Это семейство является частью суперсемейства металло-бета-лактамаз. В нем не так много последовательностей — 45, и они не очень короткие, что крайне удобно для сравнения выравниваний.
Сравнение выравниваний одних и тех же последовательностей тремя разными программами Muscle, Mafft, Tcoffee
За референсное выравнивание возьмем Tcoffee, как отличающееся от двух других по методы построения (Tcoffee — на базе 3D-структуры, Mafft и Muscle — рафинированные, итеративные).
Tcoffee VS Muscle
Cписок блоков одинаково выровненных колонок:
(8,15)=(8,15)
(43,62)=(45,64)
(72,73)=(74,75)
(96,107)=(130,141)
(141,144)=(163,166)
(163,173)=(178,188)
(177,178)=(192,193)
(182,183)=(197,198)
(189,210)=(204,225)
(218,236)=(231,249)
(258,266)=(266,274)
Список одинаково выровненных колонок, не входящих в блоки:
251=259
253=261
Таблица 1. Tcoffee VS Muscle
First alignment length (PF16661_Tcoffee.fa)
266
Second alignment length (PF16661_muscle.fa)
274
Percentage of matching columns for the first alignment (PF16661_Tcoffee.fa)
42.48 %
Percentage of matching columns for the second alignment (PF16661_muscle.fa)
41.24 %
Tcoffee VS Mafft
Cписок блоков одинаково выровненных колонок:
(8,16)=(8,16)
(43,61)=(42,60)
(96,102)=(112,118)
(149,153)=(166,170)
(163,173)=(176,186)
(182,183)=(195,196)
(190,210)=(203,223)
(219,234)=(231,246)
Список одинаково выровненных колонок, не входящих в блоки:
137=157
158=173
251=259
Таблица 2. Tcoffee VS Mafft
First alignment length (PF16661_Tcoffee.fa)
266
Second alignment length (PF16661_mafft.fa)
279
Percentage of matching columns for the first alignment (PF16661_Tcoffee.fa)
34.96 %
Percentage of matching columns for the second alignment (PF16661_mafft.fa)
33.33 %
Обсуждение результатов
Из таблицы1 и таблицы2 видно, что сходства между выравниями Tcoffee и Muscle больше, чем между Tcoffee и Mafft. Также одинаково выравненных колонок в паре Tcoffee VS Mafft хоть не намного, но больше, чем в паре Tcoffee VS Muscle.
Как видно из списков блоков, в целом, много блоков одинаково выравнены во всех трех выравниваниях. При этом блоков в первой паре выравниваний, которых нет во втором выравниии((72,73)=(74,75) (141,144)=(163,166) (177,178)=(192,193) (218,236)=(231,249) (258,266)=(266,274)), больше, чем тех которые есть во второй паре, но нет в первой((149,153)=(166,170)) (пренебрегаем разницей в несколько позиций и отмечаем только полностью неперкрывающиеся блоки). Mafft работает быстрее чем Muscle, и возможно за счет этого точность получилась ниже.
Выравнивание по совмещению структур и сравнение его с выравниванием программой MSA
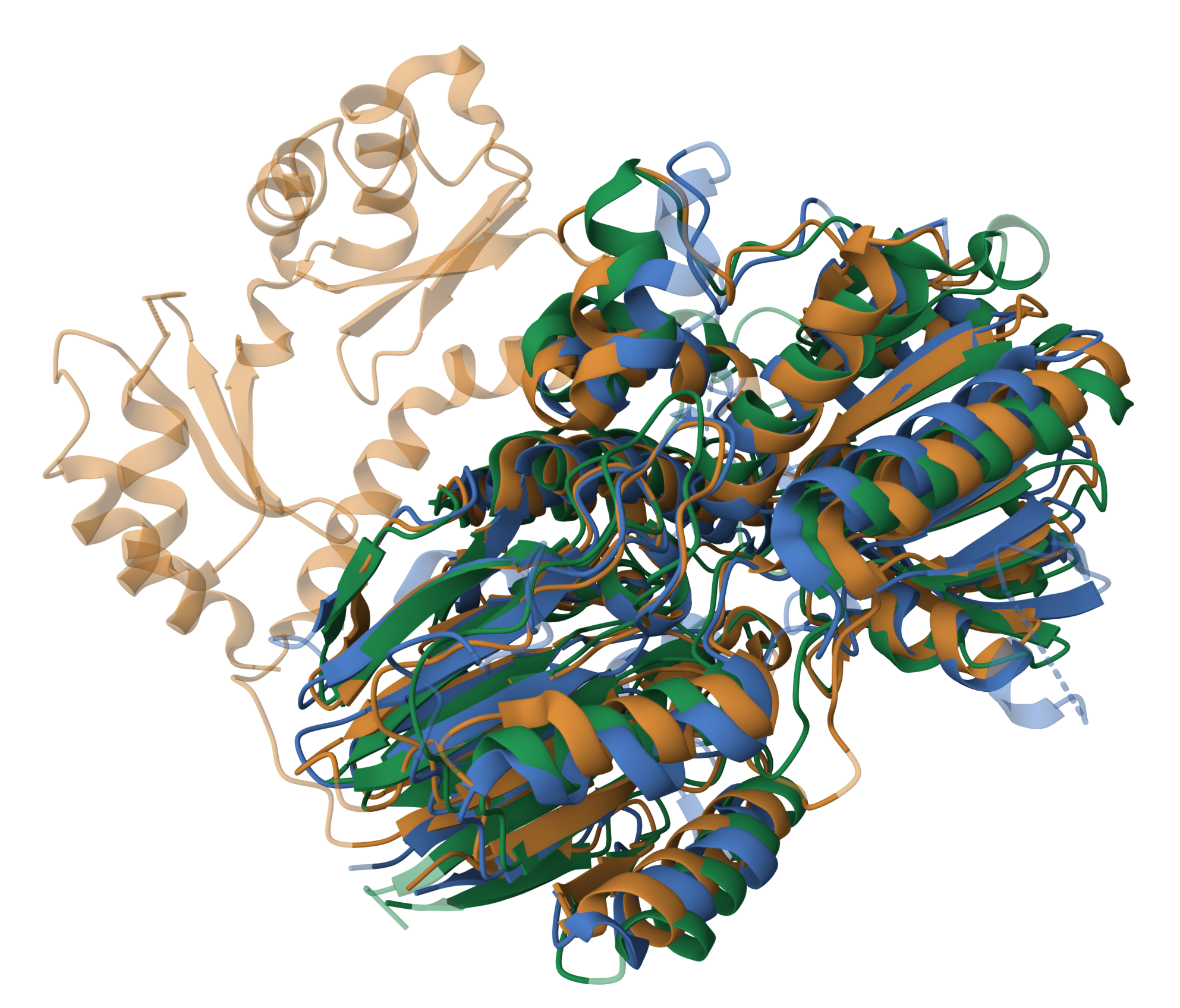
Из выбранного мной семейства были взяты 3 белка с известной структурой: 3AF5, 2I7X, 6Q55.
Было проведено выравнивание 3D струтур с референсом 3AF5
(рис1). Большая часть альфа спиралей и бета листов совпали, однако у 3AF5 есть достаточно большой фрагмент, который не выравнился ни с какими струтурами двух других белков (если посмотреть на последовательности, окажется, что 3AF5 существенно длиннее двух других белков, чем и обусловлены эти невыровненные альфа спирали и бета листы).
Далее сравниваем 2 выравнивания: полученное экспортом текстового файла из 3D выравнивания и выравнивание T-Coffee.
Сравнивали программой MACHO, используемой в предыдущем пункте.
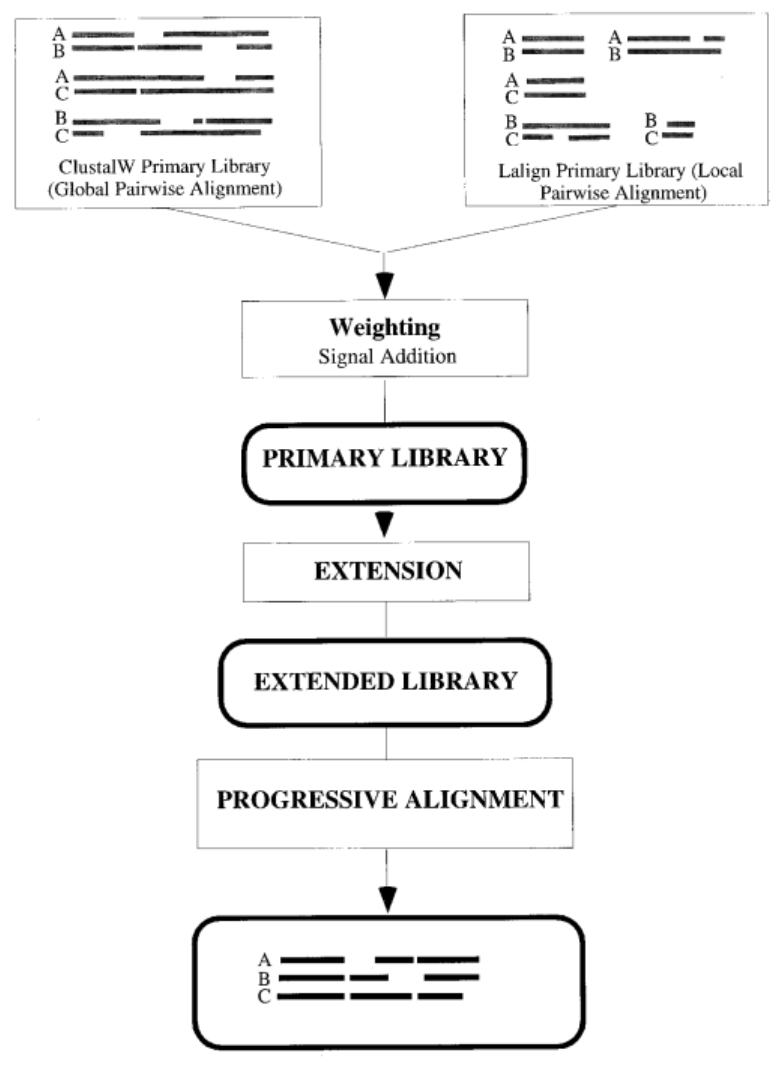
Алгоритм T-Coffee имеет две основные особенности.
Во-первых, он использует
различные источники данных. Данные предоставляются в T-Coffee через библиотеку
парных выравниваний. Может использоваться библиотека,
которая была создана с использованием
смеси локальных и глобальных парных выравниваний
(рис2).
Второй основной особенностью T-Coffee является
метод оптимизации, который используется для
нахождения множественного выравнивания, которое лучше всего соответствует парным
выравниваниям во входной библиотеке. Используется
прогрессивная стратегия, которая похожа на ту, что используется в ClustalW. Но в данном случае мы используем информацию
в библиотеке для выполнения прогрессивного выравнивания
таким образом, который позволяет нам учитывать выравнивания
между всеми парами, пока мы выполняем каждый шаг
множественного выравнивания. То есть при добавлении новой последовательности, она
выравнивается попарно со всеми уже выровненными. Поэтому, ошибки, которые возникали до этого, могу быть исправлены.
Это дает
нам прогрессивное выравнивание с характерной для него сокростью и простотой, но с гораздо меньшей тенденцией совершать ошибки
(т.к. у нас есть возможность рассматривать информацию из всех последовательностей
на каждом шаге выравнивания, а не только тех,
которые выравниваются на этом этапе).
Рис 2. Алгоритм T-Coffee. Основные шаги. (Квадратные блоки — процедуры, круглые — базы данных)