Сигналы и мотивы
Описание мотива в белках паттерном
Мы решили поискать мотив в белках RpoA. Это альфа-субъединица РНК-полимеразы. Он играет важнейшую роль в её сборке, узнавании промоторов и взаимодействии с регуляторными белками, обеспечивая инициацию транскрипции. Файл с девятью мнемониками
Скачали 9 фаста последовательностей по мнемоникам типо sw:RPOA_*, из файла ENTRIES:
seqret -filter 'list::ENTRIES' -outseq query.fasta
Выровняли MSAProbs в программе JalView. Файл с выравниванием
Нашли примерно посередине белка консервативный блок длиной 14 аминокислот:
40 - 53 в выравнивании
В белке RPOA_BARHE это аминокислоты с 32 до 45
По данной последовательности можно составить следующий мотив:
P-[LF]-E-[RPKA]-G-[FYL]-[GA]-x-T-[LV]-[GA]-[NH]-x-L

Запустили fuzzpro:
fuzzpro -sequence /P/y24/term4/bacteria-sw.fasta -pattern "P-[LF]-E-[RPKA]-G-[FYL]-[GA]-x-T-[LV]-[GA]-[NH]-x-L" \n -outfile motifs_rpa.txt
466 находок, a в UniProtKB 628 результатов по запросу (id:RPOA_*) AND (taxonomy_id:2). Какие-то не нашлись. Попробуем ослабить паттарн: P-[LF]-E-x-G-x-[GA]-x-T-[LV]-[GA]-[NH]-x-L — 514 находок с мнемоникой RPOA_* P-[LF]-E-x-G-x-[GA]-x-T-x-[GA]-[NH]-x-L — 547 находок. Остановимся на этом результате, потому что дальнейшее ослабление паттерна делает его не очень релевантным. При всех паттернах находятся только последовательности с нужной мнемоникой RPOA.
Поиск мотивов в белках программой MEME и поиск этих мотивов в банке
Запустили MEME. Она поищет мотивы в белках:
meme rpa.fasta -protein -mod oops -nmotifs 3 -minw 8 -maxw 15 -oc meme_out
-protein — последовательности аминокислотные -mod oops — если мотив встретился несколько раз в одной последовательности, считать за один -nmotifs 3 — количество найденных мотивов в одной последовательности -minw 8 -maxw 15 — минимальная и максимальная длина мотива -oc meme_out — указание папки для выходных файлов
Два главных файла в выдаче MEME: meme.txt meme.html
Запустили MAST. Он поищет мотивы, которые нашёл MEME, в базе всех белков бактерий:
mast meme_out/meme.txt /P/y24/term4/bacteria-sw.fasta -oc mast_out
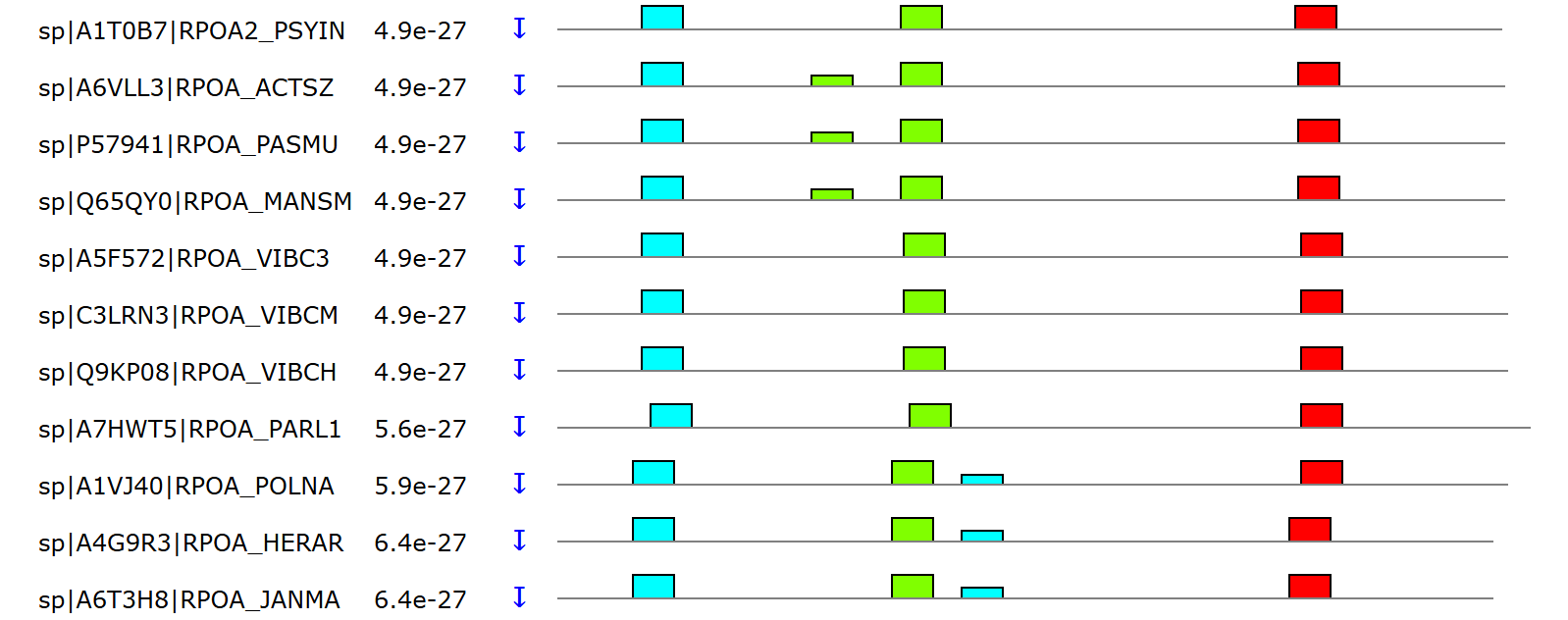
На странице с выдачей MAST указано, что 655 последовательнонстей имеет E-value < 10. А также что показанные совпадения мотивов имеют p-value для позиции меньше 0,0001. Это очень хорошо. По блоковой диаграмме видно, что зелёный мотив (GVEILNPDHHIATLN) может встретиться дважды. Вариативный повтор следует до основного. Голубой мотив (PLERGYGYTLGNSLR), который мы нашли глазами в первом задании, может встретиться второй раз, после зелёного (GVEILNPDHHIATLN). Последним в находках с верной мнемоников всегда идёт красный (EDLDLSVRSYNCLKR) домен.
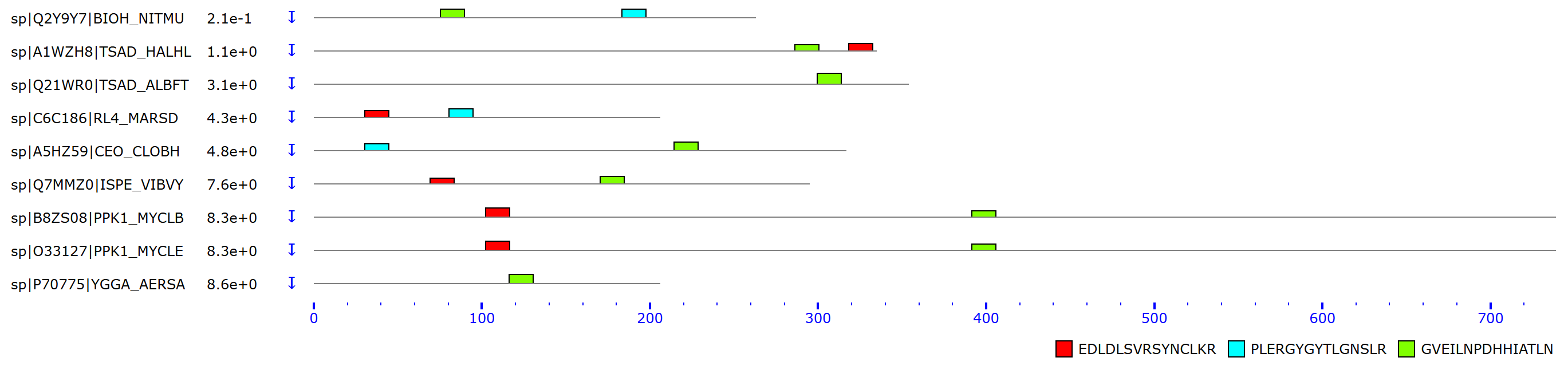
Последняя находка с нужной мнемоникой имеет E-value 2.3e-5. Всего их 646, есть ещё 9 находок других белков с E-value более чем 2.1e-1 ≈ 0,21.
Поиск последовательности Шайна — Дальгарно в геноме своего прокариота
Последовательность Шайна—Дальгарно это рибосом-связывающий сайт у бактерий — короткий сигнал перед старт-кодоном (сигнал потому что ПШД это мотив, который узнаётся рибосомой). Обычно это AGGAGG ~в 10 п.о. от старт-кодона.
Мы будем анализировать скачанный в первом семестре геном бактерии Bartonella krasnovii
Всего CDS в скачанном геноме 1790. CDS without_protein всего 81. Это различные РНК и псевдогены.
Поискали паттерн AGGAGG на (+) и (-) цепи:
fuzznuc -sequence ~/term1/genome/GCF_003606345.3_ASM360634v3_genomic.fna -pattern AGGAGG -complement N -outfile plus.txt fuzznuc -sequence ~/term1/genome/GCF_003606345.3_ASM360634v3_genomic.fna -pattern CCTCCT -complement N -outfile minus.txt
На плюс цепи 424 находок + 362 на минус цепи = 786 находок. То есть по этой оценке мы нашли примерно 786 белков с последовательностью Шайна—Дальгарно среди всех CDS (1790 штук).
Различие частоты находок сигнала в геноме и случайного совпадения тех же букв.
Программой compseq посчитали частоты нуклеотидов. Из выдачи, нам нужна графа Obs Frequency То есть, согласно этим частотам, вероятность получить последовательность AGGAGG, если это случайные независимо распределённые буквы: P(AGGAGG) = P(A)2 * P(G)4 = (0.3132427)2 * (0.1905419)4 = 12,9 * 10-5. А количество находок в геноме тогда: P(AGGAGG) * длина генома * 2 (за две цепи)= 12,9 * 10-5 * 2186621 * 2 = 564
Однако мы нашли 786, что в 1,4 раза больше, чем 564.
При больших n и маленьких p биномиальное распределение апроксимируется Пуассоновским. При λ = 564 и наблюдаемом числе сайтов k = 786 z критерий составляет : z ≈ (786 - 564) / 23.75 ≈ 9.35 Поскольку z >> 1.96 ( при стандартном пороге alpha = 0.05), формально это большое отклонение и это не случайные буквы в геноме. Мы должны отвергнуть нулевую гипотезу о том, что наблюдаемое число сайтов последовательности Шайна-Дальгарно соответствует случайному ожиданию. Наблюдаемое число сайтов значимо превышает то, которое стоило бы ожидать при случайном распределении нуклеотидов, что говорит о том, что это сигнал, а не случайный набор букв.
Находки, располагающиеся в правильной позиции
Последовательности Шайна-Дальгарно есть не у каждого гена белка. Например, среди находок на реальную поселедовательность ШД похожи следующие:
начало ПШД начало CDS 41971 41 982 98425 98 437остальные лежат дальше 20 нуклеотидов от начала CDS в некодирующих областях генома.
В целом, после просмотра предсказанных мотивов стало понятно, что большинство предсказанных находок лежат в некодирующих частях, то есть не являются истинными ПШД.