1QRT
В данных упражнениях мы должны были предсказать структуру тРНК (PDB ID: 1QRT) с помощью программ find_pair, einverted из пакета EMBOSS и RNAfold, реализующей алгоритм Зукера. Результаты предсказания указаны в таблице ниже.
| Участок структуры | Позиции в структуре (find_pair) | Результаты предсказания с помощью einverted | Результаты предсказания по алгоритму Зукера |
| Акцепторный стебель | 5' 2-7 3' 5' 61-65 3' Всего 6 пар |
Предсказано 6 пар из 6 реальных | Предсказано 6 пар из 6 реальных |
| D-стебель | 5’ 10-15 3’ 5’ 25-48 3’ Всего 6 пар |
Предсказано 0 пар из 6 реальных | Предсказано 3 пары из 6 реальных |
| T-стебель | 5’ 49-55 3’ 5’ 18-65 3’ Всего 7 пар |
Предсказано 0 пар из 6 реальных | Предсказано 5 пар из 7 реальных |
| Антикодоновый стебель | 5’ 37-44 3’ 5’ 26-33 3’ Всего 8 пар |
Предсказано 0 пар из 6 реальных | Предсказано 8 пар из 8 реальных |
| Общее число канонических пар нуклеотидов | 27 | 6 | 22 |
Параметры программы:
Вводимая нуклеотидная последовательность:1qrt.fasta
Штраф за гэп [12]: 12
Минимальное значение порога [50]:10 (при выборе 15, 20 или 50 программа выравнивание не находит)
Значение основания (канонической пары) [3]:3
Значение неканонической пары("несоответствие") [-4]:-4
Выходной файл – sequence.inv
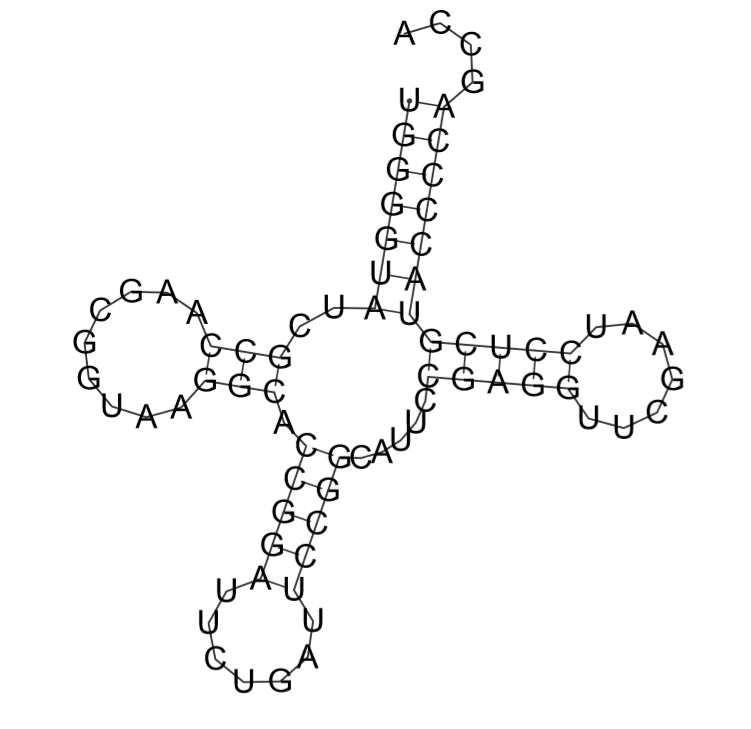
Программа RNAfold, использующая алгоритм Зукера, оказалась более эффективной в предсказании вторичной структуры тРНК, что показыают результаты сравнения ее деятельности с остальными двумя. Внизу представлено сгенерированное ей изображение:
1QRT
| Контакты атомов белка с | Полярные | Неполярные | Всего |
| остатками 2'-дезоксирибозы | 4 | 89 | 93 |
| остатками фосфорной кислоты | 14+74=88 | - | 88 |
| остатками азотистых оснований со стороны большой бороздки | 0 | 8 | 8 |
| остатками азотистых оснований со стороны малой бороздки | 0 | 2 | 2 |
Схема ДНК-белковых контактов, полученная с помощью nucplot
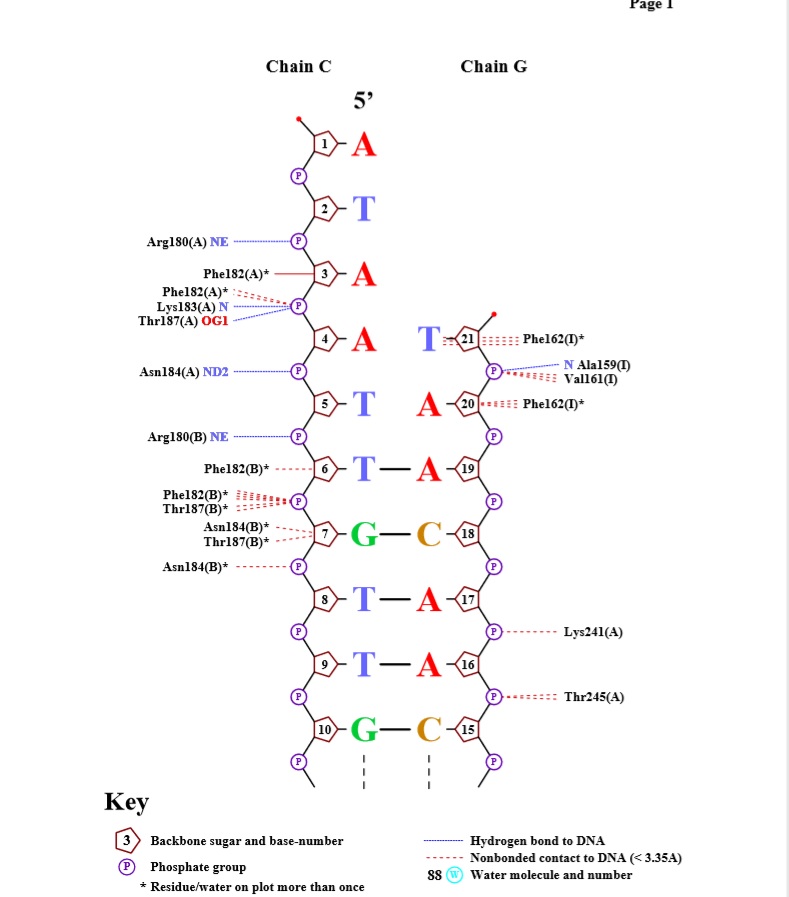
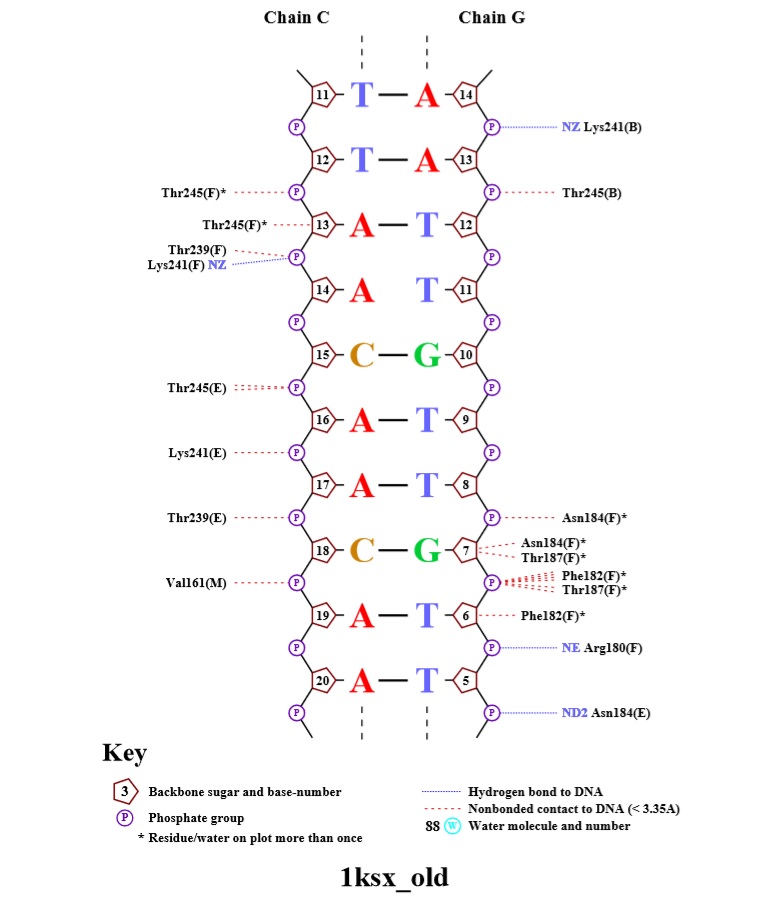
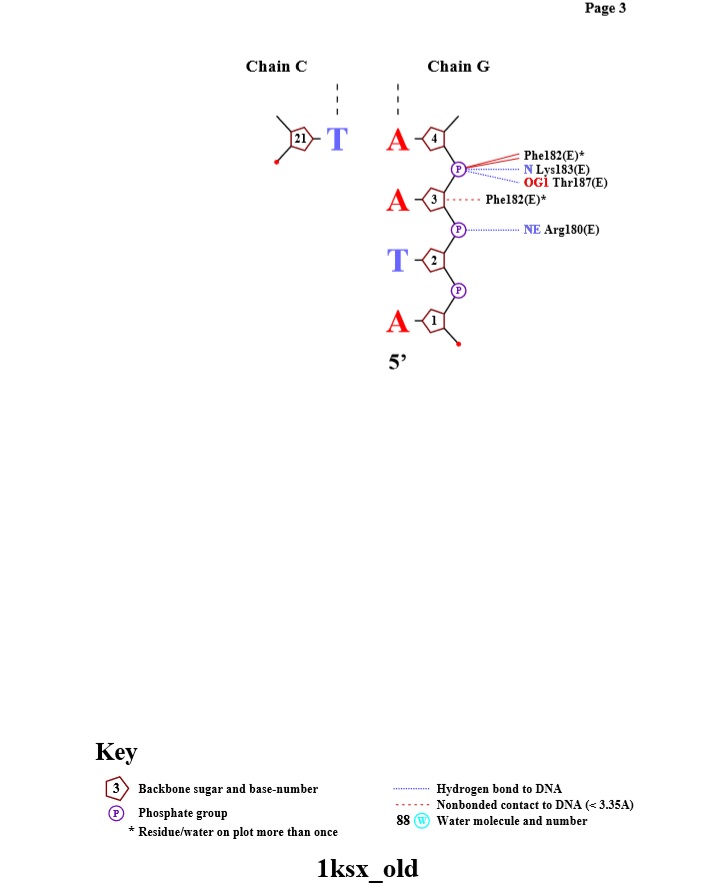
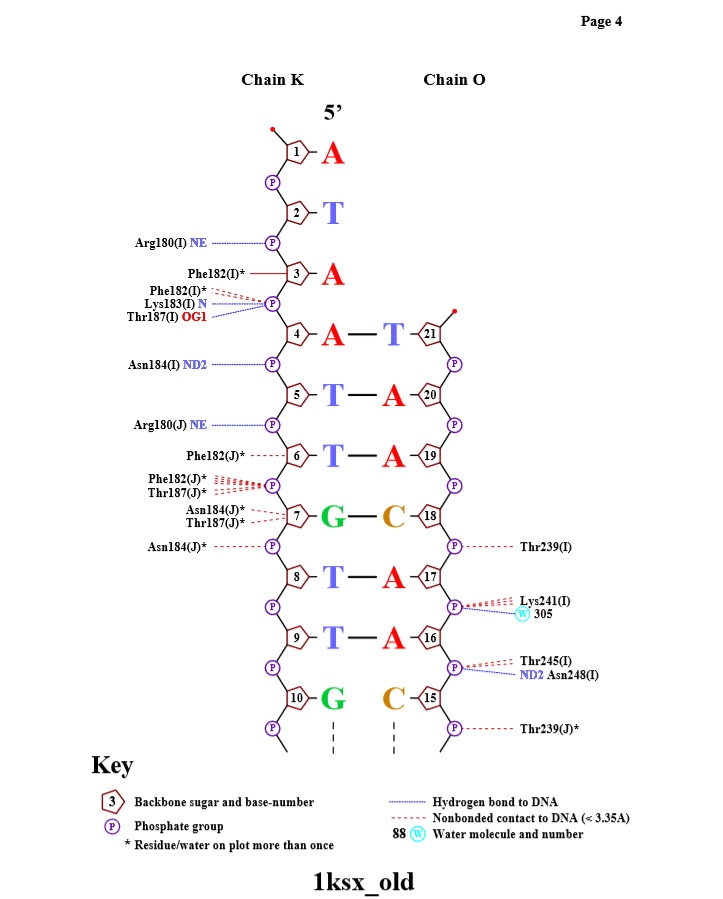
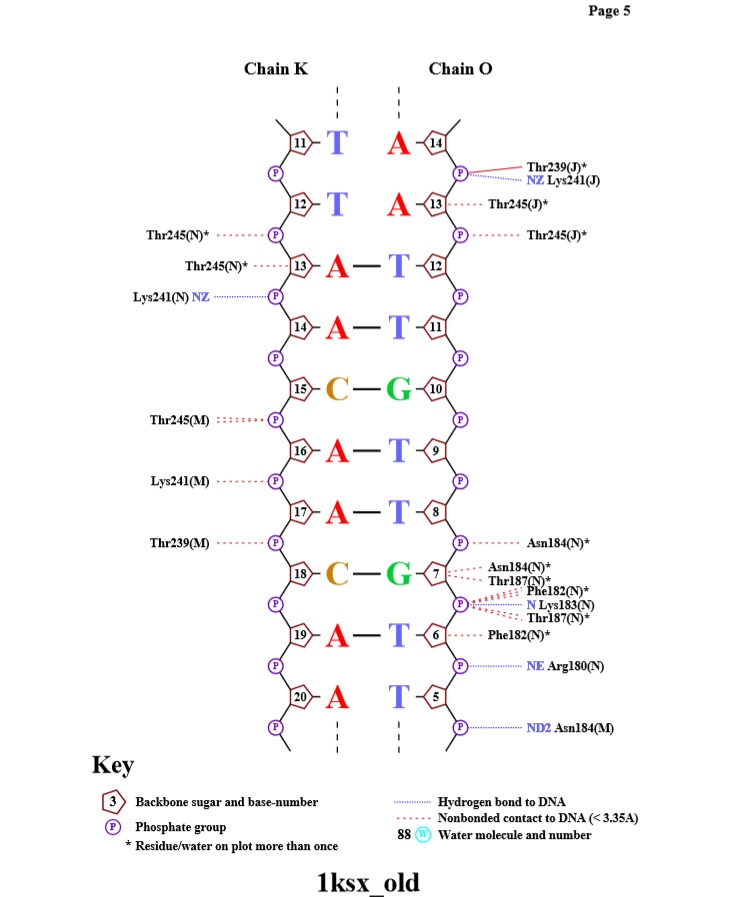
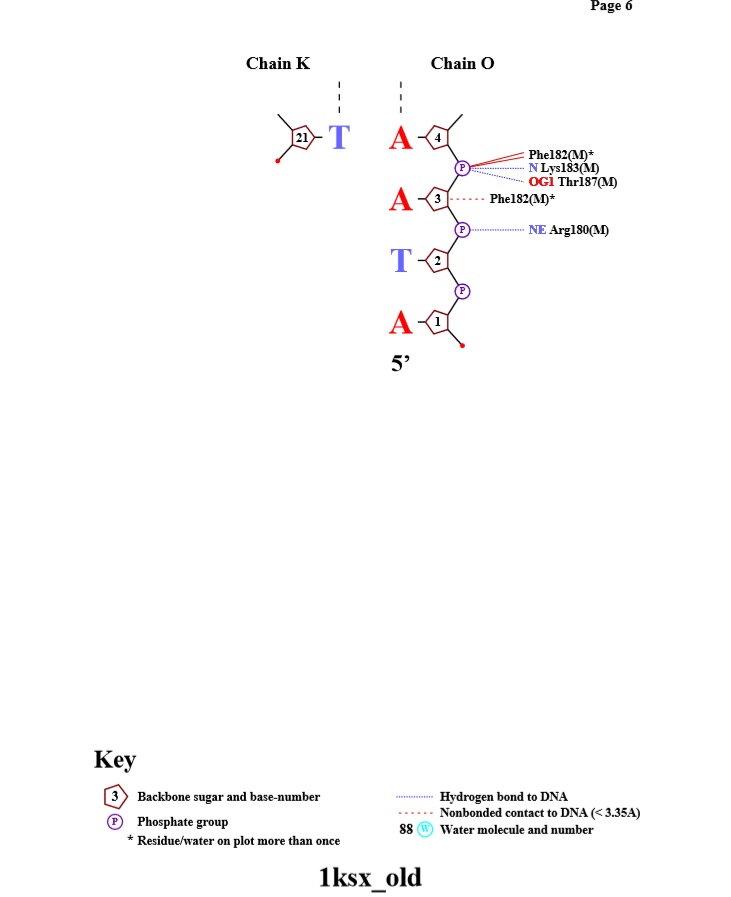
Наибольшее число контактов (7) с ДНК имеют аминокислотные остатки - PHE J 182 и PHE I 162. Таким образом, можно предположить, что это наиболее важные аминокислотные остатки для распознавания последовательности ДНК.
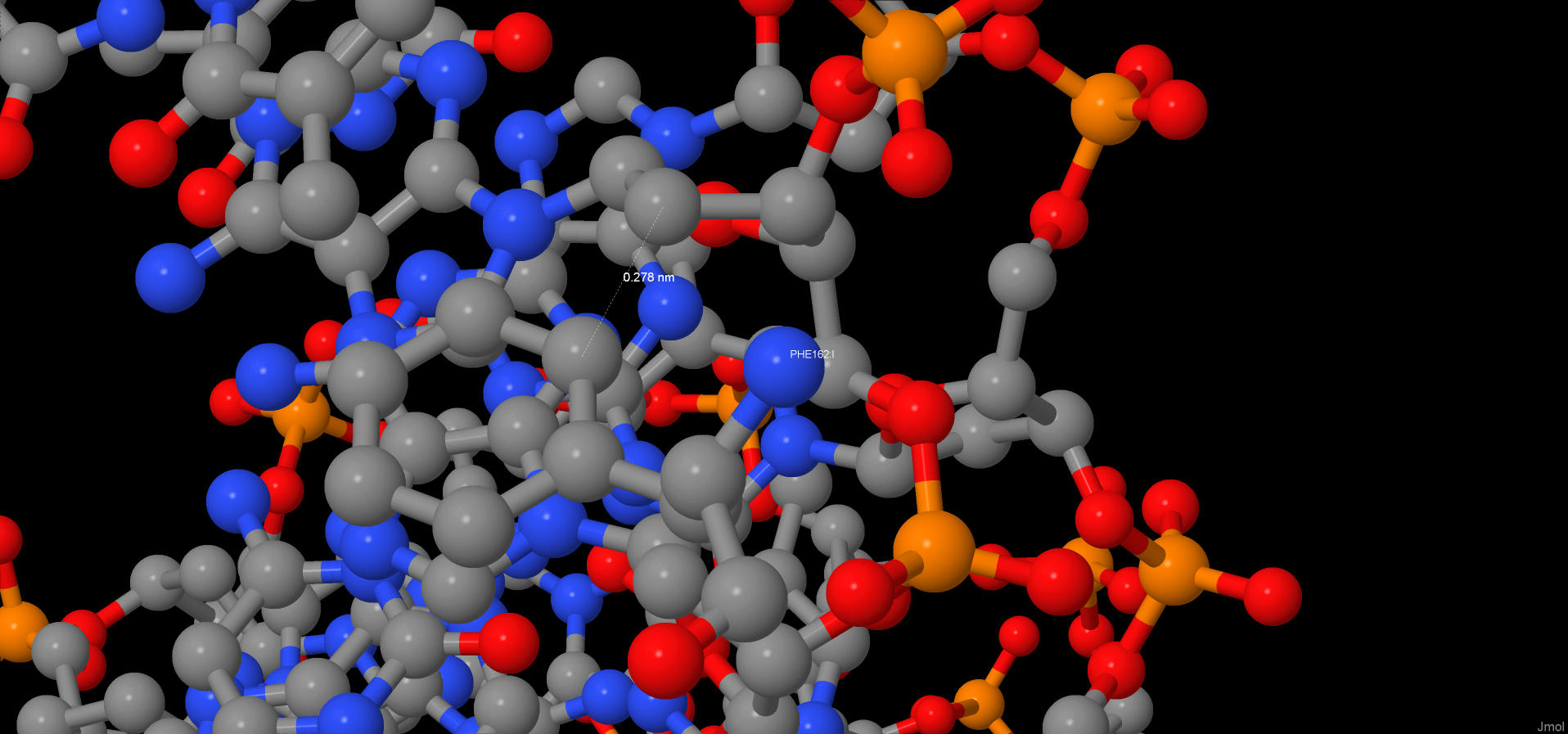
PHE I 162
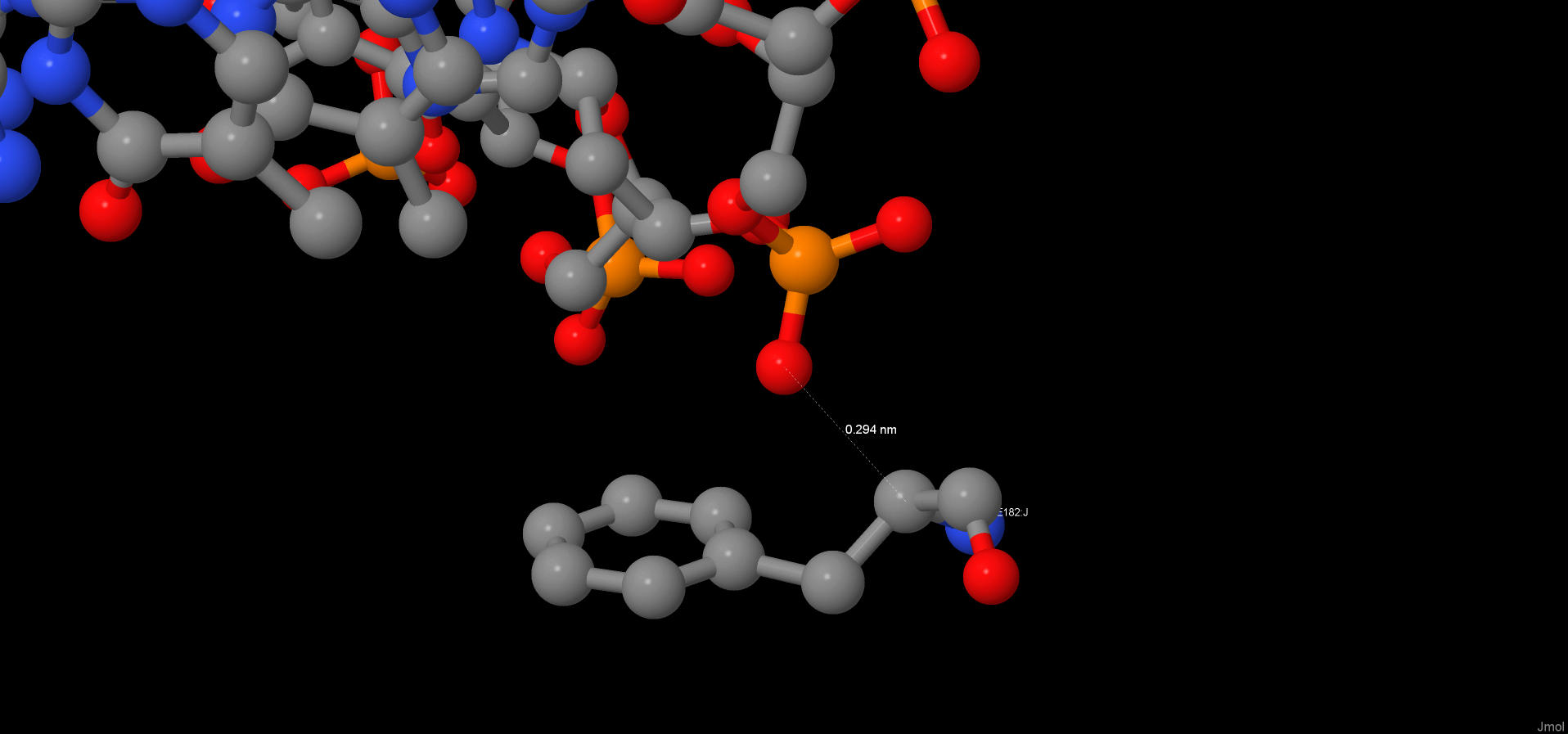
PHE J 182
© Макиевская Кьяра, 2018