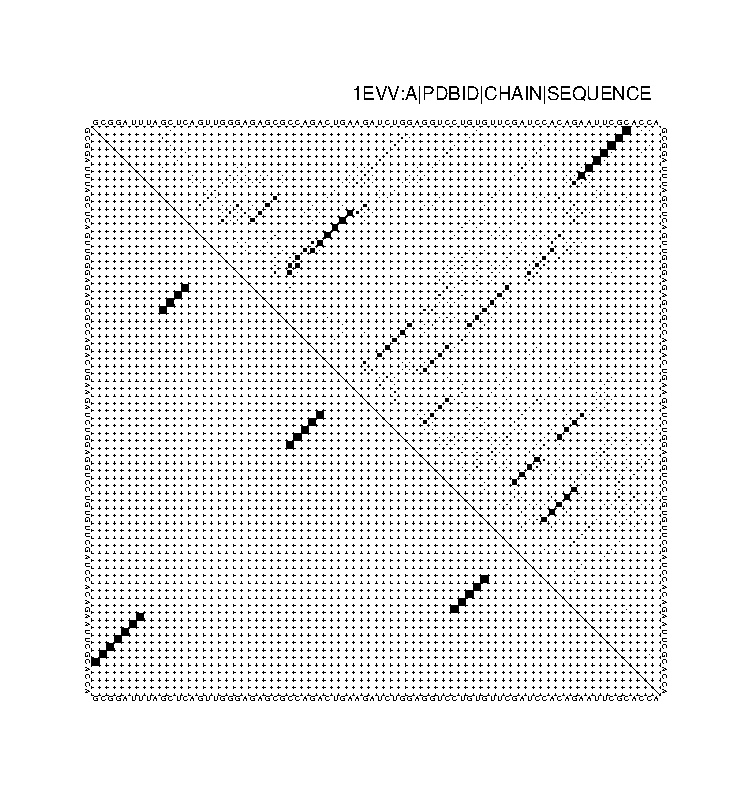
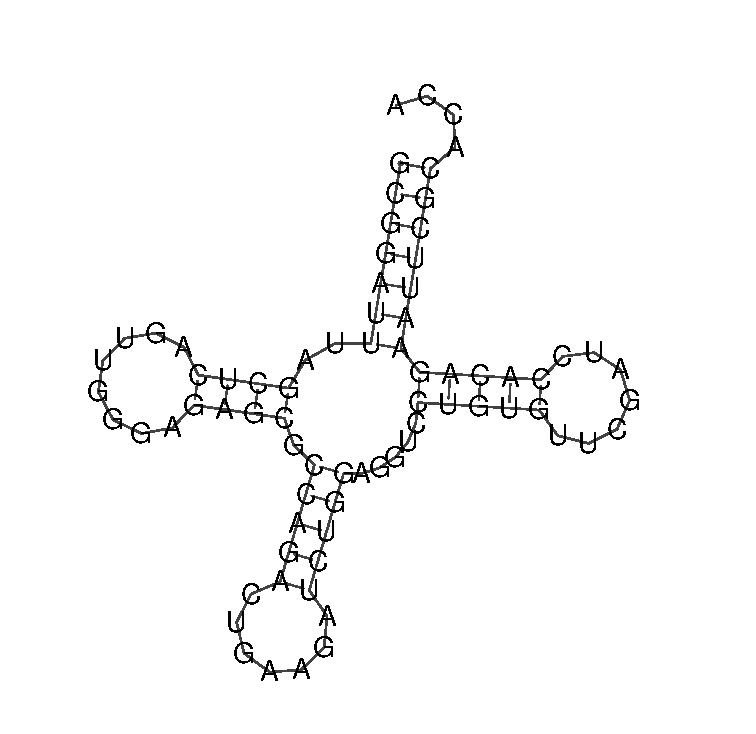
Не знаю какое именно изображение нужно?
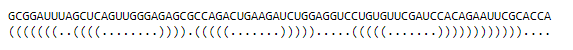
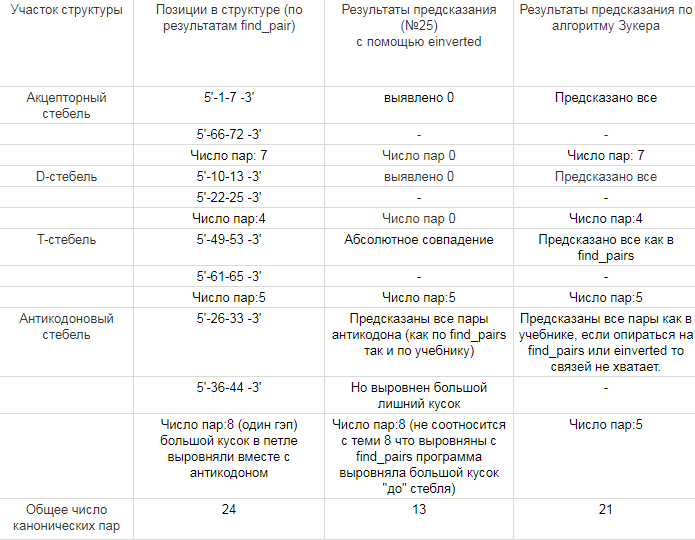
Таблица. Контакты разного типа в комплексе 1cf7.pdb

Из таблицы видно, что контактов с остатками фосфорной кислоты больше всего. Это объясняется тем, что остатки находятся ближе всего к "поверхности" ДНК. На втором месте контакты с пятиуглеродным сахаром, что объясняется той же причиной что и большое число контактов с фосфорной кислотой. А вот контактов с азотистыми основаниями намного меньше-это все происходит потому, что они "ввернуты" внутрь молекулы. Контактов с атомами азотистых оснований, которые смотрят на большую бороздку заметно больше, чем с смотрящими в малую. Оно и понятно, при взаимодействии с первыми, происходит меньшее стерическое отталкивание атомов друг от друга, и молекула белка способна "проникнуть" в бороздку.
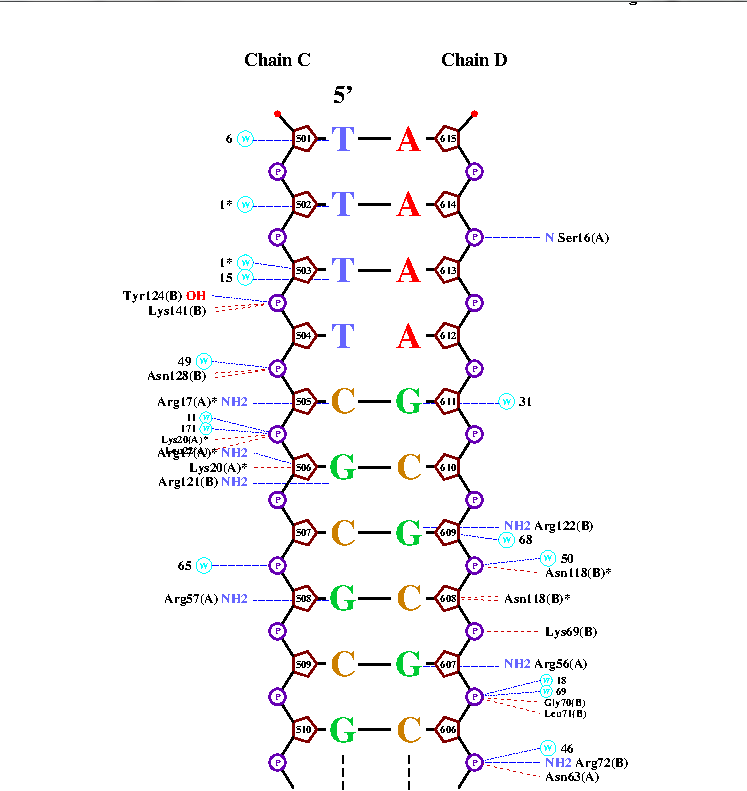
Аминокислотный остаток, который больше всего контактирует с ДНК-это Lys20(A) и Arg17(A) они имеют по 2 взаимодействия с белком.
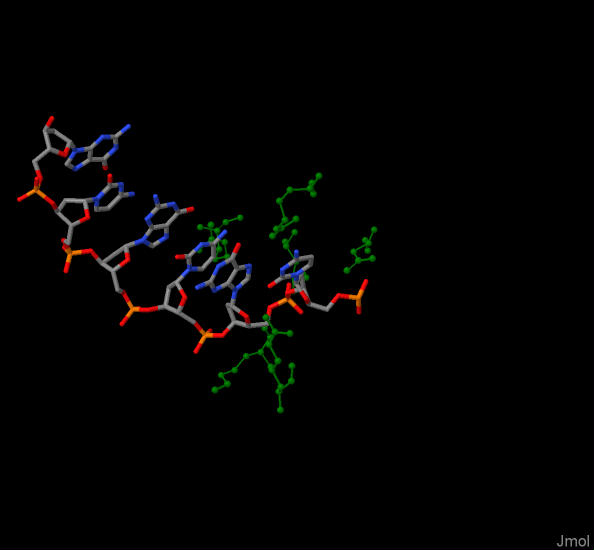
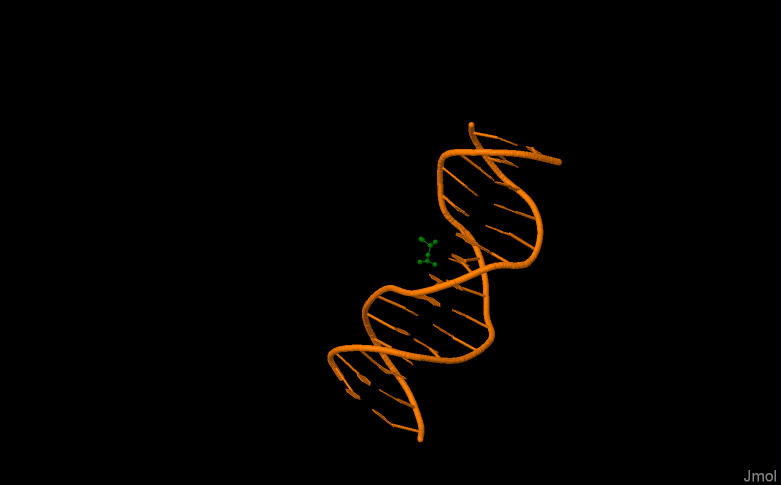
Думаю наиболее важная аминокислота для распознования последовательности Arg17:A. В PubMed Abstract написано, что удлинение сайта распознования c/gGCGCg/c (в моей последовательности она также встречается cGCGCg [505-510]) с помощью закрученной последовательности TTTc соответственно удлиняет E2F белок аргинином (Arg17). Думаю именно эта аминокислота помогает узнавать последовательность ДНК. (pic1) Также там написано, что все аминокислоты контактирующие с c/gGCGCg/c-распознавательным центром сохраняются теми же у всех E2F и DP белков. Таким образом этот отрезок узнают аминокислоты Asn128(B), Arg17(A), Lys20(A), Leu22(A), Arg17(A), Arg121(B), Arg57(A).(pic2,3). Если смотреть на выдачу программы nucplot на файл *.bond то можно заметить что самая встречающаяся аминокислота-это Asn118:В. Она трижды встречается в несвязывающих контактах.(PIC3)
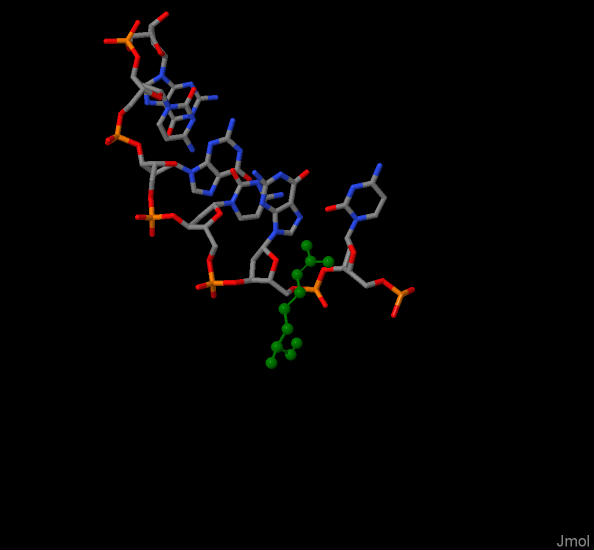
PIC1. На картинке зеленым цветом показан Arg17:A, а все остальное- это участок связывания cGCGCg
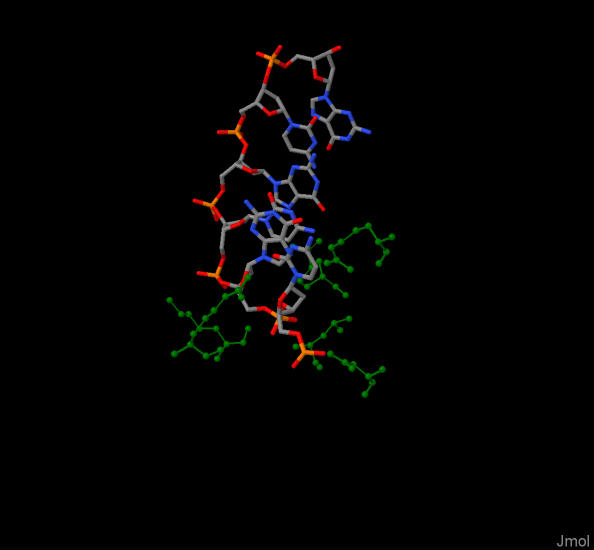
PIC3. На картинке зеленым показаны вышеперечисленные аминокислоты, которые окружили cGCGCg
PIC2. Аналогично PIC2, но с другого ракурса.
PIC3. Зеленым показана амиокислота Asn118:В