Задание 1. Чтение последовательности ДНК на основании данных, полученных из капиллярного секвенатора по Сэнгеру. Обзор проблем, возникающих при чтении хроматограмм.
Файлы данного задания:
- исходные [ab1]-файлы, соответствующие прочтению прямой и последовательностей;
- полученные после редактирования автоматического прочтения [FASTA]-файлы с прямой и обратной-комплементарной последовательностями;
- [jvp]-проект с выравниванием отредактированных последовательностей.
Для просмотра хроматограмм и редактирования автоматического прочтнения использовалась программa Chromas (Lite).
Характеристика хроматограммы прямой цепи:
- длины начального и конечного нечитаемых участков (п.н.): 25 и 284
- сила сигнала интенсивнее шума в среднем в 10 раз
- уровень шума увеличивается ближе к краям последовательности, в то время как уровень сигнала колеблется вдоль всей последовательности
Характеристика хроматограммы обратной цепи (здесь и далее использовалась
- длины начального и конечного нечитаемых участков (п.н.): 48 и 42
- сила сигнала интенсивнее шума в среднем в 5 раз
- уровень шума увеличивается ближе к краям последовательности, в то время как уровень сигнала колеблется вдоль всей последовательности
Редактирование последовательностей
В хроматограммах возникают некоторые полиморфизмы, то есть какие-то нуклеотиды не могут быть автоматически определены из-за посторонних сигналов - шумов. Полиморфизмы обозначаются кодами вырожденных нуклеотидов (ambiguity codes) - W: A или T; S: G или C; и т.п.
В хроматограммах данных мне последовательностей в основном встречаются следующие вырожденные коды: N(G,A,T,C) и S(G,C), эти коды заменялись нуклеотидами, которые были определены в другой последовательности. (см. табл.1)
| Проблема | Изображение |
| Из-за высокого уровня шума в прямой цепи (вверху) не определены 2 нуклеотида (N - G,A,T,C; S - G или C). Неопределенные нуклеотиды можно восстановить по обратной цепи (внизу). |  |
| Здесь, вероятно, слишком сильные сигналы перекрывают остальные слабые сигналы, пики которых по высоте сравнимы с пиками шума. |  |
Задание 2. Пример нечитаемого фрагмента хроматограммы.
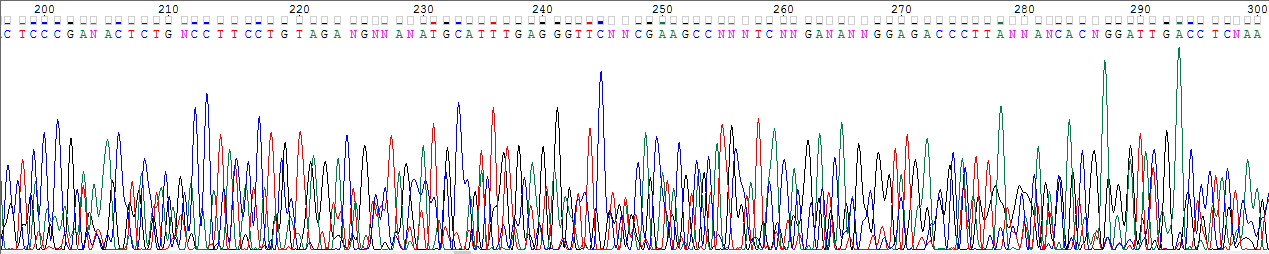
Изображенный вверху фрагмент хроматограммы нельзя считать достоверным, так как слишком частые сигналы шумов сравнимы с сигналами нуклеотидов.