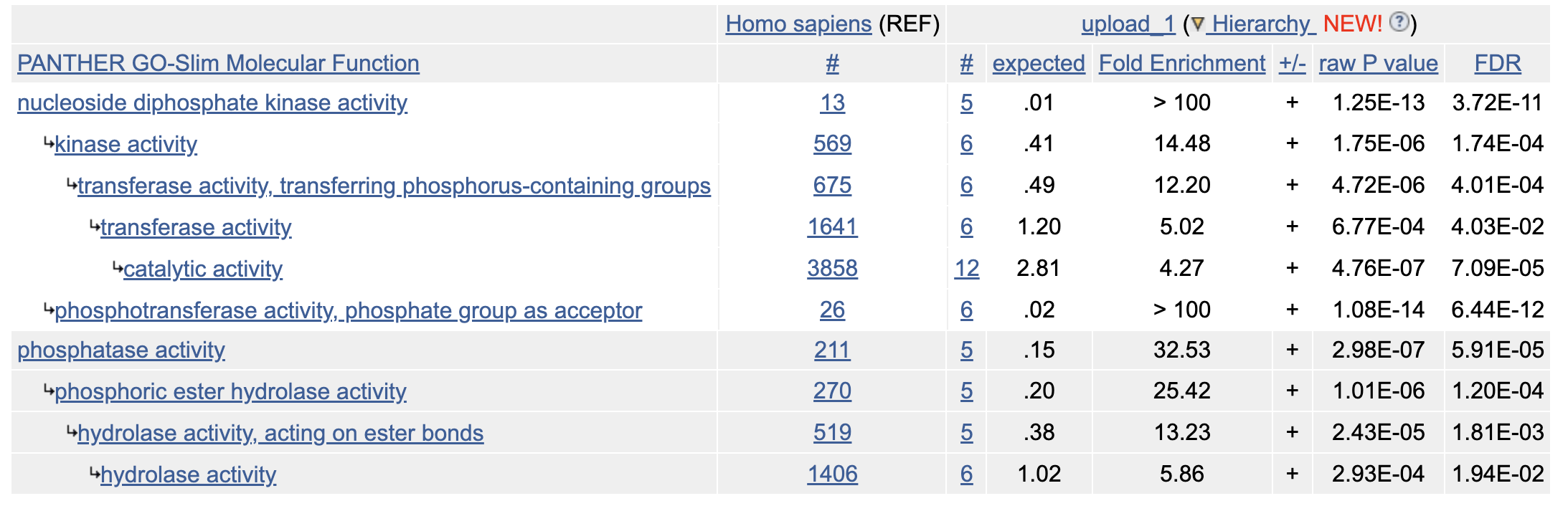
При этом 13/15 белков учатсвуют в метаболитических процессах связанных с фосфатами - то есть все кроме NTPCR и NFS1 получается? Вообще NTPCR судя по названию очевидно работает с фосфатами, но для него просто неаннотированы биологические процессы в Gene Ontology (Рис 2).
Запустим GO Enrichment Analysis с параметром Annotation Data Set: Panther GO-slim Molecular Function и получим что большиснтво белков относятся к классу гидролаз (конкретнее - фосфатаз) и трансфераз (конкретнее - киназ).
Включая все источники ребер графа получаем следующую картинку (Рис. 4), где NFS1 и ACP1 аутсайдеры, которые не имеют вообще никаких связей с дргуими белками. Для NFS1 это ожидаемо, потому что это вообще митохондриальный фермент другого класса. Для ACP1 впринципе нет статей про взаимодействие с другими белками и частично нет аннотации в GO и Reactome. Причину аутсайдерства NFS1 и ACP1 обсудим еще ниже. Еще обратим внимание на мощный кластер щелочных фосфатаз (ALP), в который входят ALPI (Alkaline phosphatase, intestinal), ALPG (Alkaline phosphatase, germ cell), ALPP (Alkaline phosphatase, placental) и ALPL (Alkaline phosphatase, tissue-nonspecific isozyme)
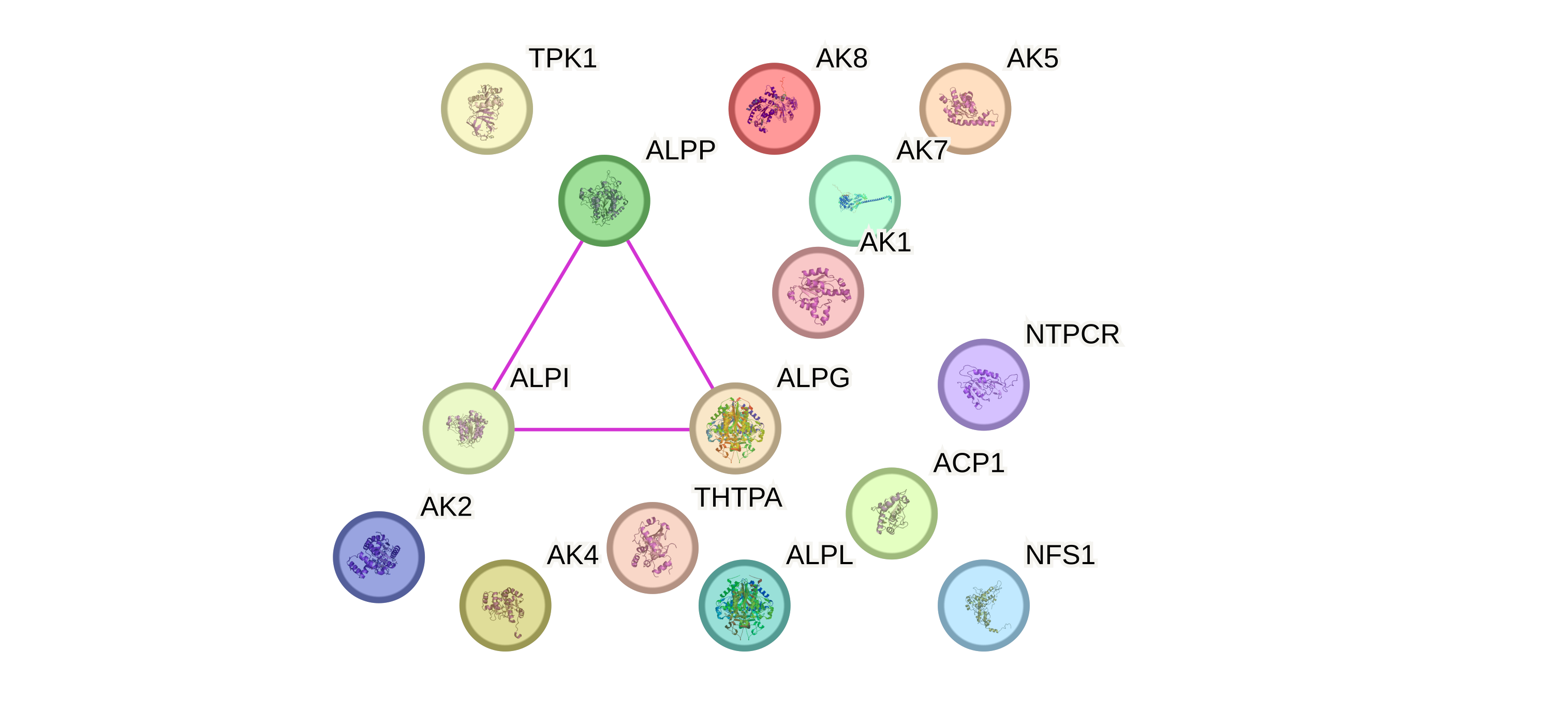
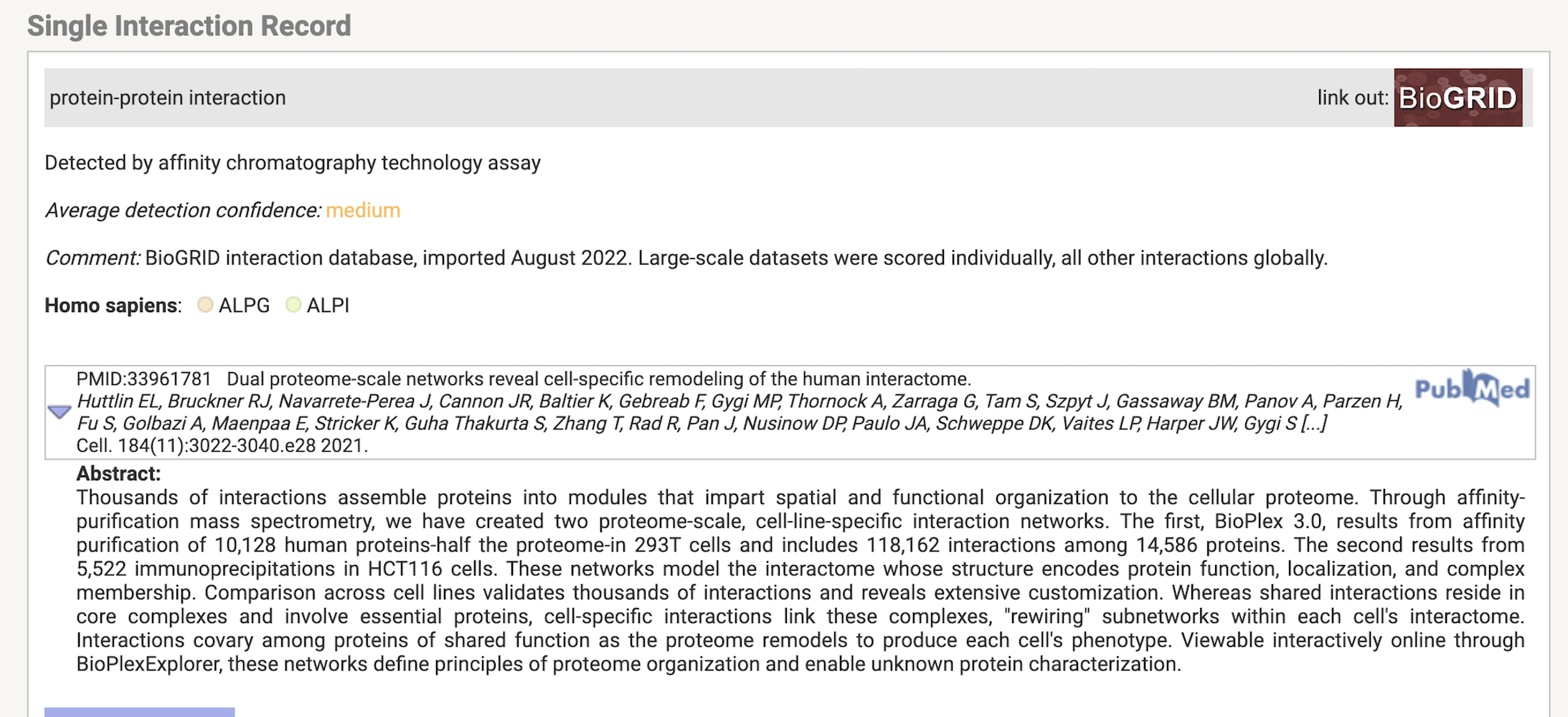
Посмотрим какие белки могут физически взоимодействовать между собой. Поставим Network type: physical subnetwork. Получаем, что ALPI, ALPG, ALPP могут взаимодествовать между собой. Странно конечно что там нет ALPL, но вероятно неполнота данных. Может они образуют какой то мультисубъединичный комплекс? По названию понимаем что это скорее всего просто три разных изоформы щелочной фосфатазы, которые функционируют в разных органах: в плаценте, кишечнике и в гонадах. Тогда вообще странно, что они физически взаимодействуют, потому что они не должны экспрессироваться одновременно (оставляя в active interaction sources только Co‑expression убеждаемся в отсутсвии коэкспрессии). Посмотрим почему так. Кликая на граф понимаем, что это взаимодействие подтверждено афинной хроматографией и ко-иммуноприцепитацией в статьях, в которых просто все смешивали и смотрели взаимодействия (Рис. 5). Ничего нам особо это не говорит. Ну и ладно.
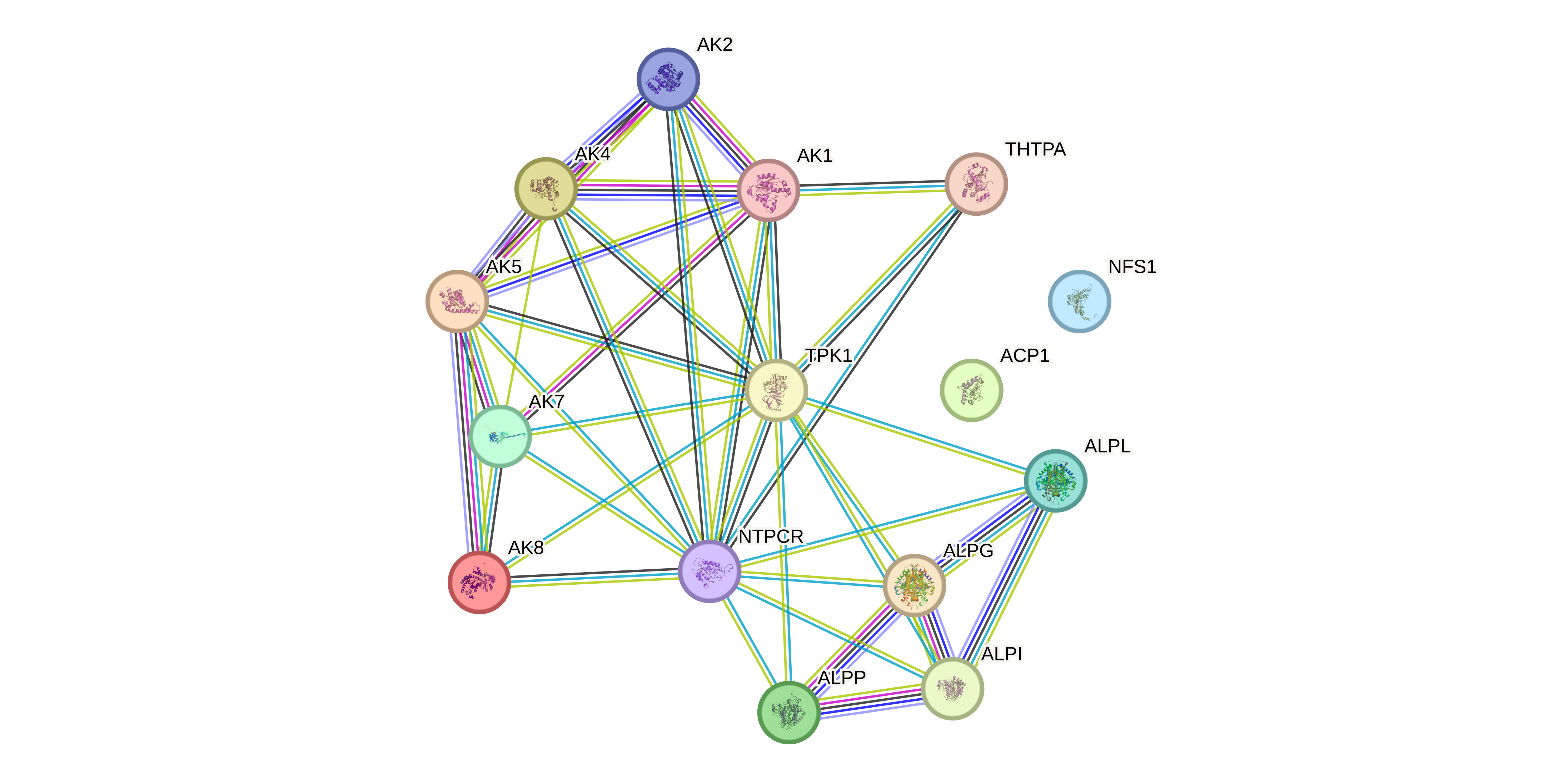
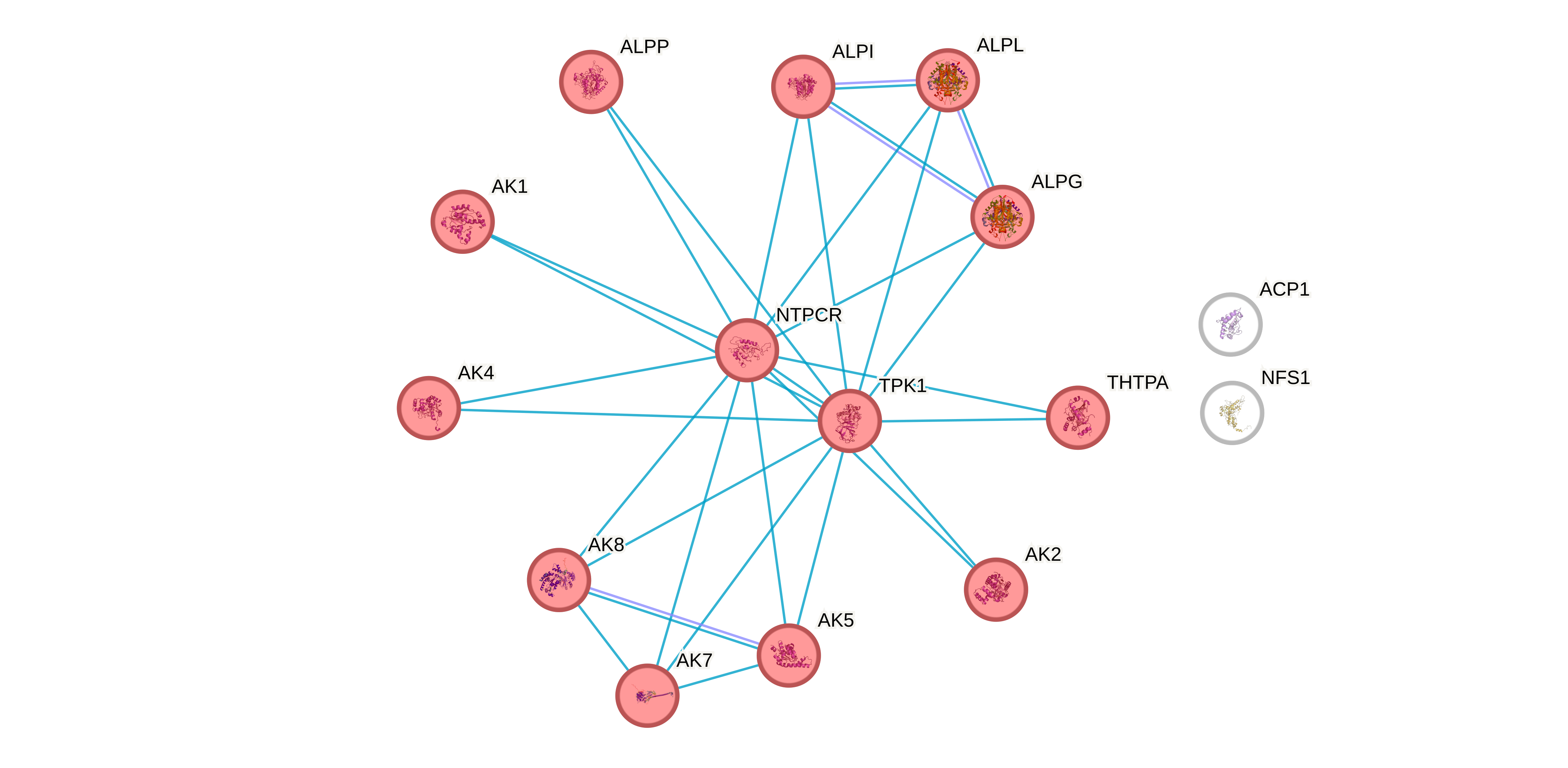
Заметим что, все белки кроме наших аутсайдеров напрямую или косвенно связаны между собой линией одного цвета. Это исчточник active interaction source "Databases". Проведем MCL кластеризацию по этому источнику и увидим что все белки кроме NFS1 и ACP1 кластеризуются в один кластер (Рис 7), и если мы провалимся во вкладку Databases в разделе viewers, то увидим что объединяющим фактором для этих всех белков, является участие в пути метаболизма тиамина (по данным KEGG).
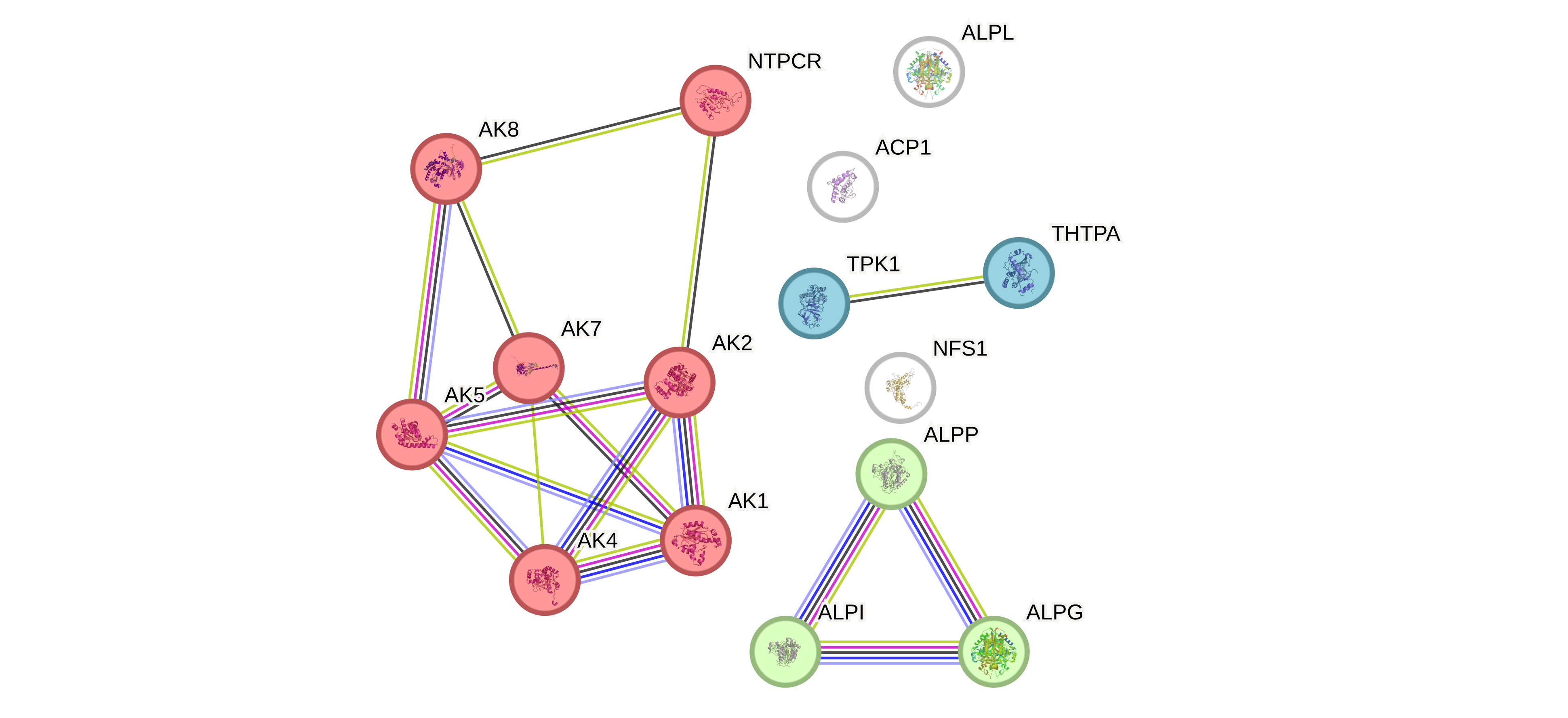
Если мы кластеризуем по всем источникам кроме баз данных то у нас выделяется 3 кластера (Рис 7). Первый кластер (красный) - аденилат киназы и NTPCR, при этом NTPCR явно там ни к селу ни к городу, поскольку веса у ребер маленькие. Второй кластер (зеленый) - кластер изоформ щелочных фосфатаз, ну собственно было бы странно если бы было по другому, потому что это один фермент. ALPL туда не попала, потому что единственное что связывало ее с кластером щелочных фосфатаз с нормальным весом - это участвие в общем метаболитическом пути. Третий кластер (синий) - судя по всему это класстер ферментов которые напрямую взаимодействуют с тиамином в пути его метаболизма. При этом судя по графу метаболитических путей (Рис 7) TPK1 является одним из центральных ферментов этого пути. Посмотрим оправдаются ли эти ожидания когда начнем рассматривать KEGG (спойлер: действительно окажется, что в этом наборе TPK1 - единственный фермент, взаимодействующий с тиамином напрямую).
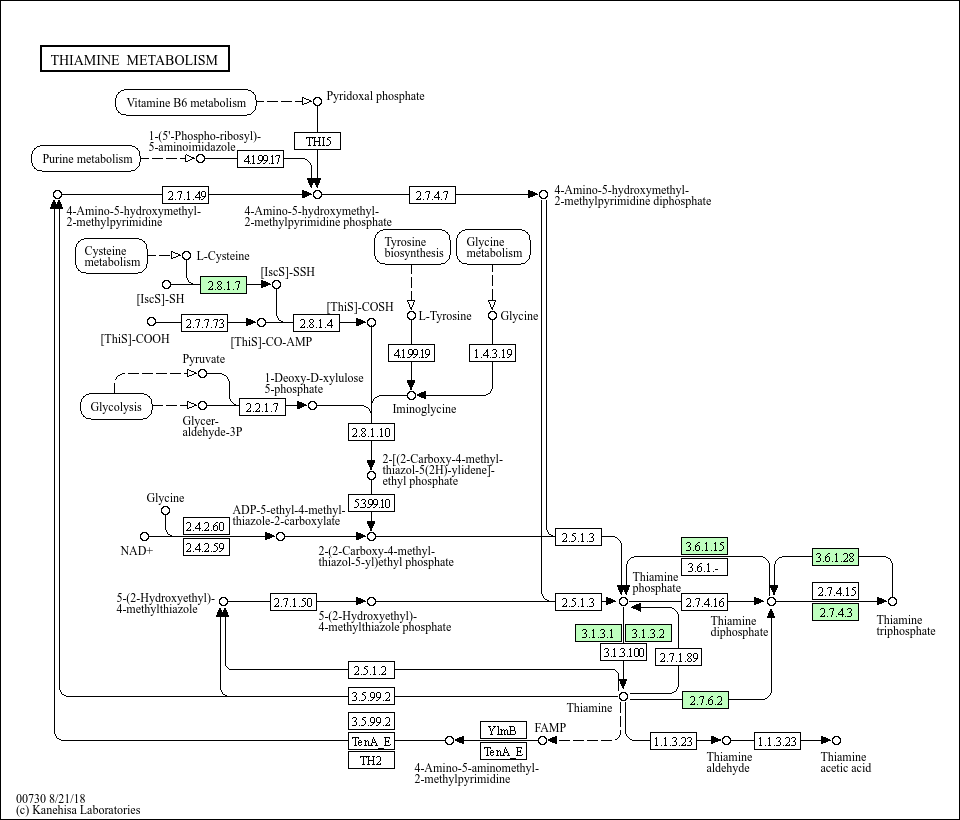
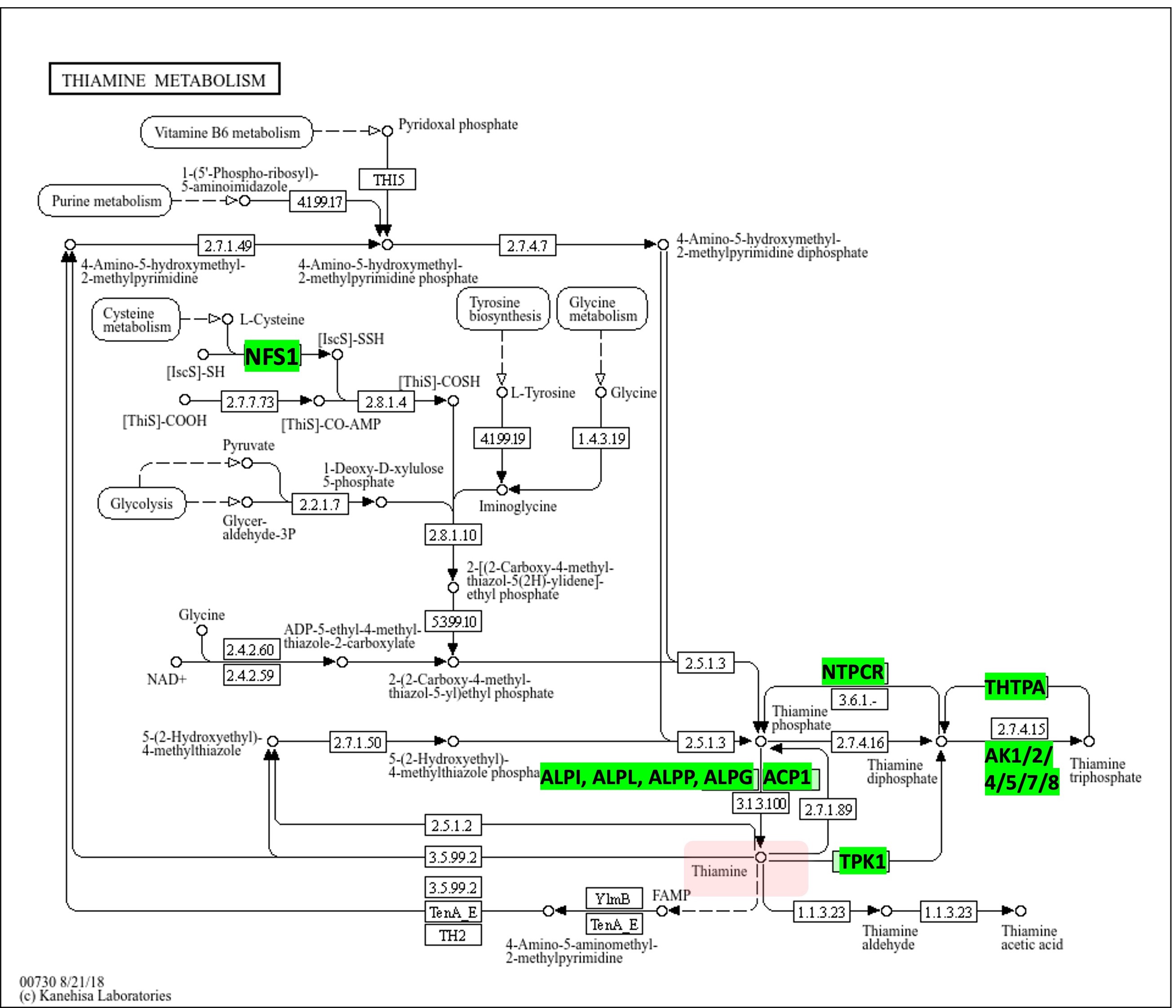
Ипользуя перекрестную ссылку из STRING попадаем в KEGG, а именно - в карту сборную метаболизма. Из нее видно что тиамин является продуктом метаболизма пуринов, витамина В6 и таких аминокислот как цистеин, тирозин и глицин. Еще через определенное количество стадий в тиамин могут превращаться продукты гликолиза.
Но в чем суть: мы видим здесь все 15 изначально выданных гена!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
То есть наши два аутсайдера сюда все таки попали. Но вопрос: почему STRING их не кластеризовал и даже не соединил ребрами? С NFS1 все впринципе понятно: он не проводит реакции с тиамином и ближайшими к нему метаболитами. С ACP1 возникают вопросики. Выставив в STRING все источники взаимодействий и minimum required interaction score = 0.001 мы получаем что все белки все таки связаны, однако ребра которые соединяют NFS1 и ACP1 имеют очень маленькие веса. Но главное - между ними так и не появилось связи по датабазам. Это вообще конечно очень интересно.
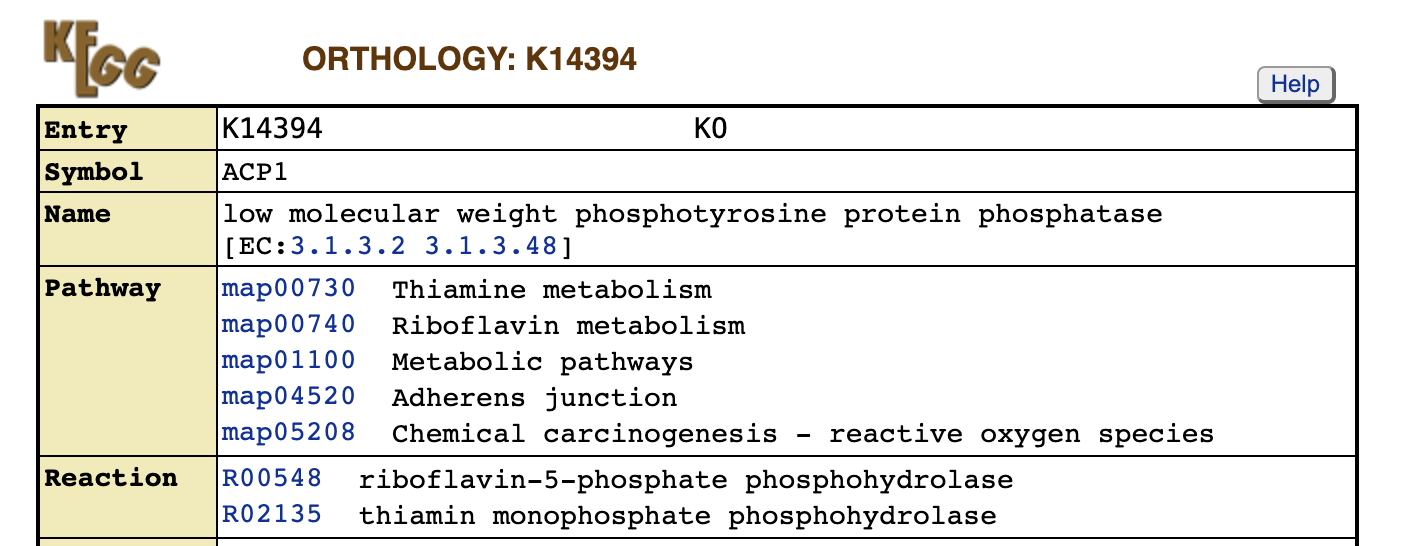
Если мы посмотрим на реакцию, которую по заявлению перекрестной ссылки катализирует ACP1, то обнаружим что перекрестная ссылка нам не врала. ACP1 (Low molecular weight phosphotyrosine protein phosphatase), несмотря на свое название, дейтсвительно может катализировать реакцию дефосфорилирования тиамина (Рис. 11).
Ответить на вопрос почему STRING не учитывает информацию об участии NFS1 и ACP1 в пути метаболизма тиамина сложно. Вероятно6, он посчитал тот факт, что NFS1 расположен в митохондриях и лишь опосредованно участвует в метаболизме тиамина, недостаточным для построения связи в графе, или это погрешности алгоритма.
Касательно набора генов: Выданный набор генов объединяет то, что ферменты кодируемые ими участвуют в метаболизме тиамина. При этом в наборе присутсвует по несколько изоформ для аденилаткиназ (AK) и щелочных фосфотаз (ALP). 14 из 15 ферментов крутятся вокруг реакций фосфорилирования и дефосфорилирования тиамина. Тот самый 1 из 15 ферментов - это NFS1 (цистеин-десульфорилаза), которая тоже опосредованно участвует в метаболизме тиамина.
Касательно баз данных:
В каждой из баз данных могут быть пробелы в информации касательно какого-нибудь гена. В некоторых базах алгоритмы могут по каким-то странным причинам не учесть связь между генами, которая отображена в другой базе данных. Поэтому, наиболее полную информацию о целевом наборе генов можно получить, проанализировав информацию из хотя бы нескольких баз данных.