Работа в BLAST.
Параметры запуска Blast- Max target sequences=20000 - устанавливает максимальное количество искомых последовательностей. Поиск ведётся до не более чем 20000 сходных последовательностей.
- Short queries(Automatically adjust parameters for short input sequences) - в случае поиска коротких последовательностей имеет смысл использовать другие параметры по умолчанию, нежели в случае длинных. Эта кнопка позволяет использовать эти параметры.
- Expect threshold - порог статистической значимости. Последовательности с большим в данном случае 10 E-value не показываются.
- Word size - изначально последовательности, в которых ищутся гомологии, выбираются по наличию идентичных или сходных слов с имеющимися в запросе. Чем больше длина слова, тем уже выборка, по которой ищутся гомологичные последовательности и тем быстрее будет работать алгоритм.
- Matrix - устанавливает вес для выровненных пар.
- Gap Costs - Existence: устанавливается штраф за появление нового гэпа, Extension: устанавливается штраф за удлиннение. Так, при цене появления 11 и цене расширения 1 итоговый штраф за 2 индела длины 2 равен 24.
- Compositional adjustments - вводит поправки в таблицу замен букв, улучшающие вычисление E-value
- Filter(Low complexity regions) - области малой сложности, в которых подсчёт гомологичности работает некорректно, например, в GR-богатых участках, забиваются "иксами"
- Mask for lookup table only - маскировка областей малой сложности "иксами" идёт только на шаге поиска возможно гомологичных последовательностей(см. word size), в выводы иксов нет
- Mask Lower Case - вместо X замаскированные участки отмечаются нижним регистром
 Выравнивание целиком можно посмотреть здесь.
Выравнивание целиком можно посмотреть здесь.
Карта сходств двух белков
Были выбраны 2 белка: V2XV70_MONRO(Folic acid synthesis protein) и S7RMD1_GLOTA(Tetrahydrobiopterin biosynthesis enzymes-like protein), для них построена карта сходств.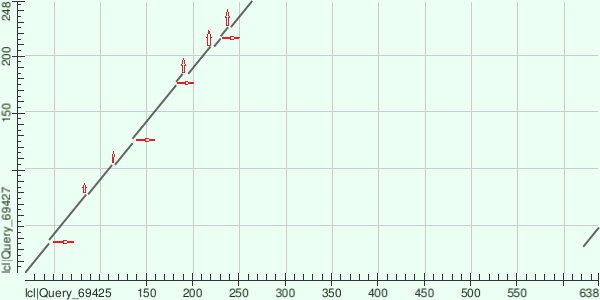
Как видно из карты, имеется длительный выровненный участок с маленькими делециями(инсерциями). Красные стрелки указывают, в каком белке произошла делеция: в соответствующем горизонтальной или вертикальной оси. Есть 3 объяснения участка в конце: либо в предковом белке произошла дубликация, а затем в одном из белков роизошла крупная делеция; либо дубликация и инсерция произошли в одном из белков уже после дивергенции; либо же это артефакт и в одном из белков просто произошла делеция.
Всякое разное.
Поиск по произвольной последовательности.
Blast не дал ничего при запросе "for i will consider my cat jeoffry", даже при повышении порога E-value до 100. Но при изменении длины слова на 2 нашлось несколько последовательностей с E-value от 5.9Вариации работы Blast
При изменении Max target sequences с 20000 до 100 кроме собственно изменения числа полученных последовательностей(с 906 до 100 лучших) не меняется ничего, даже время работы. Видимо, большая часть времени тратится на поиск возможных гомологов(см. word size)При изменении Expect threshold с 10 до 50 число найденых последовательностей немного увеличивается за счёт неродственных последовательностей.
При изменении Word size с 6 до 2 время работы увеличивается, количество находок увеличилось с 906 до 5841 последовательностей, увеличение произошло во всех значениях E-value, особенно в области высоких значений При изменении Matrix с BLOSUM62 на PAM70 набор лучших гмологий изменился слабо, но E-value изменилось: больше ни у одной последовательности оно не было равно 0. Самые худшие последовательности из найденных изменились, общее же число находок немного возросло, вероятно, по случайным причинам. При изменении Compositional adjustments с Conditional compositional score matrix adjustment на no adjustment произошло примерно то же самое: E-value было иначе рассчитано, лучшие последовательности его изменили, но остались в топе, худшие сменились Filer low complexity regions не меняет ничего Оба варианта mask несколько меняют набор находок, количество их уменьшается на 1, E-value сохраняющихся не меняется