Семестр 1. Мини-обзор. Комплексный анализ генома бактерии Desulfovibrio desulfuricans L4
Содержание
1. Аннотация
В данном исследовании представлен комплексный анализ генома бактерии Desulfovibrio desulfuricans L4. Результаты исследования, изложенные в формате мини-обзора, систематизируют данные о длинах белков, количественной и функциональной структуре генома, его нуклеотидном составе и основных 5-мерах.
2. Введение
Таксономия Desulfovibrio desulfuricans
- Домен (Domain): Bacteria
- Тип (Phylum): Pseudomonadota
- Класс (Class): Deltaproteobacteria
- Порядок (Order): Desulfovibrionales
- Семейство (Family): Desulfovibrionaceae
- Род (Genus): Desulfovibrio
- Вид (Species): Desulfovibrio desulfuricans[1]
Бактерии рода Desulfovibrio представляют собой неспорообразующие изогнутые грамотрицательные палочки, относящиеся к сульфатредуцирующим бактериям (СРБ). Они являются строгими анаэробами, отличаются медленным ростом и для образования видимых колоний требуют от 4 до 7 дней[2].
У представителей рода Desulfovibrio (включая D. desulfuricans) обнаружена диссимиляционная сульфитредуктаза, известная как «desulfoviridin»[3]. Этот фермент участвует в восстановлении сульфитов/сульфатов до сульфидов, что позволяет бактериям осуществлять сульфатное дыхание и продуцировать сероводород (H2S) в анаэробных условиях[4], что при наличии ионов железа может вести к образованию сульфидов железа (например FeS).
В рамках данного мини-отчета решаются следующие задачи: (1) характеристика общей структуры генома и нуклеотидный состав; (2) поиск наиболее часто встречающихся коротких последовательностей и их оценка как кандидатов в регуляторные мотивы; (3) анализ распределения самой часто встречающейся 5-мерной последовательности.
3. Методы
Для анализа генома бактерии Desulfovibrio desulfuricans L4 использован комбинированный подход с применением программных средств и данных из общедоступных биоинформатических ресурсов.
Получение и первичная обработка геномных данных
Исходные данные о нуклеотидной последовательности генома Desulfovibrio desulfuricans были получены из базы данных Национального центра биотехнологической информации США (NCBI). Идентификатор таксона в NCBI Taxonomy Browser: 876. Последовательности генома, включая хромосомы и плазмиды (репликоны), были загружены в формате FASTA для последующего анализа.
Анализ белкового кодирующего потенциала
Из аннотированных геномных данных извлечены аминокислотные последовательности. Для визуализации и количественной оценки была построена гистограмма. Для обработки данных и анализа использовались Google Таблицы (см. раздел 4.1, см. раздел 5.4).
Категоризация и подсчет генов
Для каждого репликона с помощью Python было подсчитано количество генов, кодирующих белки (см.раздел 4.2, раздел 5.1).
Анализ нуклеотидного состава аннотированных генов
Определение доли каждого нуклеотида и проверка наличия симметрии пар AT и GC для каждого репликона. Расчет выполнен с использованием Python (см.раздел 4.3, см.раздел 5.2).
Анализ нуклеотидных повторов на принадлежность к мотивам
Проведен поиск ТОП-10 5-мер и анализ на принадлежность к нуклеотидным мотивам (см.раздел 4.4, см.раздел 5.3).
Анализ распределения наиболее часто встречающегося 5-мера
Анализ распределения для самого частого 5-мера. С помощью скрипта на Python построена тепловая карта локализации данного мотива (см.раздел 4.5, см.раздел 5.3).
4. Результаты
4.1. Распределение длин белков
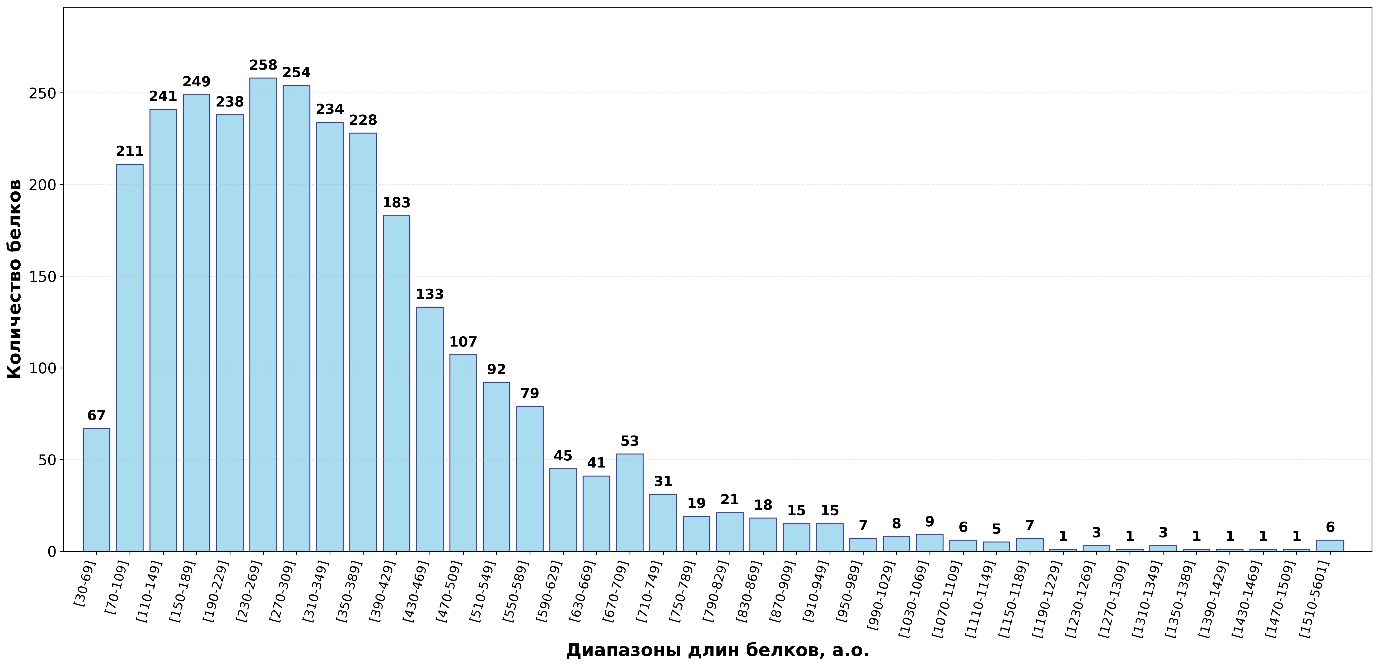
Рисунок 1. Распределение длин белков в геноме. (Исходные данные в Разделе 5.4.)
Данная гистограмма демонстрирует распределение с выраженной правосторонней асимметрией, что типично для бактериальных геномов[5].
Большинство белков D. desulfuricans сосредоточено широким плато в диапазоне ~(70 – 430 а.о.), где количество белков в каждом интервале находится в диапазоне ~(180 – 258). Максимальное количество белков (258) наблюдается для интервала 230–269 а.о.
4.2. Аннотация и подсчет белков и генов разных типов РНК в репликонах генома
Таблица 1. Число генов и белков разных типов РНК
| Репликон | Хромосома | pDsulf-L4 |
|---|---|---|
| Белковые гены | 2931 | 12 |
| гены тPHK | 57 | 0 |
| гены рPHK | 9 | 0 |
| гены нкPHK | 1 | 0 |
| Другие PHK гены | 3 | 0 |
| Белковые псевдогены | 16 | 1 |
| PHK псевдогены | 0 | 0 |
| Всего псевдогенов | 16 | 1 |
| Всего генов | 3017 | 13 |
- Хромосома: Большой основной геном, содержащий подавляющее большинство генов, необходимых для жизни клетки.
- Плазмида (pDsulf-L4): Малая кольцевая молекула ДНК, несущая несколько дополнительных генов, которые могут давать бактерии определенные преимущества (например, устойчивость к антибиотикам или способность утилизировать специфические вещества)[6].
4.2.1 Разбор по репликонам
Таблица 2. Интерпретация полученных результатов по хромосоме
| Хромосома. Параметр | Значение | Интерпретация |
|---|---|---|
| Белковые гены | 2931 | Основной функциональный потенциал организма. Гены кодируют все необходимые ферменты, структурные белки и регуляторные факторы. |
| тРНК | 57 | Обеспечение трансляции (синтеза белка). тРНК переносят аминокислоты к рибосомам. |
| рРНК | 9 | Сборка рибосом. Гены рРНК обычно организованы в опероны. 9 генов скорее всего означают 3 оперона. |
| нкРНК | 1 | Регуляторные функции. Небольшое количество может указывать на неполную аннотацию регуляторных РНК или специфическую организацию регуляторных сетей. |
| Другие РНК | 3 | Специализированные РНК. Включают tmRNA (освобождение рибосом), SRP RNA (транспорт белков) и RNase P RNA (процессинг тРНК). |
| Белковые псевдогены | 16 | Эволюционные остатки. Присутствие 16 псевдогенов свидетельствует об эволюционных процессах и реорганизации генома. |
| Всего генов | 3017 | Стандартный размер генома. Общее число генов соответствует типичной организации свободноживущей бактерии. |
Вывод по хромосоме: Это полностью функциональный, самостоятельный бактериальный геном[6].
Таблица 3. Интерпретация полученных результатов по плазмиде
| Плазмида. Параметр | Значение | Интерпретация |
|---|---|---|
| Белковые гены | 12 | Специализированные функции. Эти гены, скорее всего, кодируют: • Белки для репликации плазмиды (Rep). • Белки для её стабильного наследования (Par). • Белки, обеспечивающие хозяйку полезным свойством (например, устойчивость к тяжелым металлам, антибиотикам или дополнительные метаболические пути). |
| Белковые псевдогены | 1 | Эволюционные изменения. Наличие псевдогена может указывать на недавнюю потерю функции или реорганизацию плазмиды. |
| РНК | 0 | Отсутствие аппарата трансляции. Это абсолютно нормально для плазмид. Они являются "нахлебниками" клетки-хозяина и используют её готовые рибосомы, тРНК и другие компоненты для синтеза своих белков. |
| Всего генов | 13 | Компактность. Плазмида — это небольшой, компактный молекулярный паразит или симбионт, несущий только самые необходимые для своего существования и функции гены. |
Вывод по плазмиде: pDsulf-L4 — это небольшая плазмида, которая придает бактерии определенное селективное преимущество в её нише. Наличие псевдогена свидетельствует об эволюционной динамике этого генетического элемента. Гены плазмиды не являются жизненно важными для клетки, но могут быть необходимыми для выживания в специфических условиях среды[6].
Общий вывод по геномной организации:
- Хромосома бактерии полностью укомплектована всеми необходимыми компонентами для самостоятельной жизни. Соотношение функциональных генов и псевдогенов указывает на стабильный, но эволюционно активный геном.
- Наличие плазмиды указывает на потенциальную дополнительную функцию или адаптацию, которую можно исследовать далее, изучив аннотацию именно белковых генов плазмиды. Анализ их функций даст прямое понимание, зачем бактерии эта плазмида.
4.3. Анализ состава нуклеотидов
Анализ состава нуклеотидов позволяет подтвердить качество данных и провести первичную верификацию качества сборки и аннотации.
Таблица 4. Детализация нуклеотидного состава
| Полный геном | Хромосома | Плазмида |
|---|---|---|
|
A 20.92% T 21.25% G 28.95% C 28.87% Длина = 3050290 bp CDS = 2960 GC-контент = 57.83% AT-контент = 42.17% |
A 20.93% T 21.26% G 28.94% C 28.87% Длина = 3041002 bp CDS = 2947 GC-контент = 57.81% AT-контент = 42.19% |
A 19.26% T 18.01% G 33.0% C 29.73% Длина = 9288 bp CDS = 13 GC-контент = 62.73% AT-контент = 37.27% |
Анализ симметрии по парам AT и GC
Для кодирующих последовательностей полного генома и хромосомы наблюдается близкий к паритету состав комплементарных оснований (AT с отклонением ~0.3%, GC с отклонением <0.1%), что соответствует ожиданиям для кодирующих регионов двухцепочечной ДНК.
Для плазмиды отмечаются более значительные отклонения в парах оснований: AT различаются на 1.25%, GC — на 3.27%. Эти отклонения могут быть объяснены малым размером выборки: плазмида содержит всего 13 CDS общей длиной 9288 п.н., что на три порядка меньше хромосомы.
Анализ нуклеотидного состава выявил умеренно-высокий GC-контент (57.83% для полного генома). Соотношение AT и GC близко к паритету, что ожидаемо для бактериальных геномов. Интересно, что плазмида демонстрирует значительно более высокий GC-контент (62.73%) по сравнению с генами хромосомы. Это может указывать на происхождение плазмиды путём горизонтального переноса генов или отражать селективное давление на стабильность внехромосомных элементов[7].
4.4. Поиск ТОП-10 5-мер, анализ на принадлежность к нуклеотидным мотивам
Поиск десяти самых часто встречающихся 5-мер был выбран для целенаправленного выявления коротких мотивов, которые могут лежать в основе специфической системы регуляции генома.
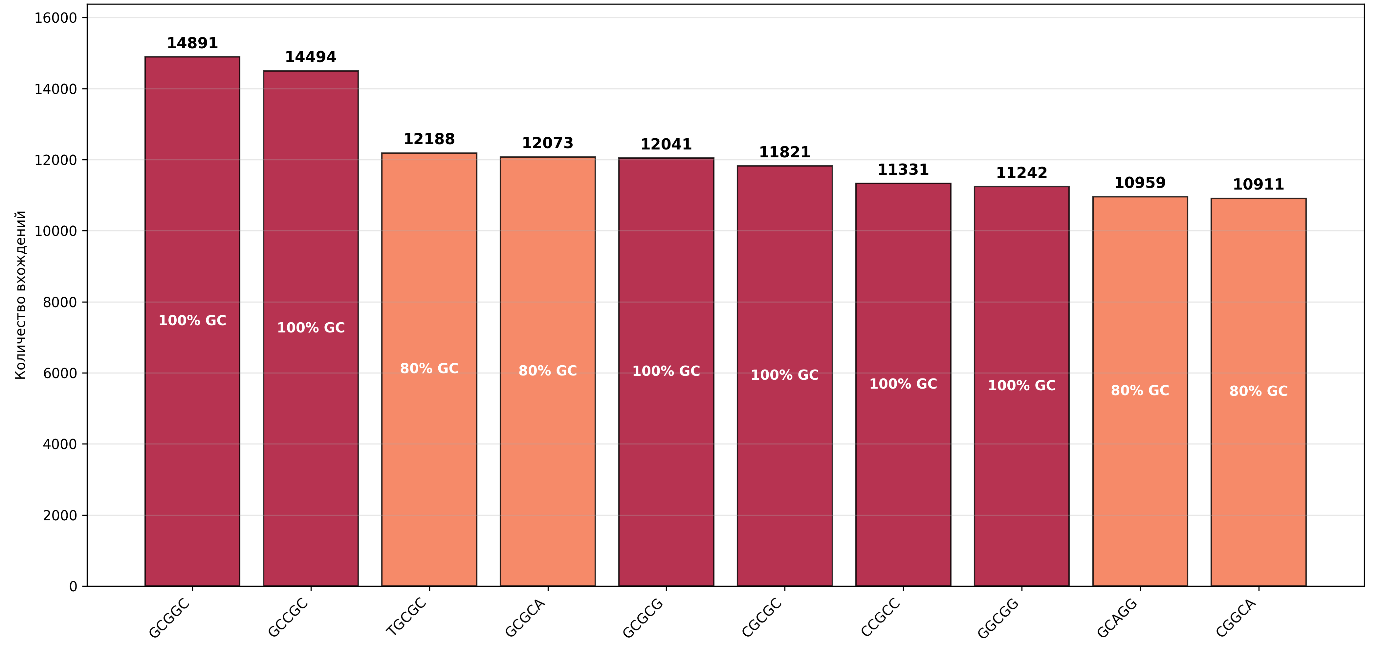
Рисунок 2. ТОП-10 5-меров D. desulfuricans
Аргументы в пользу принадлежности полученных ТОП-10 последовательностей к мотивам
- Высокие частоты вхождений (первый – 14891, второй – 14494);
- Сильная GC-обогащенность (ТОП-10 содержит от 80% до 100% GC);
- Повторяющиеся паттерны:
GC,CGC,GCG.
Специфические кандидаты
GCGCG,CGCGC– возможные сайты для белков, связывающихся с GC-богатыми последовательностями;GCCGC– может быть частью промоторных элементов;GCGGC– возможный элемент вторичной структуры.
Выявленные ТОП-10 5-меров представляют собой интересные кандидаты на регуляторные мотивы. Промоторная архитектура у GC-богатых бактерий часто сложна [7], что добавляет интереса к их анализу. Однако чтобы считать их действительно функциональными мотивами, требуются дополнительные доказательства (позиционная локализация, консервация, структурная/экспериментальная проверка), поскольку вычислительные методы предоставляют прогнозы, нуждающиеся в экспериментальной валидации[8].
4.5. Анализ распределения самого часто встречающегося 5-мера по геному
Анализ распределения самого часто встречающегося 5-мера по геному позволит проверить потенциальную роль этого 5-мера в регуляции транскрипции, стабилизации структуры ДНК или как маркера мобильных генетических элементов, что может быть важно для понимания адаптации бактерии к анаэробным условиям.
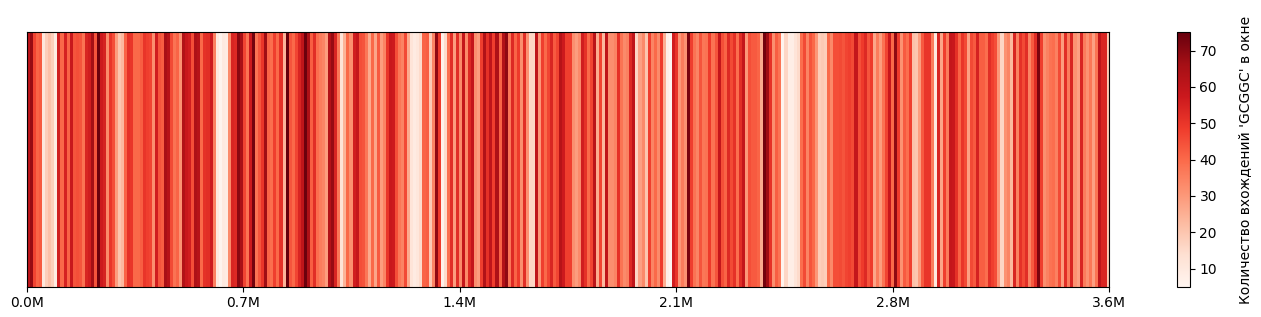
Рисунок 3. Тепловая карта распределения 5-мер GCGGC (окно 10000bp)
Анализ распределения GCGGC
- Неравномерное распределение
- Области обогащения: 0-50 тыс. bp (40-68 вхождений), 200-250 тыс. bp (44-74), 450-460 тыс. bp (65-62), 670-700 тыс. bp (54-70)
- Области обеднения: 500-650 тыс. bp (6-35), 1250-1280 тыс. bp (9-15), 2000-2100 тыс. bp (5-7), 2480-2530 тыс. bp (6-15)
- Выраженные кластеры высокой плотности
- Пиковые значения: 74 (230 тыс. bp), 75 (850 тыс. bp), 73 (2420 тыс. bp), 72 (2170 тыс. bp, 3320 тыс. bp)
- Средняя плотность: ~45 вхождений на окно
- Разброс: от 5 до 75 вхождений (15-кратная вариация)
- Цикличность распределения
- волнообразный паттерн с периодами повышенной плотности каждые 200-300 тыс. bp
- Резкие переходы плотности
- 620-650 тыс. bp (падение с 35 до 6 вхождений)
- 2480-2510 тыс. bp (падение с 38 до 8 вхождений)
- 1260-1280 тыс. bp (падение с 46 до 9 вхождений)
Биологическая интерпретация
- Кластерное (неравномерное) распределение короткой последовательности по геному — действительно может быть признаком, что она не просто "фон", а может участвовать в функциях, требующих локальной регуляции. Паттерны, встречающиеся чаще ожидаемого и/или в специфическом позиционном контексте, являются кандидатами в функциональные сайты[9].
- Резкие границы/переходы плотности мотивов вдоль хромосомы можно интерпретировать как возможные границы структурных или топологических доменов, границы репликонов или мобильных генетических элементов, либо как отражение разной эволюционной истории участков (например, участки, вставленные позже, с отличным GC-составом)[10].
- Периодичность действительно может отражать принцип организации хромосомы на уровне топологических/структурных/регуляторных доменов, которые влияют на репликацию, транскрипцию, упаковку ДНК[10].
Наблюдаемое распределение GCGGC (при условии, что кластеры локализованы в регуляторно-значимых зонах) может быть индикацией функционального значения этой последовательности. Однако это пока остаётся гипотезой: требуется дальнейшая проверка (позиционная привязка, структурный/топологический контекст, консервация, возможно — эксперимент).
5. Сопроводительные материалы
5.1. «0-replicones_analysis.py»
Скрипт анализирует файл аннотации генома (feature table) и проводит количественную классификацию генетических элементов по репликонам: подсчитывает белок-кодирующие гены, различные типы РНК-генов, сохраняет результаты в Excel.
/home/students/y25/dudka2007/term1/mini_review/supplement/0-replicones_analysis.py
5.2. «1-atgc_analysis_updated.py»
Скрипт анализирует нуклеотидный состав и GC-контент для каждого компонента, сохраняет статистику в Excel-файл.
/home/students/y25/dudka2007/term1/mini_review/supplement/1-atgc_analysis_updated.py
5.3. «2-k-mer_search+heatmap.py»
Скрипт состоит из двух блоков:
- k-mer: анализирует возможные короткие нуклеотидные последовательности длиной 5 пар оснований (5-меры), подсчитывает частоту их встречаемости и идентифицирует топ-10 самых частых 5-меров, вычисляет GC-состав, визуализирует и сохраняет результат в Excel.
- Для самого частого 5-мера скрипт визуализирует его распределение по геному, создает "тепловую карту", выгружает распределение в Excel.
/home/students/y25/dudka2007/term1/mini_review/supplement/2-k-mer_search+heatmap.py
5.4. Исходные данные для гистограммы распределения длин белков
6. Список литературы
- NCBI Taxonomy Browser: Desulfovibrio desulfuricans. URL: https://www.ncbi.nlm.nih.gov/Taxonomy/Browser/wwwtax.cgi?id=876 (дата обращения: 15.10.2024)
- Verstreken I., Laleman W. Desulfovibrio desulfuricans Bacteremia in an Immunocompromised Host with a Liver Graft and Ulcerative Colitis // Journal of Clinical Microbiology. 2012. Vol. 50, No. 1. P. 199-201. DOI: 10.1128/JCM.05611-11
- Lee J.P., Peck H.D. Isolation of a new pigment, Desulforubidin, from Desulfovibrio desulfuricans and its role in sulfite reduction // Journal of Bacteriology. 1973. Vol. 115, No. 1. P. 453-455. DOI: 10.1128/jb.115.1.453-455.1973
- Desulfovibrio hydrothermalis sp. nov., a novel sulfate-reducing bacterium isolated from hydrothermal vents — Alazard et al. 53 (1): 173 — International Journal of Systematic a … (Дата обращения: 29.10.2025)
- Nevers Y., Glover N., Dessimoz C., Dylus D. Protein length distribution is remarkably uniform across the tree of life // Genome Biology. 2023. Vol. 24. Article 135. DOI: 10.1186/s13059-023-02973-2
- Prokaryotic Genome Annotation Pipeline // National Center for Biotechnology Information (NCBI). – URL: https://www.ncbi.nlm.nih.gov/genome/annotation_prok/ (дата обращения: 25.12.2025)
- Almpanis A., Swain M., Gatherer D., McEwan N. Correlation between bacterial G+C content, genome size and the G+C content of associated plasmids and bacteriophages // Microbial Genomics. 2018. Vol. 4, No. 4. e000168. DOI: 10.1099/mgen.0.000168
- Bailey T.L., Boden M., Buske F.A. et al. MEME Suite: tools for motif discovery and searching // Nucleic Acids Research. 2009. Vol. 37 (Web Server issue). P. W202-W208. DOI: 10.1093/nar/gkp335
- Богатырев М.Ю. Методы кластеризации в исследовании экспрессии генов // Proceedings of the International Conference "Mathematical Biology and Bioinformatics" = Труды Международной конференции "Математическая биология и биоинформатика" / под ред. В.Д. Лахно. – Пущино: ИМПБ РАН, 2020. – Т. 8. – Статья № e21. – DOI: 10.17537/icmbb20.27.
- Романенков К.В. Метод оценки качества сборки генома на основе частот k-меров — Москва: ИПМ им. М.В. Келдыша РАН, 2024. — 23 с. — URL: https://keldysh.ru/papers/2024/prep2024_xx.pdf (дата обращения: 25.12.2025)