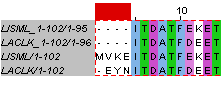
2_iv - локальное выравнивание, построенное программой water
2_v - глобальное парное выравнивание, построенное программой needle со штрафом за открытие гэпов 6.0, а не 10.0
2_vi - локальное парное выравнивание, построенное программой water со штрафом за открытие гэпа 2.0 и за его продолжение 0.1 вместо стандартных 10.0 и 0.5
2_viii - локальное парное выравнивание этих же белков, построенное программой water
Несколько комментариев по вышеизложенному: во-первых, две последовательности для парного выравнивания были выбраны по опции Remove Redundancy, так как мне не удалось точно выбрать две наименее родственные последовательности по методу главных компонент.
Это оказались последовательности LISML и LACLK, которые, однако, по дереву, построенному в Jalview, довольно близки.
Во-вторых, при снижении штрафа за открытие гэпа в построении глобального выравнивания в нем, как и ожидалось, получилось больше гэпов, чем со страндартным штрафом (рис. 1). Выровнялась еще одна колонка - глутаминовая кислота в 4 позиции.
Рис. 1. Фрагменты глобального парного выравнивания, построенного программой needle: верхний - со стандартными параметрами, нижний - с пониженным штрафом за открытие гэпа.
Для того, чтобы добиться изменений в локальном выравнивании (программа water), пришлось сильно понизить штраф за открытие гэпа, а также штраф за его продолжение. При изменении только штрафа за продолжение гэпа выравнивание не менялось. Как можно увидеть на рис.2, уменьшение штрафов позволило удлинить выравнивание на 3 позиции в начале. Впрочем, в глобальном выравнивании изменения были ровно такие же (по сути, в обоих случаях была добавлена еще одна выровненная колонка), то есть на выравнивание не влияет снижение штрафа за продолжение гэпа (что говорит о том, что выравнивание "хорошее").
Рис. 2. Фрагменты локального парного выравнивания, построенного программой water: слева - со стандартными параметрами, справа - с пониженными штрафами за открытие и продолжение гэпа.
Для выравнивания негомологичных белков были выбраны мой белок антранилат-фосфорибозилтрансфераза (YP_005259411) и белок 2-дегидро-3деоксифосфооктонатальдолаза (YP_001041787). Я решила, что это достаточно далекие друг от друга белки для данной задачи, так как первый белок принадлежит археям, а второй - бактериям, и потом, они принимают участие в разных частях метаболизма.
По глобальному выравниванию (см. jar-файл) видно, что довольно хорошо выровненные позиции получаются за счет создания длинных гэпов.
1. Сравнение глобального выравнивания (needle) и выравнивания, полученного из множественного. В Jalview-проекте вкладка 7_1.
Получился только один участок различия с координатами 48-49 позиции. Остальные колонки двух выравниваний одинаковы. Таким образом, различающихся колонок всего 2. Участки рядом с участком различия представлены на рис.3.
Рис. 3. Фрагмент сравнения глобального выравнивания (2 верхние строки) и выравнивания, полученного из множественного (2 нижние строки). Красным выделен участок различия (48-49 позиции). С обеих сторон от них стобцы, в которых нет различий (по 5): 43-47 позиции слева и 50-54 справа.
2. Сравнение локального выравнивания (water) и выравнивания, полученного из множественного. В Jalview-проекте вкладка 7_2.
Нужно было добавить 4 гэпа в начале локального выравнивания для того, чтобы привести его к виду выравнивания, полученного из множественного. В итоге получилось выравнивание такое же, как в предыдущем пункте (с глобальным), только добавился участок 1-4 позиции, в котором в локальном выравнивании вставлены гэпы, а также участок в конце, который не вошел в глобальное.
Рис. 4. Фрагмент сравнения локального выравнивания (2 верхние строки) и выравнивания, полученного из множественного (2 нижние строки). Красным выделен участок различия (4 первых позиции). Справа есть столбцы, в которых различий нет: первые 5 столбцов - с 5 по 9.
Различающихся колонок в этом выравнивании 9.
Комментарии и выводы о парных выравниваниях
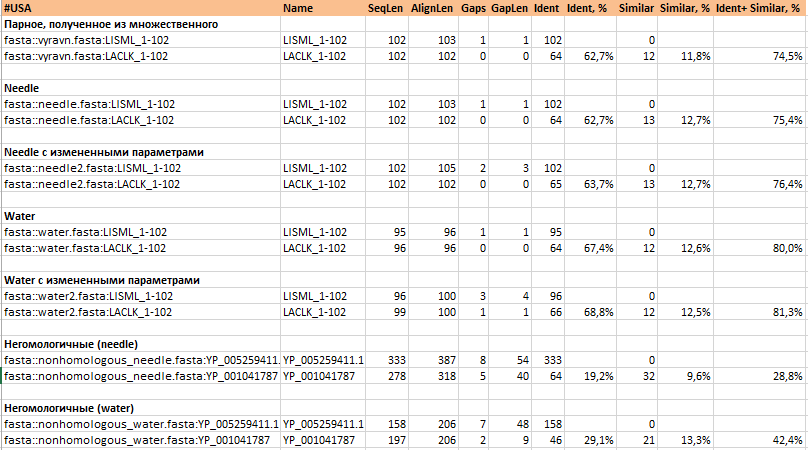
Для анализа парных выравниваний с разными параметрами и разной гомологичностью последовательностей полученные c помощью программы infoalign данные по выравниваниям, построенным в предыдущих заданиях, были сведены в Таблицу 1.
Изначально были взяты очень близкородственные последовательности. Из-за этого, как уже было сказано выше, при несильном изменении параметров для программ парного выравнивания, таких как штраф за открытие гэпа и за его продолжение, выравнивание практически не менялось. Лишь при существенных изменениях в выравнивания добавлялись новые гэпы.
Тем не менее, по небольшой, но устойчивой разнице в процентах можно сказать, что локальное парное выравнивание дает более высокие показатели числа сходных и идентичных колонок, то есть оно лучше. Конкретно в этом случае увеличение консервативности достигается за счет отрезания участка, состоящего из первых 4 позиций, который не консервативны, так как в остальном выравнивания глобальные и локальные (со стандартными параметрами), а так же выравнивание, полученное из множественного, получились одинаковыми.
Увеличение процента сходных и идентичных позиций в парных выравниваниях с измененными параметрами объясняется тем, что я снизила штрафы за гэпы, тем самым позволив вставлять большее их количество в выравнивание, тем самым создавая новые консервативные колонки.
Сравнить выравнивание, полученное из множественного, с выравниваниями, построенными программой, тоже довольно сложно (на основе полученных данных).
В целом можно сказать, что в разных ситуациях может быть удобнее разный тип выравнивания. Если нужно найти какие-то схожие блоки в двух последовательностях, которые, предположительно, будут одинаковы по функциям, то будет удобнее использовать выравнивание, построенное по алгоритму Смита-Ватермана, потому что оно будет находить такие участки.
Для получения общей картины выравнивания двух последовательностей удобнее использовать глобальное выравнивание, оно даст больше информации о возможном родстве белков, об их схожести. Выравнивание, полученное из множественного, будет полезно, если мы знаем, каким было множественное. Во множественном точнее будут выбраны консервативные позиции, входящие в вертикальные блоки, поэтому и в парном консервативные позииции будут достовернее.
Можно сравнить выравнивание гомологичных и негомологичных последовательностей: у последний процент идентичных и сходных колонок примерно в 2 раза меньше, чем у гомологов. Естественно, у локального выравнивания негомологичных белков процент идентичных и сходных колонок гораздо выше, чем в глобальном, так как не учитываются малоидентичные участки.