Программа getorf пакета EMBOSS
Сначала необходимо загрузить файл с записью D89965 из банка EMBL с помощью команды entret:
entret embl:d89965 -outfile d89965.entret
Получится файл d89965.entret. После этого необходимо получить набор трансляций всех открытых рамок считывания данной последовательности, отвечающих следующим требованиям:
- длиной не менее 30 аминокислотных остатков, то есть не менее 90 нуклеотидов (-minsize 90),
- считая открытой рамкой последовательность триплетов от старт-кодона до стоп-кодона (-find 1),
Для этого выполнить следующую команду:
getorf -minsize 90 -find 1 d89965.entret d89965.orf
Получится файл d89965.orf, содержащий 5 найденных открытых рамок считывания. Сравнив найденные рамки считывания с кодирующей последовательностью, приведённой в поле FT /translation записи D89965 из EMBL, видно, что третья найденная открытая рамка считывания (163 - 432) полностью соответствует кодирующей последовательности с координатами 163 - 435, несмотря на разницу в длине.
Данная запись EMBL ссылается на запись P0A7B8 в Swiss-Prot (/db_xref="UniProtKB/Swiss-Prot:...). Загрузить последовательность этой записи можно с помощью команды:
seqret sw:P0A7B8 P0A7B8.fasta
Получится файл P0A7B8.fasta. Чтобы выяснить, какой из полученных ранее открытых рамок считывания соответствует последовательность P0A7B8.fasta, можно воспользоваться программой blastp:
blastp -query P0A7B8.fasta -subject d89965.orf -evalue 0.01 -outfmt 6 -out P0A7B8_in_d89965_blastp.out
Получится файл P0A7B8_in_d89965_blastp.out. В нем с заданным порогом остается только одна находка: D89965_5 ([294 - 1] (REVERSE SENSE) Rattus norvegicus mRNA for RSS, complete cds). То есть можно сказать, что последовательность записи P0A7B8 соответствует пятой найденной открытой рамке считывания (294 - 1).
Последовательностью записи Swiss-Prot (P0A7B8), на которую ссылается данная запись EMBL (D89965):
>HSLV_ECOLI P0A7B8 ATP-dependent protease subunit HslV (3.4.25.2) (Heat shock protein HslV) MTTIVSVRRNGHVVIAGDGQATLGNTVMKGNVKKVRRLYNDKVIAGFAGGTADAFTLFEL FERKLEMHQGHLVKAAVELAKDWRTDRMLRKLEALLAVADETASLIITGNGDVVQPENDL IAIGSGGPYAQAAARALLENTELSAREIAEKALDIAGDICIYTNHFHTIEELSYKA
Пятая найденная в нуклеотидной последовательности D89965 открытая рамка считывания:
>D89965_5 [294 - 1] (REVERSE SENSE) Rattus norvegicus mRNA for RSS, complete cds. MKGNVKKVRRLYNDKVIAGFAGGTADAFTLFELFERKLEMHQGHLVKAAVELAKDWRTDR MLRKLEALLAVADETASLIITGNGDVVQPENDLIAIGS
Примечание. Запись D89965 из банка EMBL содержит последовательность мРНК крысы, а запись P0A7B8 из банка Swiss-Prot, на которую есть ссылка в записи D89965, содержит последовательность субъединицы HslV АТФ-зависимой протеазы кишечной палочки.
Вывод: последовательность P0A7B8 из банка Swiss-Prot имеет неправильную аннотацию из-за того, что вероятно эксперимент был поставлен неправильно. Исследователи искали белок с определенными свойствами в эпителии желудка крысы. После того, как они заметили активность белка со свойствами, похожими на свойства искомого, ученые выделили и секвенировали мРНК. Однако до этого, последовательность подобного белка уже была известна и хранилась в Swiss-Prot (принадлежала бактерии E.coli), поэтому найденная последовательность была проаннатирована автоматически. Тем самым получается, что белок, полученный из желудка крысы, на самом деле принадлежал E.coli, и, следовательно, авторы проаннотировали найденный белок неверно.
Файлы-списки
С помощью следующей последовательности команд программ пакета EMBOSS: Скачала в файл adh.fasta в fasta-формате все доступные в Swissprot последовательности алкогольдегидрогеназ: их идентификаторы описываются выражением adh*_*. Получила файл с универсальными адресами (USA) этих последовательностей: использовала программу infoseq с параметрами -only и -usa. Получила пример файл-список. Получила из этого файла-списка другой, меньший, с адресами только тех последовательностей, которые взяты из моих организмов. Использовала программу grep с параметром -f, чтобы подать ей на вход список слов для поиска. На основе нового файла-списка получила fasta-файл с последовательностями дегидрогеназ моих организмов. Использовала программу seqret. Список использованных команд ниже.
entret sw:adh*_* выбрала имя файла adh.fasta infoseq -only -usa adh.fasta > list grep -f organisms list > list2 seqret @list2 seq.fasta
Ссылка на полученный файл.
EnsEMBL
Поискала информацию о гене человека, который выбрала на занятии по online BLAST - DAD1_HUMAN. Сервис с самого начала показался очень удобным и наглядным - есть выравнивание находок (их было 16, (рисунок 1)), экзон-интронная структура (рисунок 2).
Query location : unnamed 1 to 277 (-)
Database location : 14 23057853 to 23058129 (+)
Genomic location : 14 23057853 to 23058129 (+)
Alignment score : 1394
E-value : 5.2e-239
Alignment length : 277
Percentage identity: 99.64
Query: 277 ccgctaggatgaaactccccacacaagagatgaagcccgagagaaaagagttgaagggga 218
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sbjct: 23057853 ccgctaggatgaaactccccacacaagagatgaagcccgagagaaaagagttgaagggga 23057912
Query: 217 aggtccccacgaggagacagtaaccgaactgcagcgccccggtcagcagtatatacagca 158
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sbjct: 23057913 aggtccccacgaggagacagtaaccgaactgcagcgccccggtcagcagtatatacagca 23057972
Query: 157 ggtacgcgtccagcaacttcagacgctgcggagtggagctcaagtactcttctaagaacc 98
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sbjct: 23057973 ggtacgcgtccagcaacttcagacgctgcggagtggagctcaagtactcttctaagaacc 23058032
Query: 97 gcgaaatgacagacactaccgacgccgacataactgcacgcaaggtactccggtccgcgc 38
||||||||||||||||||||||||||||||||||||||||||||||||||| ||||||||
Sbjct: 23058033 gcgaaatgacagacactaccgacgccgacataactgcacgcaaggtactccagtccgcgc 23058092
Query: 37 cccaaactcttggaggacccgtcgaccacaccggatg 1
|||||||||||||||||||||||||||||||||||||
Sbjct: 23058093 cccaaactcttggaggacccgtcgaccacaccggatg 23058129
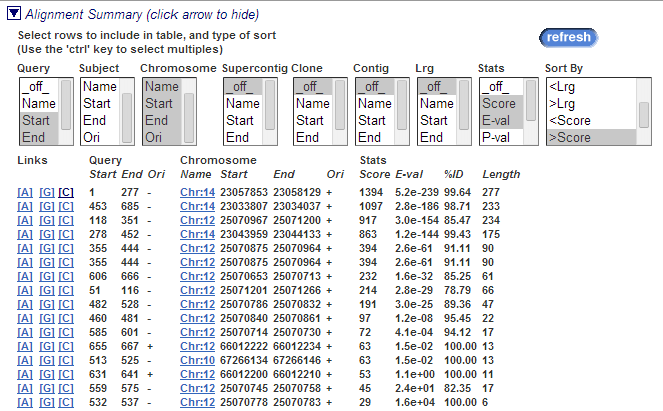
Рисунок 1. Выравнивание находок по запросу DAD1_HUMAN.

Рисунок 2. Экзон-интронная структура гена DAD1_HUMAN.
Также можно посмотреть на расположение находок на разных хромосомах и как выравниваются лучшие из них.
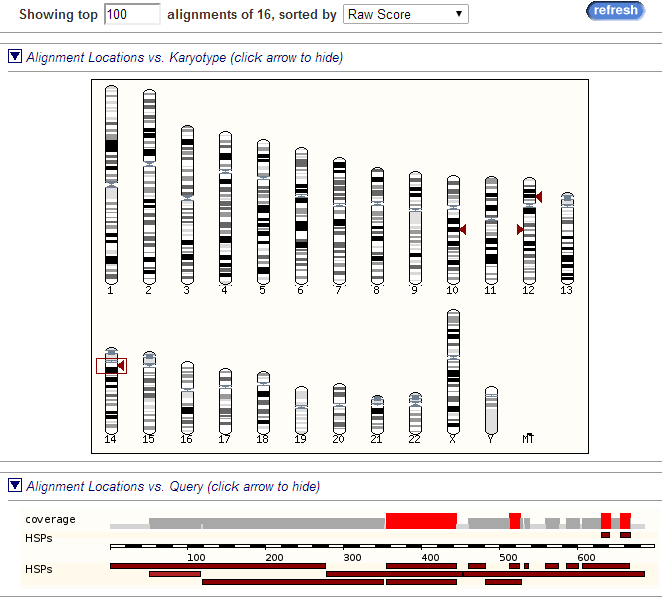
Рисунок 3. Расположение на хромосоме и выравнивание хитов.
Прошла по гиперссылке "Contig view", обозначенной маленькой буквой "C" левее первой находки (в таблице находок внизу страницы). Открылась страница "Region in detail". На ней можно увидеть точное расположение гена на хромосоме (рисунок 4), выровненные гены из разных баз (рисунок 5), приближение-отдаление также возможно, что позволяет рассмотреть любую часть генома самым подробнейшим образом,вплоть до GC-состава (рисунок 6). При нажатии на какой-либо элемент можно получить выравнивание с запросом.
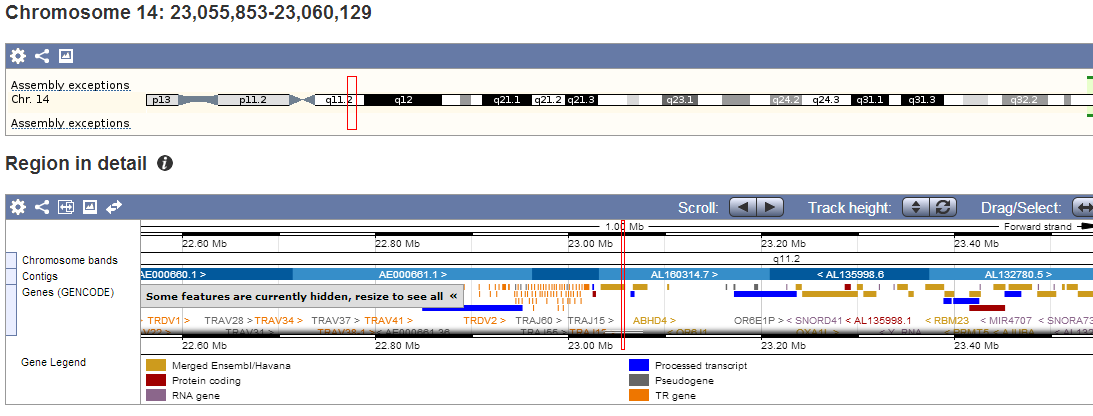
Рисунок 4. Подробное расположение на хромосоме и выравнивание данного хита.
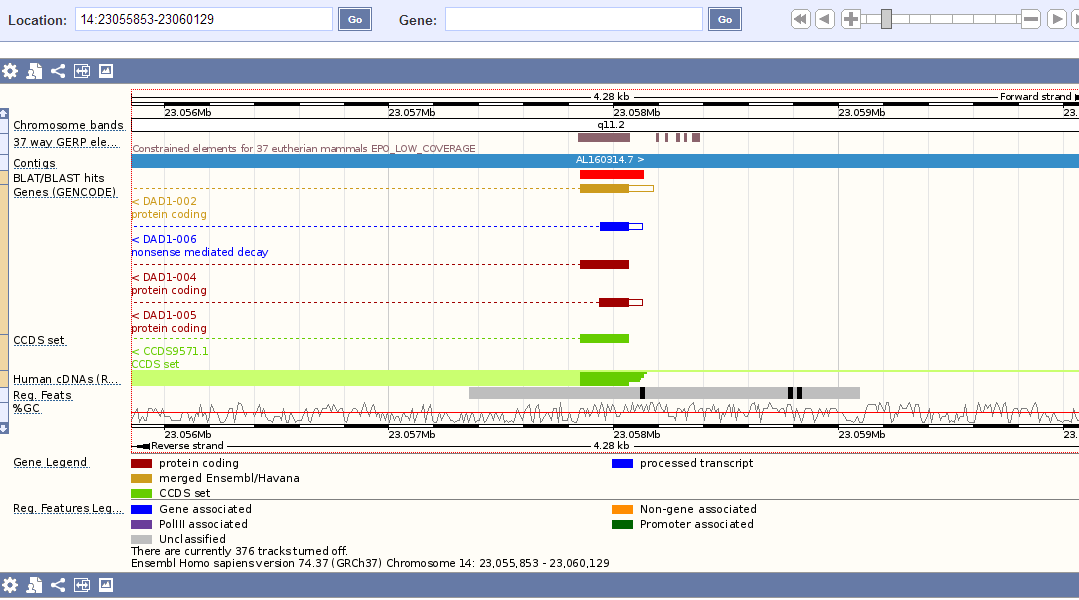
Рисунок 5. Выровненные гены из разных баз.
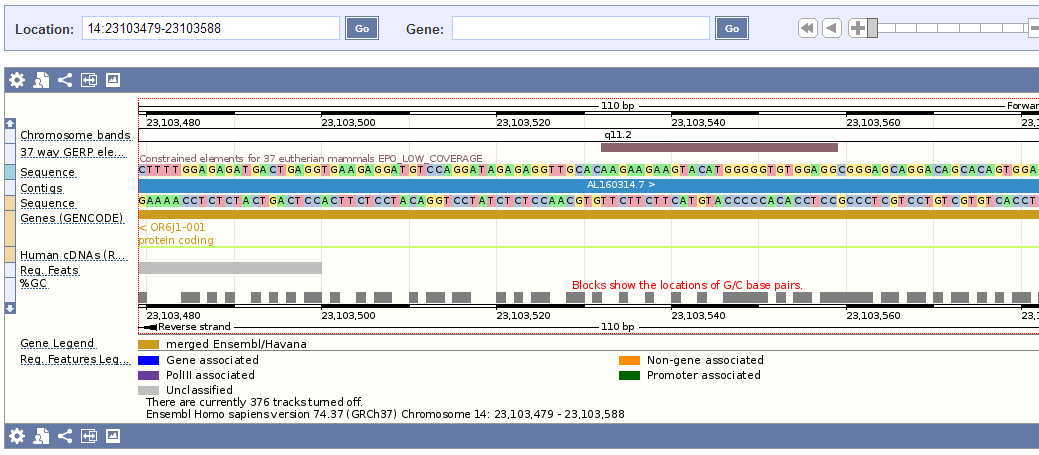
Рисунок 6. Увеличенное изображение выравнивания.