С помощью программы Chromas (Lite) были открыты данные мне хроматограммы прямой и обратной последовательности. Исправление прямой последовательности происходило путем ее сравнения с последовательностью, комплементарной обратной (получена с помощью Reverse+Complement).
Сначала были отрезаны плохо читаемые концы. Сама программа в прямой последовательности выделила с 1 по 23 и с 430 до 833 нуклеотиды как плохо прочитанные, однако последовательность вполне читаема начиная уже с 15 нуклеотида, а сравнение со второй последовательностью позволяет отодвинуть и правый конец и удалить только с 626 по 833 нуклеотиды. Во второй же последовательности конца автоматически получились с 1 по 127 и с 832 по 868 нуклеотиды, но т. к. в задании было сказано координаты концов определять по прямой последовательности, я обрезала вторую так же, как первую. Т. е. длина правого конца - 23, левого - 208 нуклеотидов.
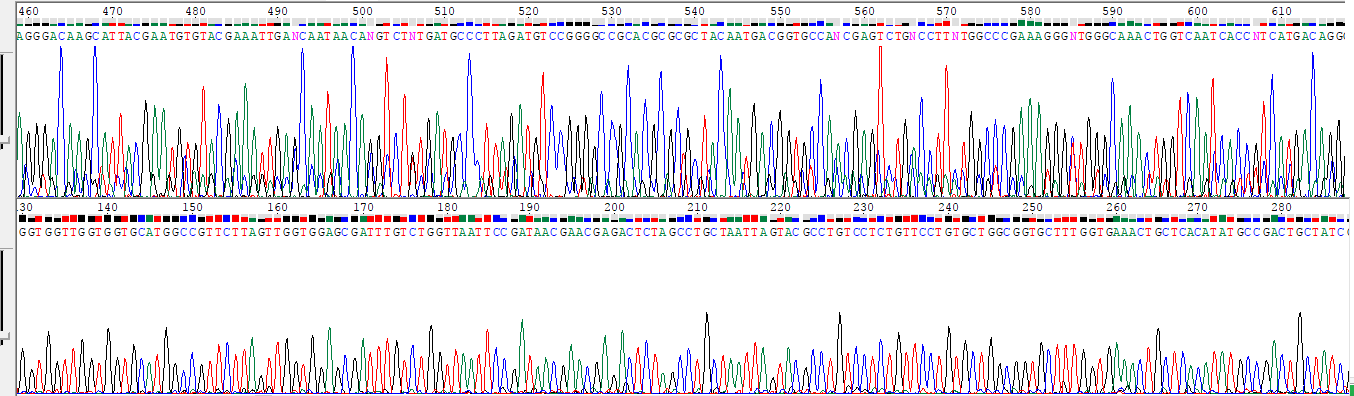
На рис. 1 преставлены разные фрагменты разных хроматограмм (при одинаковвых вертикальных и горизонтальных масштабах). Приведенные фрагменты - примеры хороших участков каждой хроматограммы. Видно, что у обратного прочтения (верхняя хроматограмма) уровень сигнала (как шумового так и значимого) заметно выше.
Рисунок 1. Фрагменты хроматограмм обратного (сверху) и прямого прочтения.
Как уже было сказано, уровень шума (как и вообще уровень сигнала) в обратной хромотограмме даже в хорошем участке выше, чем в прямой, онако уровень щума относительно значимого сигнала примерно одинаковый (так говорит мне мой глазомер).
При этом уровень шума примерно равномерен, если не считать нечитаемых концов, где шум уже не отличим от не шума, причем сигнал (особенно на самых концах длинный нечитаемых концов) может быть очень сильным.
Еще одно различие между двумя хроматограмамми: в первой (прямой, на рис. 1 та. которая ниже) сигналы A и G в среднем заметно выше остальных, в то время как во второй хроматограмме наоборот:
сигналы Т и С заметно сильнее сигналов A и G.
Еще один показатель - длина нечитаемых участков. У прямой последовательности: левый - 23, правый - 434, что составляет примерно 55% от общей длины последовательности; у второй: левый - 127, правый - 37, процент - 18,9%. То есть вторая последовательность читаема и информативна на куда большей части прочтения.
Исправления. На рис. 2 приведени участок с четырьмя выделенными исправлениями. Пояснения к ним даны ниже:
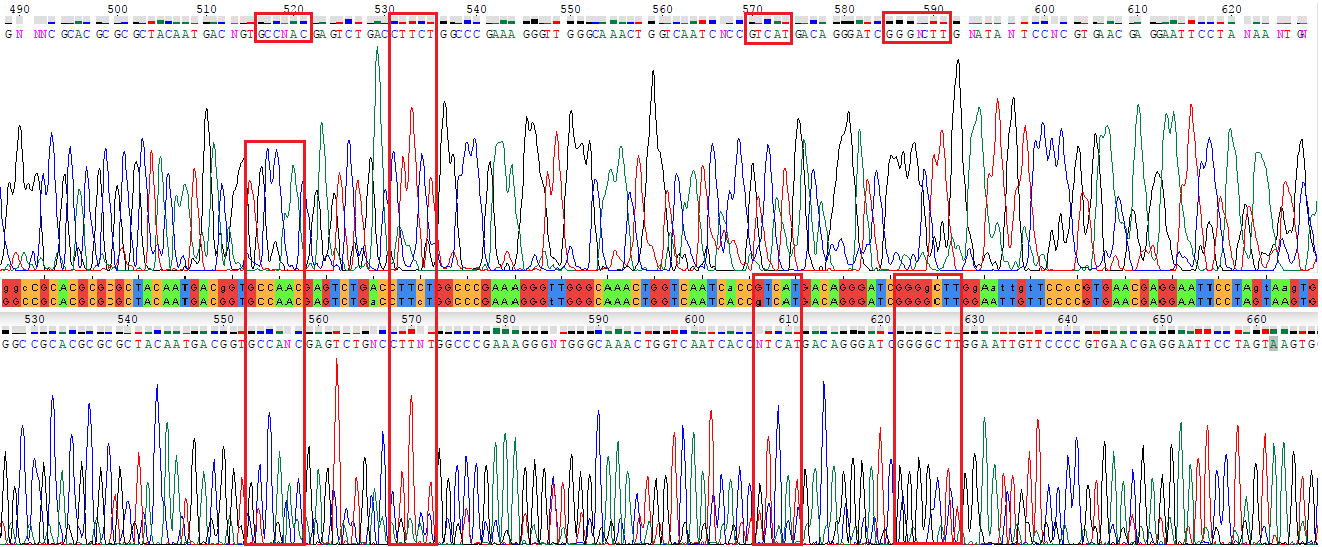
Рисунок 2. Примеры исправлений
По ссылке вы так же можете посмотреть выравнивание целиком.На рис. 3 приведен фрагмент прямого прочтения ближе к концу. Видно, что на нем качество хромагограммы уже не удовлетворительное. Также видно, что становится очень много сдвоенных пиков. Возможно, это объясняется тем, что при большой длине фрагмента ДНК плохо становится различима разница между фрагментами, где синтез ДНК остановаился на соседних буквах (понятно, что разница в массе между кусками в 1 нуклеотид и 2 нуклеотида куда более заметна, чем разница между кусками в 1000 и 1001 нуклеотид). Соответственно, эти полосы на форезе очень близко, что делает их трудно различимыми.

Рисунок 3. Пример нечитаемого конца.
НАЗАД ➜ |
| © <Рюмина Екатерина>, 2017 |