







Практикум 13. Поиск гомологии
Практикум ориентирован на выявление критериев гомологичности для отрезков множественного выравнивания белковых последовательностей. Необходимо было найти у нескольких вероятно родственных белков длинные отрезки с большим количеством консервативных позиций - домены.
Практикумом предложено было взять последовательности, найденные с помощью базы данных белковых семейств Pfam или сервиса BLASTp. Нами был выбран второй вариант, так как это служит логичным продолжением предыдущего практикума.
Что было сделано
По описанному в 12 практикуме алгоритму был получен список белковых последовательностей, схожих с исследуемой последовательностью P0C1A9. На этот раз были взяты другие последовательности, принадлежащие совершенно различным организмам. Скачанные последовательности выравняли в Jalview и исправили выравнивание алгоритмом Tcoffee. После удаления многих последоваетльностей, разительно отличающихся от остальных, осталось 10 последовательностей, относящихся к организмам родов Solanum(P09607, Q96576, Q96575), Arabidopsis(Q1JPL7, Q42534), Citrus(O04887), Prunus(Q43062), Daucus(P83218), Actinidia(P85076), Dickeya(P0C1A9). Полученное выравнивание сохранено в формате jvp.
Анализ
В полученном выравнивании оказалось несколько протяженных фрагментов, обладающих высокой долей консервативных позиций: относительно короткий длиной 11 а.к.о. (348-358 позиции выравнивания) и более длинный, состоящий из 38 а.к.о. (466-503). В них около 50% позиций консервативны. Отрезки представлены на рисунках.

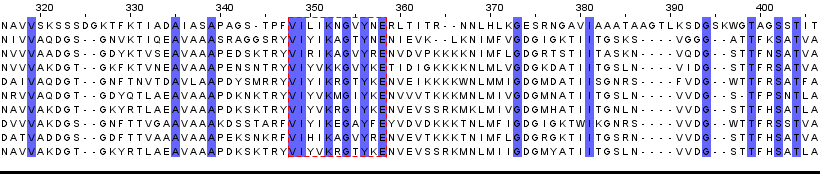
К сожалению, других крупных блоков найдено не было, зато было обнаружено некоторое окружение из достаточно часто расположенных консервативных столбцов, что видно на изображениях.
На основании наличия этих длинных отрезков с высокой долей консервативности и их окружения небольшими участками консервативных позиций можно с очень высокой долей вероятности утверждать, что представленные белки гомологичны.
База данных Pfam
База белковых доменов Pfam содержит информацию о многих белковых последовательностях и входящих в их состав характерных доменах. Поэтому можно провести поиск белковых последовательностей по наличию или отсутствию в них определённых доменов. Это делается следующим образом: нужно перейти на вкладку поиска (search), далее выбор предмета поиска - Domain architecture. На странице выбираются домены из списка и включаются (includes) или исключаются (Does NOT include) из поиска. После нажатия Submit выводитсч список выборок, содержащих конкретный набор доменов и удовлетворяющих введённым условиям, и количество последовательностей в них.
Pfam - удобная база данных. Есть возможность вставить в окно отрезок белковой последовательности и выяснить, какой домен в ней содержится. Pfam хорошо использовать для выяснения филогенетических отношений между организмами.