Краткое описание белка YP_001728482.1 бактерии Leuconostoc citreum KM20
Вместо предисловия: [1]
Изменения:
Белок YP_001728482.1 бактерии Leuconostoc citreum KM20 является ныне белком WP_012305345.1. Это преобразование произошло 3 февраля 2015 года. Локус LCK_01211, соответствующий белку YP_001728482.1, был переименован в LCK_RS09530, соответствующий WP_012305345.1. Кроме этого, ген NC_010471.1, который не изменился при преобразовании белка и локуса, кодирует не декстрансукразу, как это было изначально, а гликозил гидролазу.
Почему же это произошло?
Для секвенирования большого числа практически идентичных геномов требовалось много времени. Эти геномы были необходимы для анализирования штаммов пищевых возбудителей заболеваний и инфекционных вспышек. После секвенирования геномов оказывалось, что почти все гены, которые были 'новыми', уже существовали в базе данных. Таким образом, для того, чтобы продолжать предоставлять данные для прокариот и не перегружать базу данных уже существующей информацией, на сайте NCBI решили повторно аннотировать все RefSeq прокариотических геномов.
Особенности белка и гена, кодирующего его:
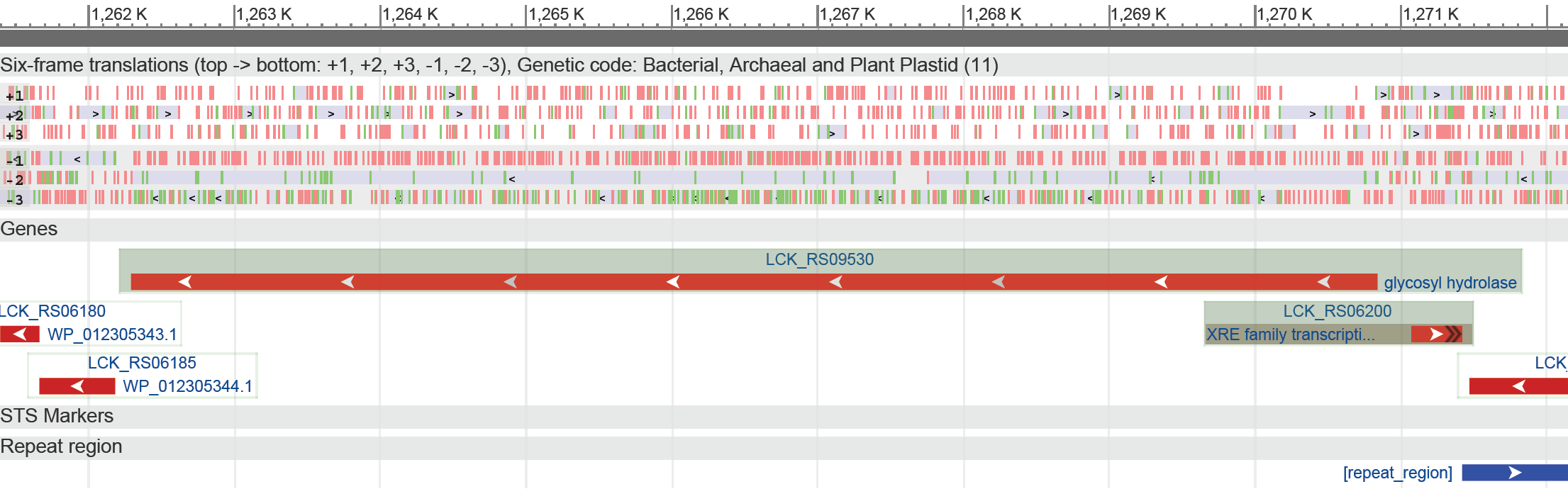
Ген, кодирующий гликозил гидролазу, является псевдогеном. Так как цепь обратная, стоп-кодон UUA располагается на левом конце последовательности (см. рис. 1).
Источники информации:
[1]: NCBI.NLM.NIH.GOV/refseq (Re-annotation project)
[2]: NCBI.NLM.NIH.GOV/protein (Protein)
Изменения:
Белок YP_001728482.1 бактерии Leuconostoc citreum KM20 является ныне белком WP_012305345.1. Это преобразование произошло 3 февраля 2015 года. Локус LCK_01211, соответствующий белку YP_001728482.1, был переименован в LCK_RS09530, соответствующий WP_012305345.1. Кроме этого, ген NC_010471.1, который не изменился при преобразовании белка и локуса, кодирует не декстрансукразу, как это было изначально, а гликозил гидролазу.
Почему же это произошло?
Для секвенирования большого числа практически идентичных геномов требовалось много времени. Эти геномы были необходимы для анализирования штаммов пищевых возбудителей заболеваний и инфекционных вспышек. После секвенирования геномов оказывалось, что почти все гены, которые были 'новыми', уже существовали в базе данных. Таким образом, для того, чтобы продолжать предоставлять данные для прокариот и не перегружать базу данных уже существующей информацией, на сайте NCBI решили повторно аннотировать все RefSeq прокариотических геномов.
Особенности белка и гена, кодирующего его:
Ген, кодирующий гликозил гидролазу, является псевдогеном. Так как цепь обратная, стоп-кодон UUA располагается на левом конце последовательности (см. рис. 1).
 |
| Таблица1. Описание декстрансукразы из генома бактерии Leuconostoc citreum KM20 [2] | |
|---|---|
| Параметр | Значение |
 |
Последовательность белка: [3]
>gi|170017563|ref|YP_001728482.1| dextransucrase [Leuconostoc citreum KM20]
MINNTLYDSRTVGGGEYQEKFGGLFLDQLKKDYPSLFETKQISTNQPMNPDVKIKEWSAK
YFNGSNIQGRGAWYVLKDWATNQYFNVSSDNGFLPKQLLGEKTSTGFITENGKTSFYSTS
GYQAKDTFIQDGTNWYYFDNAGYMLTGKQNIHDKNYYFLPNGVELQDAYLFDGNQEFYYN
KAGEQVMNQYYQDSQNQWHYFFENGRMAIGLTEVPNADGTHVTQYFDANGVQIKGTAIKD
QNNQLRYFDEATGNMVVNSWGQLADKSWLYLNAQGVAVTGNQKIDGEEYYFNADGKQVKG
NAIIDNNGDQRYYDGDKGVMAVNSWGELPDGSWLYLNDKGIAVTGRQVINNQVNFFGNDG
KQIKDAFKLLSDGSWVYLDDKGLITTGAKVINGLNMFFDKDGHQIKGDASTDANGKRHYY
DKNDGHLVTNSWGELPDGSWLYLDEQGDAVTGQRVIDGKTRYFDEDGKQIKNSLKTLANG
DKIYLDGDGVAATGLQHVGDKIMYFDEDGKQVVSKFVSAKDGSWYYLNQDGVAAVGPSSI
NGQSLYFDQDGKQVKYNEVRNSDGTTNYYTGLTGEKLTQDFGELPDGSWIYLDAQGHTVT
GAQIINGQNLYFKADGQQVKGHAYTDQLGHMRFYDPDSGDMLSNRFEQITPGVWAYFGAD
GVAITGQHDINGQKLFFDETGYQVKGSQRTIDGTLYSFDSQTGNQKRVQTTLLPQAGHYI
TKNGNDWQYDTNGELAKGLRQDSNGKLRYFDLTTGIQAKGQFVTIGQETYYFSKDHGDAQ
LLPMVTEGHYGTITLKQGQDTKTAWVYRDQNNTILKGLQNINGTLQFFDPYTGEQLKGGV
AKYDDKLFYFESGKGNLVSTVAGDYQDGHYIAQDDQTRYADKQNQLVKGLVTVNGALQYF
DNATGNQIKNQQVIVDGKTYYFDDKGNGEYLFTNTLDMSTNAFSTKNVAFNHDSSSFDHT
VDGFLTADTWYRPKSILANGTTWRDSTDKDMRPLITVWWPNKNVQVNYLNFMKANGLLIT
AAQYTLHSDQYDLNQAAQDVQVAIEKRIASEHGTEWLQKLLFESQNNNPSFVKQQFIWNK
DSEYHGGGDAWFQGGYLKYGNNPLTPTTNSDYRQPGNAFDFLLANDVDNSNPVVQAENLN
WLHYLMNFGTITAGQDDANFDSIRIDAVDFIHNDTIQRTYDYLRDAYQVQQSEAKANQHI
SLVEAGLDAGTSTIHNDALIESNLREAATLSLTNEPGKNKPLTNMLQDVDGGTLITDHTQ
NSTENQATPNYSIIHAHDKGVQEKVGAAITDATGADWTNFTDEQLKAGLELFYKDQRATN
KKYNSYNIPSIYALMLTNKDTVPRMYYGDMYQDDGQYMANKSIYYDALVSLMTARKSYVS
GGQTMSVDNHGLLKSVRFGKDAMTANDLGTSATRTEGLGVIIGNDPKLQLNDSDKVILDM
GAAHKNQKYRAVILTTRDGLATFNSDQAPTAWTNDQGTLTFSNQEINGQDNTQIRGVANP
QVSGYLAVWVPVGASDNQDARTAATTTENHDGKVLHSNAALDSNLIYEGFSNFQPKATTH
DELTNVVIAKNADVFNNWGITSFEMAPQYRSSGDHTFLDSTIDNGYAFTDRYDLGFNTPT
KYGTDGDLRAAIQALHHANMQVMADVVDNQVYNLPGKEVVSATRAGVYGNDDATGFGTQL
YVTNSVGGGQYQEKYAGQYLEALKAKYPDLFEGKAYDYWYKNYANDGSNPYYTLSHGDRE
SIPADVAIKQWSAKYMNGTNVLGNGMGYVLKDWHNGQYFKLDGDKSTLPQI
|
Источники информации:
[1]: NCBI.NLM.NIH.GOV/refseq (Re-annotation project)
[2]: NCBI.NLM.NIH.GOV/protein (Protein)
⌘
© Emir Radkevich, 2016