2. PWM для последовательности Шайна-Дальгарно E.coli
1. Была выбрана последовательность Шайна-Дальгарно перед стартом трансляции генов в геноме E.coli штамма K-12 подштамм MG1655.
Последовательности длиной 20 нуклеотидов перед генами (всего 4298 штук) были получены из генома и хромосомной таблицы (RefSeq ID GCF_000005845.2) с помощью скрипта, разработанного и предоставленного Андреем Малышевым (за что я ему благодарен). Эти последовательности будут использоваться в качестве материала для обучения. Обычно последовательность Шайна-Дальгарно располагается примерно в 10 нуклеотидах до старт-кодона (Kapp et al., 2004), характерной является последовательность AGGAGG. Для выравнивания без гэпов программа Jalview показывает консенсус, представленный на Рис.1.

Консенсусная последовательность представляет собой набор самых часто встречающихся нуклеотидов на каждой позиции, поэтому это нормально, что она может отличаться от характерной последовательности Шайна-Дальгарно (AGGAGG). Как я понимаю, поскольку у последовательности AGGAGG нет четкой позиции, AGGGGA может быть ее усредненным представлением. Если представить, что последовательность AGGAGG смещается на 1-2 нуклеотида влево или вправо, тогда в центре будет чаще встречаться нуклеотид G.
3. Далее из промоторных последовательностей были вырезаны участки отличающиеся от AGGAGG не более чем на два нуклеотида (ссылка скрипт), это будет материал тестирования (для упрощения последующих вычислений, выборка сигналов была ограничена до 100).
4. В качестве материала для негативного контроля были выбраны последовательности длиной 6 нуклеотидов из тех же участков, но со сдвигом на 40 нуклеотидов влево в нетранслируемую область (тоже всего 100 последовательностей).
5. Построение PWM для выравнивания промоторных участков из пункта 2 (ссылка скрипт)

6-8. На основе PWM из пункта 5 были вычислены веса для всех последовательностей из предыдущих пунктов. Результат отражен на Рис.2.
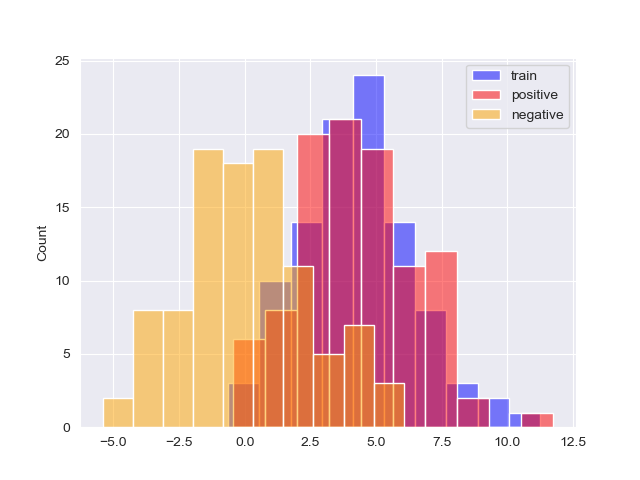
Исходя из гистограмм, выбрал порог равный 2.25, примерно такой порог позволяет минимизировать сумму ошибок первого и второго рода при последующем тестировании.
| Обучение | "+" контроль | "-" контроль | |
|---|---|---|---|
| Сигнал (+) | 218 | 234 | 83 |
| Сигнал (-) | 73 | 102 | 245 |