Практикум 12. Алгоритмы и программы множественного выравнивания
Алгоритм сравнения разных выравниваний одних и тех же последовательностей
Программа для сравнения разных выравниваний одних и тех же последовательностей была написана совместно с Грошевой Софьей.
Программа запускается из командной строки след. образом:
> python alignment.py
С опцией -h выдается информация о том, как запустить программу и требования ко входным данным:
usage: alignment_MK_GS.py [-h] [-o O] file1 file2
positional arguments:
file1
file2
options:
-h, --help
-o O
Выходной файл содержит список (i, j) одинаково выровненных колонок.
Работа программы была проверена на выравниваниях, которые использовались для выполнения задания в классе( PF00145_seed-reduced и PF00145_seed-tcoffee-reduced ).Вывод нашей программы проверялся вручную в Jalview. Было установлено, что программа работает верно.
В stdout выводится длина первого и второго выравниваний, % одинаково выровненных колонок, одинаково выровненные блоки.
Сравнение выравниваний одних и тех же последовательностей тремя разными программами A, B, C
В качестве последовательностей были взяты последовательности seed домена PF04622, который использовался в прошлом практикуме. Выравнивания были сделаны в JalView и сравнены с помощью написанного нами ранее скрипта. В качестве выравнивания А было выбрано Tcoffee, B - Muscle, C - Mafft.
| Список блоков одинаково выровненных колонок | (32,48)=(31,47), (77,89)=(76,88), (95,104)=(93,102), (111,118)=(109,116), (152,190)=(135,173), (195,211)=(177,193), (216,219)=(198,201), (222,241)=(204,223), (243,246)=(225,228), (248,288)=(230,270), (290,292)=(272,274) |
| Список одинаково выровненных колонок, не входящих в блоки | (214)=(196) |
| Количество совпадающих колонок | 177 |
| Процент одинаково выровненных колонок первого выравнивания: | 59.6 |
| Процент одинаково выровненных колонок второго выравнивания: | 63.44 |
| Список блоков одинаково выровненных колонок | (30,45)=(33,48), (77,89)=(78,90), (95,104)=(95,104), (113,114)=(113,114), (119,123)=(119,123), (152,190)=(137,175), (195,205)=(179,189), (222,241)=(209,228), (243,246)=(230,233), (248,288)=(235,275), (290,292)=(277,279) |
| Список одинаково выровненных колонок, не входящих в блоки | - |
| Количество совпадающих колонок | 164 |
| Процент одинаково выровненных колонок первого выравнивания: | 55.22 |
| Процент одинаково выровненных колонок второго выравнивания: | 57.75 |
Мы видим, что на Tcoffee больше всего похоже выравнивание Muscle, это видно по количеству совпавших колонок и проценту одинаково выровненных колонок. Также можно заметить, что во второй паре выравниваний все колонки образуют блоки и отдельных колонок нет.
Выравнивание по совмещению структур
Для выполнения задания я выбрала три белка из домена PF04622: 8w4b, 7w2h, 5hk1 (были взяты А-цепи). С помощью PDBeFold было получено совмещение 3D-структур и соответствующее выравнивание. Также я сделала выравнивание последовательностей с помощью программы Tcoffee.
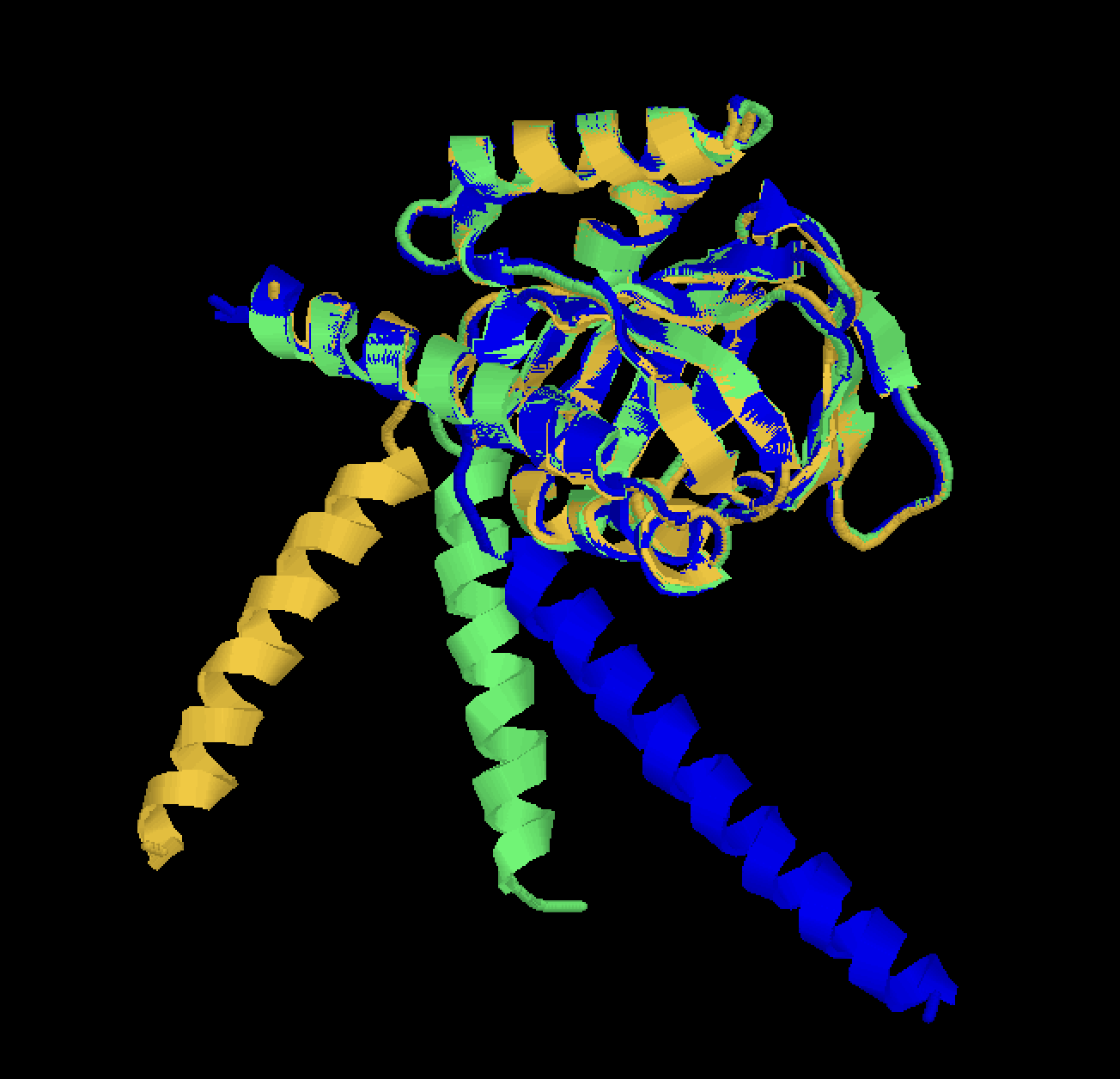
Можно увидеть, что выравнивания полностью совпали. Такой результат говорит о высокой степени консервативности домена как на уровне первично структуры, так и на уровне пространственной укладки. Мы видим, что гомологичные позиции, полученные из структурного выравнивания могут быть найдены и без исследования 3D-структуры. Получается, что выбранные белки действиетльно близки эволюционно.
Краткое описание программы MSA.
T-Coffee (Tree-based Consistency Objective Function for Alignment Evaluation) - это прогрессивный метод множественного выравнивания последовательностей, главной особенностью которого является использование принципа согласованности.
Алгоритм работы
1. Программа составляет библиотеку парных выравниваний всех возможных пар последовательностей, причем делает это и глобально, и локально.
2. Сравнивает две последовательности через третью (проверяет согласованность и взвешивает ее).
3. На основе полученных весов строит множественное выравнивание
T-Coffee дает более точные выравнивания, особенно для эволюционно удаленных последовательностей. Кроме того, она может интегрировать дополнительную информацию, например принимать аннотации или структурные выравнивания. Однако на больших массивах данных T-Coffee работает медленно по сравнению с такими программами как MUSCLE или MAFFT, однако на маленьких наборах последовательностей она является практически самой оптимальной.