Мини-обзор особенностей генома Tetragenococcus koreensis
Куликов А.Б.
Факультет биоинженерии и биоинформатики, МГУ им. М.В.Ломоносова, Москва, Россия
Аннотация - в обзоре рассмотрены некоторые локальные особенности генома бактерии Tetragenococcus koreensis.
Ключевые слова: таблица локальных особенностей, CDS, Tetragenococcus koreensis, геном, белки
ВВЕДЕНИЕ
Кимчи - традиционное корейское блюдо из остро приправленных ферментированных овощей. Основную роль в ферментации играют бактерии, а именно лактобациллы. Анализ бактериального сообщества в трёх видах кимчи, производимых в Южной Корее, позволил обнаружить новый вид Tetragenococcus koreensis [1].
Tetragenococcus koreensis – грамположительный, неподвижный, умеренно галофильный, факультативно аэробный вид бактерий.
Систематическое положение Tetragenococcus koreensis: Bacteria; тип Bacillota; класс Bacilli; порядок Lactobacillales; семейство Enterococcaceae; род Tetragenococcus [2].
Особенностью Tetragenococcus koreensis является способность бактерий этого вида синтезировать рамнолипиды [3]. Также этот вид является частью микробиоты традиционной итальянской сырой ферментированной колбасы [1].
МАТЕРИАЛЫ И МЕТОДЫ
Таблица локальных особенностей генома бактерии Tetragenococcus koreensis, последовательности хромосомы и плазмиды, а также последовательности CDS была взята для анализа с сайта:
Геном Tetragenoccocus koreensis.
Число генов, псевдогенов и различных типов РНК было рассчитано с помощью фильтров колонок “class” и “chromosome”, полученные таблицы были перенесены на соответствующие листы (см. таблицу S1 сопроводительных материалов).
Суммарная длина разных типов генов была получена из данных таблицы локальных особенностей генома Tetragenococcus koreensis с помощью функции для массивов (“ArrayFormula”) с отбором принадлежности гена к репликону и определнному типу генов одовременно (столбцы “chromosome” и “class” соответственно) и функции “СУММ”, которая суммирует отобранные длины (см. таблицу S1 сопроводительных материалов). А длины репликонов были взяты из данных о сборки генома Tetragenococcus koreensis с сайта NCBI (см. S2 сопроводительных материалов).
Для визуализации неравномерного распределения длин белков была построена гистограмма: длины белков, взятых из данных таблицы с описанием CDS Tetragenococcus koreensis, были разбиты на карманы (в том числе с помощью функций “МИН”, “МАКС”, возвращающих минимальное и максимальное значение из столбца), затем было подсчитано количество белков, имеющих длину, соответствующую каждому карману с помощью функции “СЧЕТЕСЛИМН”, которая подсчитывает количество белков, длина которых находится в диапазоне кармана. Сама гистограмма построена встроенными методами конструирования гистограмм GoogleSheets (см. таблицу S3 сопроводительных материалов).
Для анализа расстояний между CDS и пересечений CDS в геноме Tetragenococcus koreensis было построено 4 гистограммы. Сначала с помощью фильтров по столбцам “feature”, “class”, “chromosome”, “strand” таблицы локальных особенностей генома бактерии Tetragenococcus koreensis были отобраны CDS, находящиеся на “+” и “-” цепях хромосомы, и перенесены на соответствующие листы. Затем вычитанием из координаты начала очередной CDS координаты конца предыдущей CDS были получен столбец, в котором положительные числа обозначают расстояния, а отрицательные пересечения между CDS. Эти столбцы, в свою очередь с помощью фильтров были разбиты на два столбца с отрицательными и положительными значениями соответственно. Расстояния между CDS были разбиты на карманы (в том числе с помощью функций “МИН”, “МАКС”), количество соответствующих диапазону расстояний подсчитано с помощью функции “СЧЕТЕСЛИМН”. Для пересечений между CDS был сделан столбец со значениями от 1 до максимального значения (в нашем случае это 118 нуклеотидов), а количество пересечений соответствующих такое длине было подсчитано с помощью функции “СЧЕТЕСЛИ”. Сама гистограммы построены встроенными методами конструирования гистограмм GoogleSheets (см. таблицу S4 сопроводительных материалов).
Все данные об оперонах были взяты из таблицы локальных особенностей генома бактерии Tetragenococcus koreensis и таблицы с анализом пересечений CDS и расстояний между ними (см. таблицы S1 и S4 сопроводительных материалов).
Для исследования состава нуклеотидов были использованы последовательности хромосомы и плазмиды из файла с геномом Tetragenococcus koreensis (см. S5 сопроводительных материалов). Количество нуклеотидов и динуклеотидов получено с помощью кодов №1 и №2 (см. S6 сопроводительных материалов).
Визуализация распределения GC-состава по CDS в геноме Tetragenococcus koreensis была осуществлена построением гистограммы по данным таблицы с описанием CDS Tetragenococcus koreensis методами создания гистограмм предложенными GoogleSheets (см. таблицу S3 сопроводительных материалов).
Для анализа GC-состава всей хромосомы была использована ее последовательность (см. S5 сопроводительных материалов), и код №5 (см. S6 сопроводительных материалов). Для определения наличия генов определенных участков была использована таблица локальных особенностей генома бактерии Tetragenococcus koreensis.
Количество старт-кодонов и стоп-кодонов было определено конвейерами BASH, полученные данные переносились импортированием созданных файлов в GoogleSheets (см. S7 сопроводительных материалов).
Частота кодонов была подсчитана с помощью кодов №3 и №4 (см. S6 сопроводительных материалов) в 30 и 40 CDS генома Tetragenococcus koreensis (см. S8 сопроводительных материалов).
РЕЗУЛЬТАТЫ И ОБСУЖДЕНИЕ
1. ЧИСЛО ГЕНОВ БЕЛКОВ, ПСЕВДОГЕНОВ И РАЗНЫХ ТИПОВ РНК
Геном Tetragenococcus koreensis состоит из плазмиды и хромосомы. Плазмида несет только белок-кодирующие гены, а хромосома содержит как белок-кодирующие гены, так и псевдогены и гены РНК (Таблица 1).
| хромосома | плазмида | |
|---|---|---|
| гены белков | 2465 | 13 |
| гены РНК | 82 | 0 |
| псевдогены | 80 | 0 |
Притом гены РНК, в свою очередь, могут быть тоже разных типов (Таблица 2).
| хромосома | плазмида | |
|---|---|---|
| tRNA | 63 | 0 |
| rRNA | 15 | 0 |
| tmRNA | 1 | 0 |
| ncRNA | 1 | 0 |
| RNase_P_RNA | 1 | 0 |
| SRP_RNA | 1 | 0 |
В геноме Tetragenococcus koreensis содержались следующие типы генов РНК:
- tRNA – транспортная РНК;
- rRNA – рибосомная РНК;
- tmRNA – транспортно-матричная РНК (нужна для высвобождения рибосом, “застрявших” во время трансляции дефектной мРНК, например, мРНК без стоп-кодона);
- ncRNA – некодирующая РНК (множество различных функций);
- RNase_P_RNA – РНК, входящая в состав рибонуклеазы Р, необходимой для нормального синтеза тРНК, рРНК и так далее;
- SRP_RNA – РНК, которая входит в комплекс SRP. SRP-комплекс узнает сигнальный пептид и перенаправляет белок в трансмембранную пору.
2. ДЛИНЫ ГЕНОВ РАЗНЫХ ТИПОВ И ИХ ПРОЦЕНТНОЕ СОДЕРЖАНИЕ
Хромосома содержит 80 псевдогенов и 82 гена РНК (Таблица 1), то есть почти равное количество. Но длина всех псевдогенов больше суммы длин всех генов РНК в 6 раз. В хромосоме и плазмиде наибольшую суммарную длину имеют белок-кодирующие последовательности (Таблица 3).
| процентное содержание | хромосома | плазмида |
|---|---|---|
| гены белков | 82,38% | 72,74% |
| гены рнк | 0,39% | 0,00% |
| псевдогены | 2,44% | 0,00% |
| межгенные промежутки | 14,80% | 27,26% |
Плазмида должна нести множество регуляторных последовательностей (ориджин, промоторы, терминаторы и т.д.). Сравнив длину межгенных промежутков на хромосоме и плазмиде, можно предположить, что процентное содержание регуляторных последовательностей в плазмиде больше, чем в хромосоме, не смотря на то, что в состав межгенных промежутков также входят нефункциональные последовательности, ведь у прокариот в большинстве случаев они удаляются в результате естественного отбора.
3. ДЛИНЫ БЕЛКОВ, ЗАКОДИРОВАННЫХ В ГЕНОМЕ Tetragenococcus koreensis
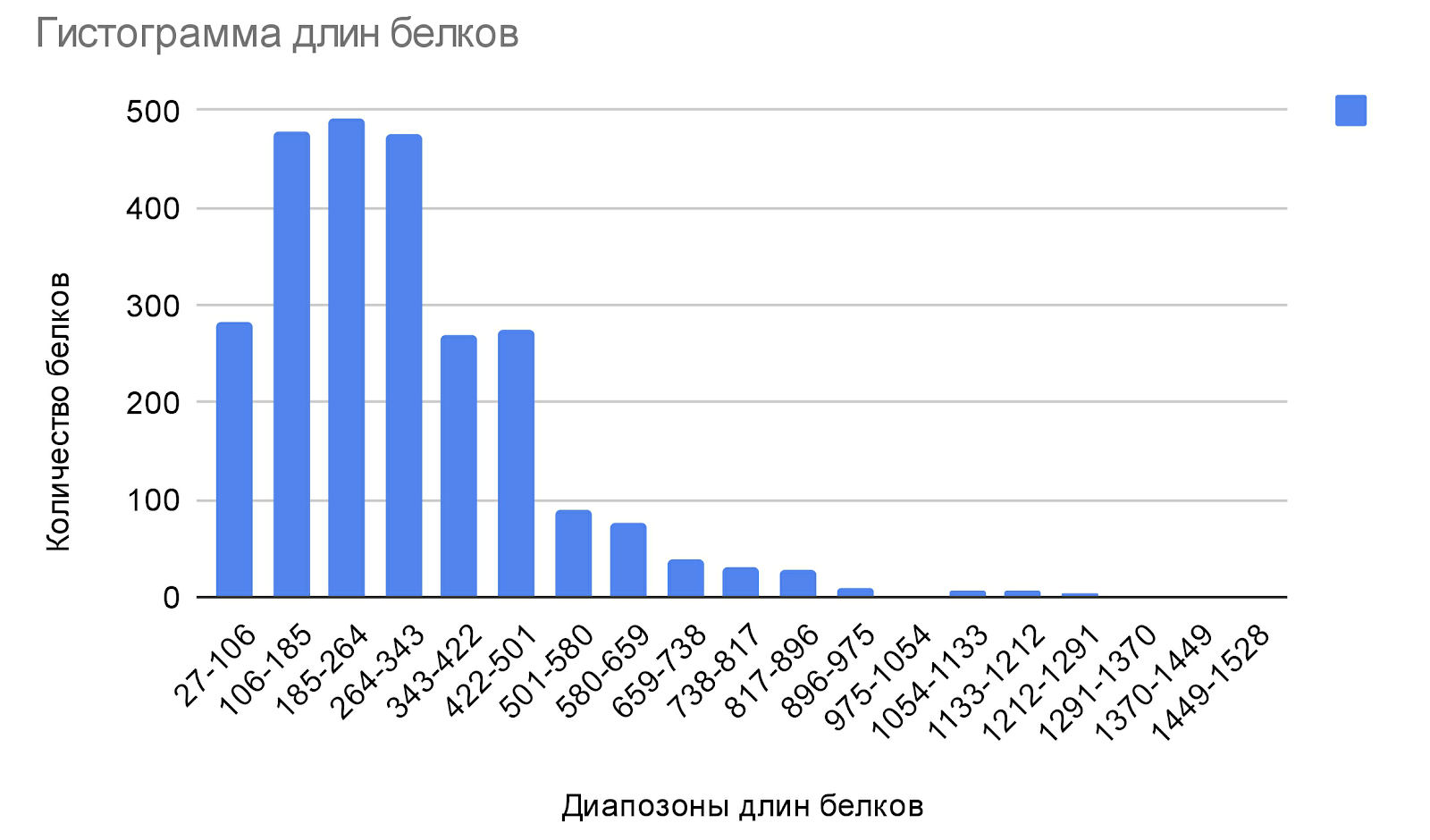
Анализируя гистограмму длин белков (Рис.1), можно заметить, что в среднем белки имеют не очень большую длину, менее 500 аминокислот, а пик приходится на диапазон 185-264 аминокислотных остатка. Лишь 287 белков из 2558 имеет длину большую или равную 500 аминокислотам, а большую 900 аминокислот – всего 25 белков. Также видно, что белков длиной меньшей 100 аминокислот тоже не много (меньше трех сотен).
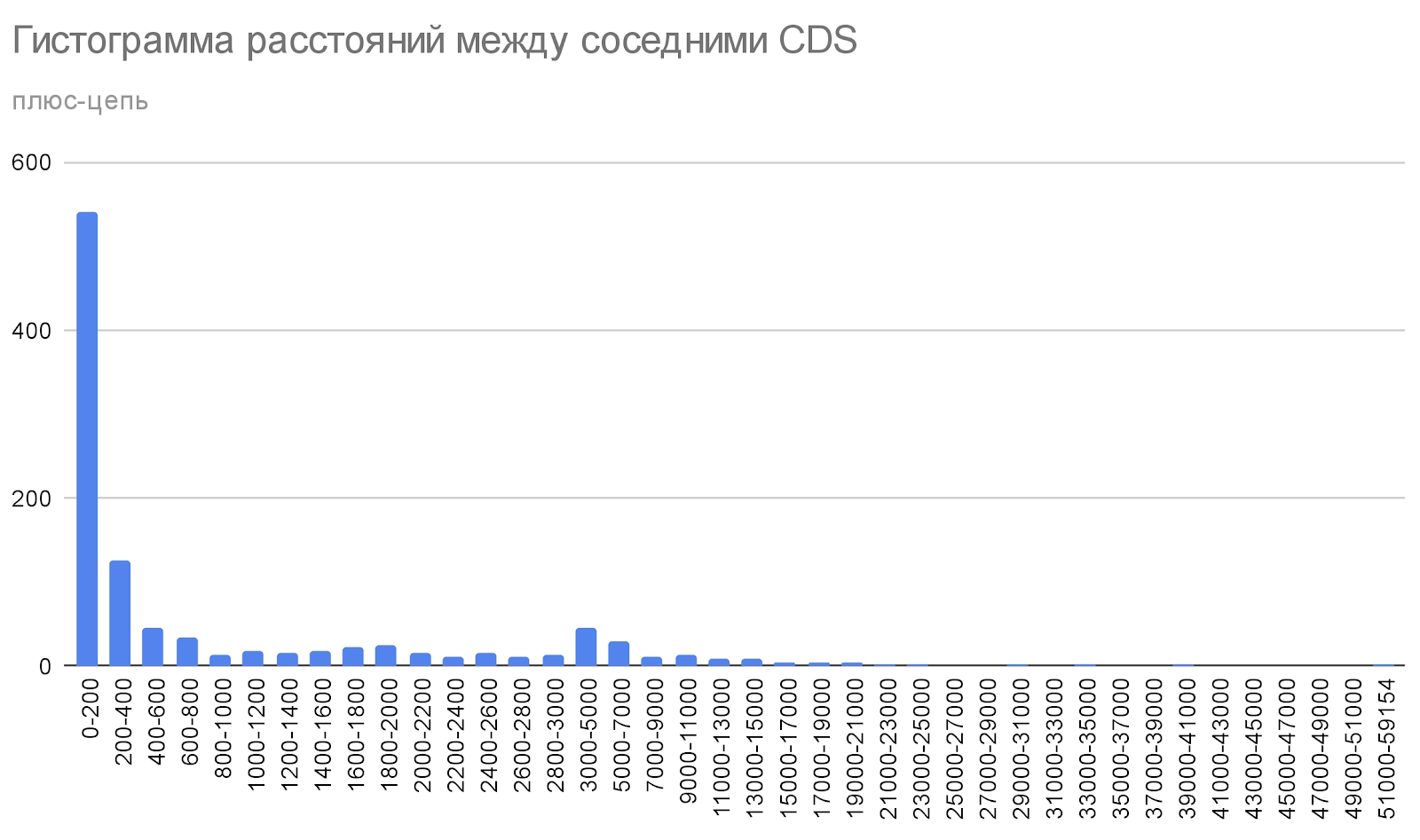
4. РАССТОЯНИЯ МЕЖДУ ПОСЛЕДОВАТЕЛЬНЫМИ CDS И ИХ ПЕРЕСЕЧЕНИЯ
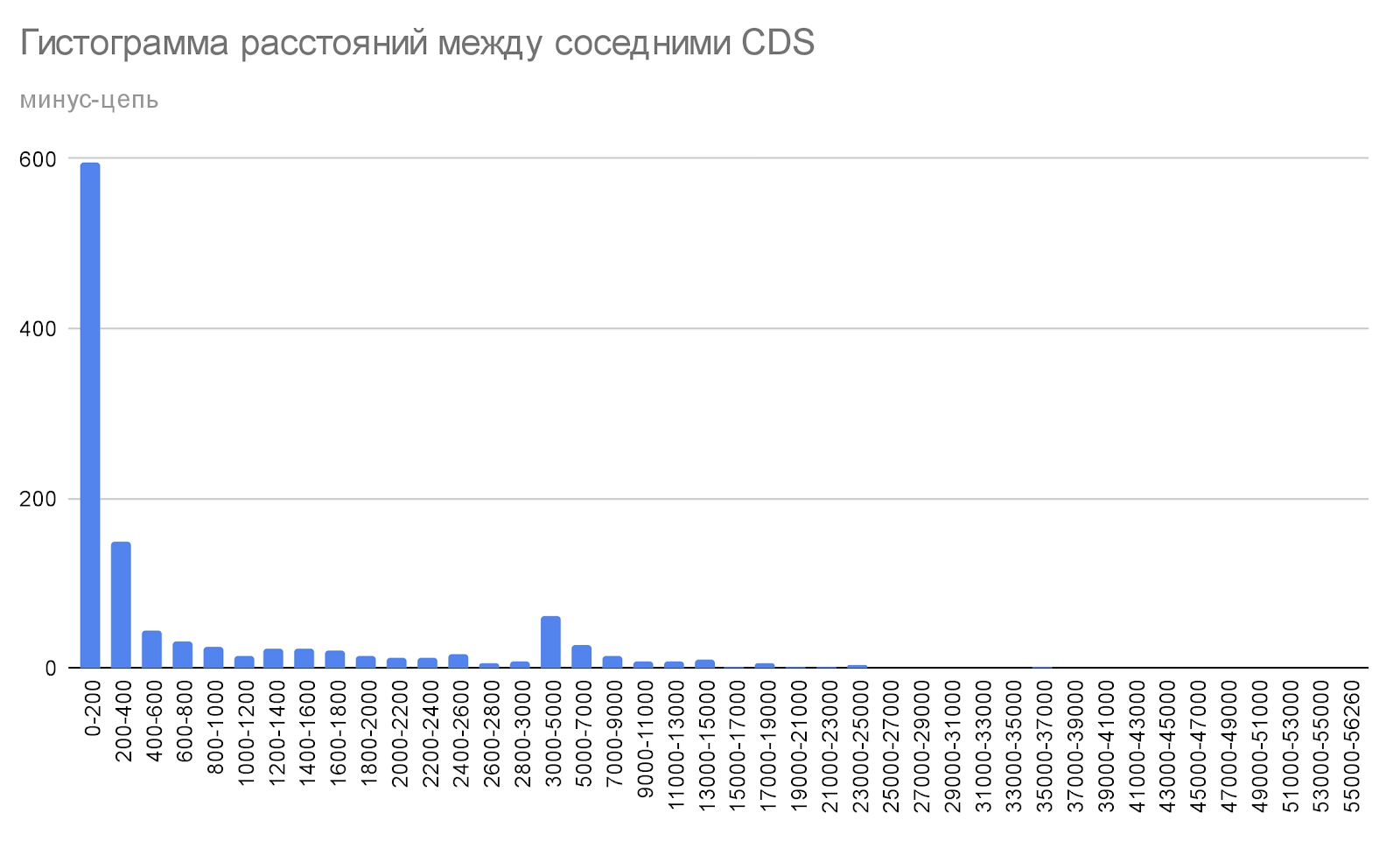
Tetragenococcus koreensis имеет множество открытых рамок считывания, которые находятся на разных расстояниях друг с другом. В основном CDS находятся на расстоянии меньше 200 нуклеотидов, а дальше по ниспадающей. Нет особых отличий между закономерностями распределения расстояний между соседними CDS на плюс-цепи и минус-цепи (Рис. 2).
Также многие CDS перекрываются между собой В основном, те что перекрываются, имеют длину перекрывания 4 п.н (Рис.3). Это связано с тем, что длина перекрывания очень маловероятно будет делиться на три нацело, ведь в таком случае существует опасность, что рибосома проскочит стоп-кодон и синтезируется белок, состоящий из двух, вряд ли выполняющей свои функции правильно. А если длина перекрывания имеет сдвиг рамки считывания, то это увеличит вероятность прерывания трансляции при пропуске стоп-кодона (ведь при сдвиге увеличивается вероятность возникновения стоп-кодона, труднотранслируемых участков и т.д.).
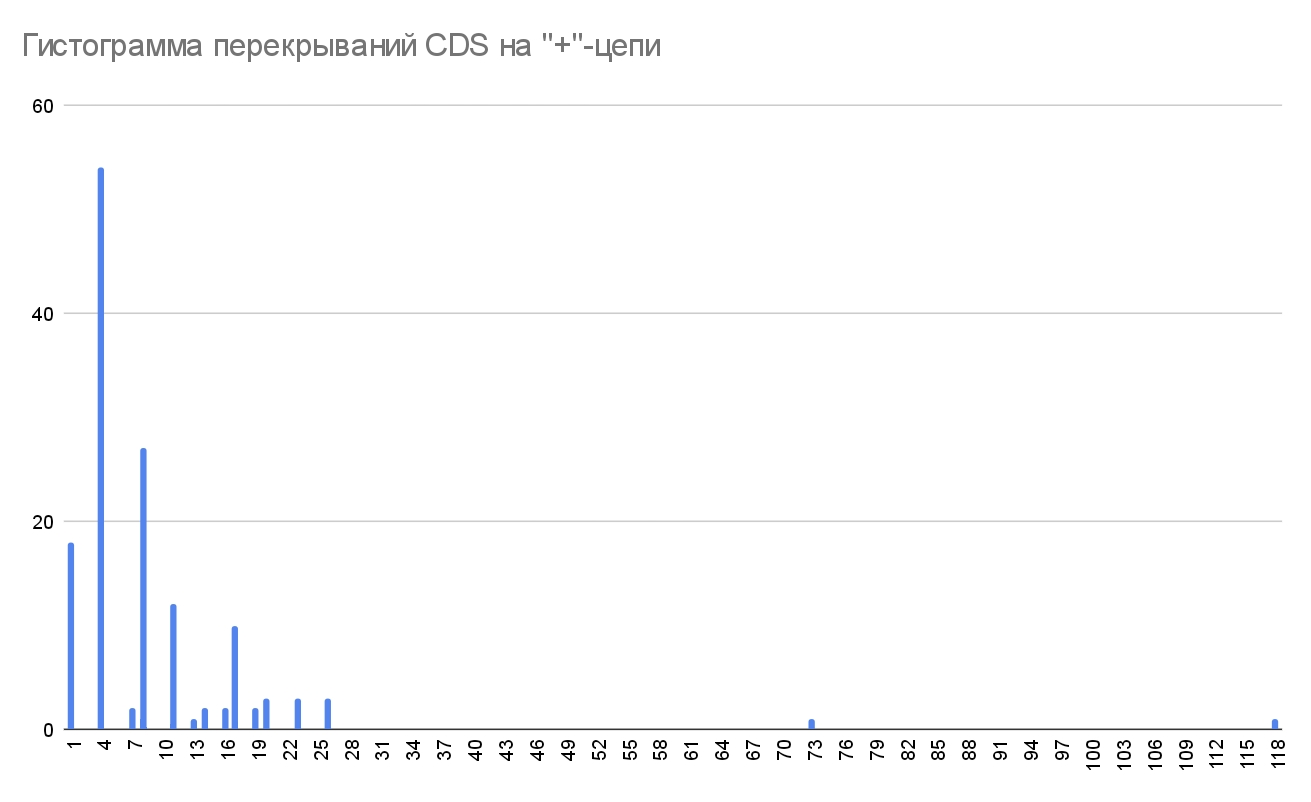
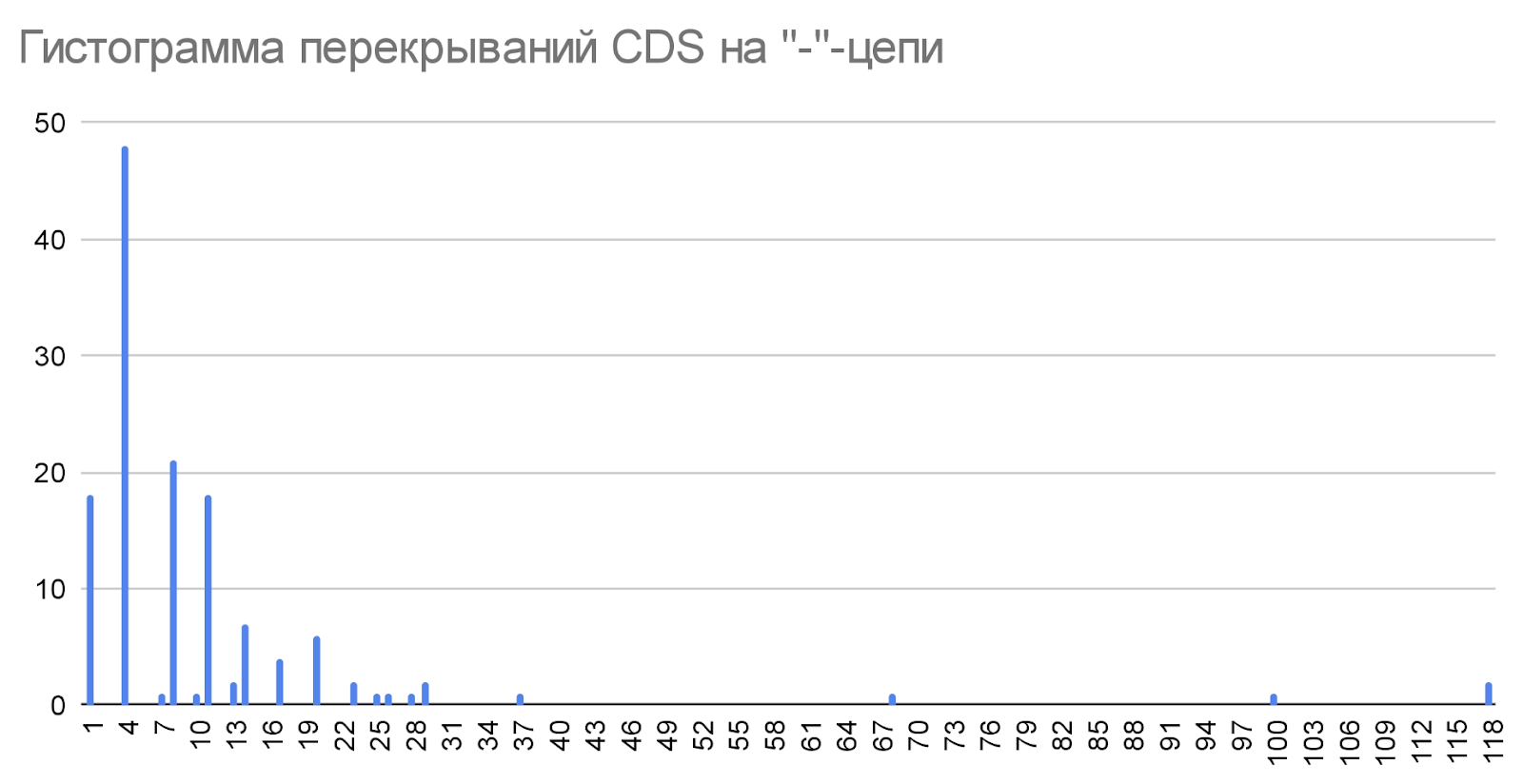
Длины перекрываний на плюс минус цепях имеют схожие паттерны:
- Большая часть перекрываний имеет длину 4п.н.
- Длины 8, 1 и 11 п.н. имеют соответственно 2, 3 и 4 “места” по количеству раз встречаемости.
- Остальные длины перекрываний встречаются не более 10 раз.
И как можно заметить, “лидеры” по числу встречаемости отличаются друг от друга на 3 п.н., ведь это самые помехоустойчивые значения, по названным выше причинам.
Рассмотрим повнимательнее пересечения, которые явно отличаются от других: их длина пересечения больше сотни пар нуклеотидов, а именно 118. На плюс цепи так пересекаются две транспозазы. Возможно это два транспозона, но один вклинился в другой и перемещается вместе с ним. На минус цепи есть два пересечения длиной 118 п.н., одно из них, это пересечение двух N-ацетилтрансфераз семейства GNAT (возможно это два варианта одного гена), участвующих в ацетилировании белков, а второе пересечение также связано с транспозазами.
5. ПРЕДСКАЗАНИЕ ОПЕРОНОВ
Теперь рассмотрим CDS находящихся друг от друга на небольшом расстоянии, или чуть перекрывающиеся с друг другом.
А) В диапазоне 667,207-668,558 п.н. есть два гена, ответственных за метаболизм оротата (то есть метаболизм пиримидинов): orotidine-5'-phosphate decarboxylase, orotate phosphoribosyltransferase. Они перекрываются на 4 п.н. и явно связаны функционально, поэтому и можно предположить, что это оперон.
Тем более на небольшом расстоянии от них (658,830-659,369п.н.) находится еще один ген, участвующий в метаболизме оротовой кислоты: bifunctional pyr operon transcriptional regulator/uracil phosphoribosyltransferase PyrR.
Б) В диапазоне 675,714-682,802 п.н. находится 7 генов, на очень маленьком расстоянии друг от друга, а именно 24, 3, 15, 11, 11, 5, 0 п.н. Этот оперон связан с шикиматным путем, столь необходимым для синтеза ароматических аминокислот, нуклеотидов, фолатов и многого другого (Таблица 4).
| shikimate dehydrogenase | aroE |
| 3-deoxy-7-phosphoheptulonate synthase | aroF |
| 3-dehydroquinate synthase | aroB |
| chorismate synthase | aroC |
| prephenate dehydrogenase | |
| prephenate dehydratase | pheA |
| 3-phosphoshikimate 1-carboxyvinyltransferase | aroA |
| shikimate kinase |
В) До этого мы рассматривали плюс-цепь, теперь рассмотрим и минус-цепь. В диапазоне 1 459 079-1 462 848 п.н. находится 4 гена, расстояния между ними -14, -4, 14 (минус означает, что гены перекрываются). Этот оперон синтезирует целый комплекс белков участвующих в десульфуризации цистеина (Таблица 5).
| Fe-S cluster assembly sulfur transfer protein SufU | sufU |
| cysteine desulfurase | |
| Fe-S cluster assembly protein SufD | sufD |
| Fe-S cluster assembly ATPase SufC | sufC |
Итак, с помощью лишь оценки расстояний между CDS, мы предсказали три важных для бактерии оперона, но точно установить, так ли это помогут более тонкие лабораторные методы.
6. ИССЛЕДОВАНИЕ СОСТАВА НУКЛЕОТИДОВ И ДИНУКЛЕОТИДОВ ПО РЕПЛИКОНАМ
Исследование генома по составу нуклеотидов может дать нам некоторую информацию даже об экологии бактерии. Tetragenococcus koreensis не термофильная бактерия, ведь содержание гуанина и цитозина в ней меньше 37%, а именно 36,92% (Таблица 6).
| количество | частота | |||
|---|---|---|---|---|
| нуклеотид | хромосома | плазмида | хромосома | плазмида |
| A | 857781 | 3205 | 31,52% | 29,00% |
| T | 858458 | 3988 | 31,55% | 36,08% |
| G | 498267 | 1928 | 18,31% | 17,44% |
| C | 506468 | 1931 | 18,61% | 17,47% |
Также видно, что количество пиримидинов не равно количеству пуринов (пиримидинов больше), очень хорошо это видно на примере плазмиды. Наверняка это связано с большой частотой мутаций.
Теперь рассмотрим содержание различных динуклеотидов в репликонах (Таблица 7).
| количество | частота | |||
|---|---|---|---|---|
| динуклеотид | хромосома | плазмида | хромосома | плазмида |
| AA | 237937 | 855 | 9,49% | 8,49% |
| AT | 247784 | 1003 | 9,88% | 9,96% |
| AG | 144359 | 559 | 5,76% | 5,55% |
| AC | 134683 | 443 | 5,37% | 4,40% |
| TA | 205410 | 925 | 8,19% | 9,19% |
| TT | 238387 | 1167 | 9,50% | 11,59% |
| TG | 164353 | 685 | 6,55% | 6,80% |
| TC | 157699 | 687 | 6,29% | 6,82% |
| GA | 153629 | 523 | 6,12% | 5,19% |
| GT | 132879 | 618 | 5,30% | 6,14% |
| GG | 82771 | 329 | 3,30% | 3,27% |
| GC | 115673 | 406 | 4,61% | 4,03% |
| CA | 167787 | 558 | 6,69% | 5,54% |
| CT | 146800 | 675 | 5,85% | 6,70% |
| CG | 93468 | 303 | 3,73% | 3,01% |
| CC | 84613 | 332 | 3,37% | 3,30% |
Термин CpG-островок означает, что при движении от 5' к 3' концу, мы последовательно встречаем цитозин и гуанин. CpG-островки часто выполняют регуляторную функцию.
Рассчитаем теоретическое значений встречаемости CpG-островков:
СрСтеор=0,3692*0,3692*100%=13,63%.
Здесь мы взяли рассчитанное ранее значение, равное содержанию гуанина и цитозина, и рассчитали вероятность встречи сайта, где за цитозином следует гуанин.
СрСпрак=3,73%
То есть, в реальности это значение составляет лишь четверть от ожидаемого. Это связано с высокой скоростью мутации метилированного цитозина и превращения его в тимин. А такие мутации часто разрешаются в сторону АТ-пар. Также это объясняет, почему ТТ-динуклеотидов так много (почти 10%), а CC, GC и других цитозин-содержащих динуклеотидов так мало.
К сожалению, лишь подсчетом нуклеотидов и динуклеотидов в геноме ничего нельзя сказать о их распределении, для этого нужны другие методы.
7. АНАЛИЗ GC-СОСТАВА ПО CDS
Немного о распределении гуанина и цитозина может сказать их распределение по CDS.
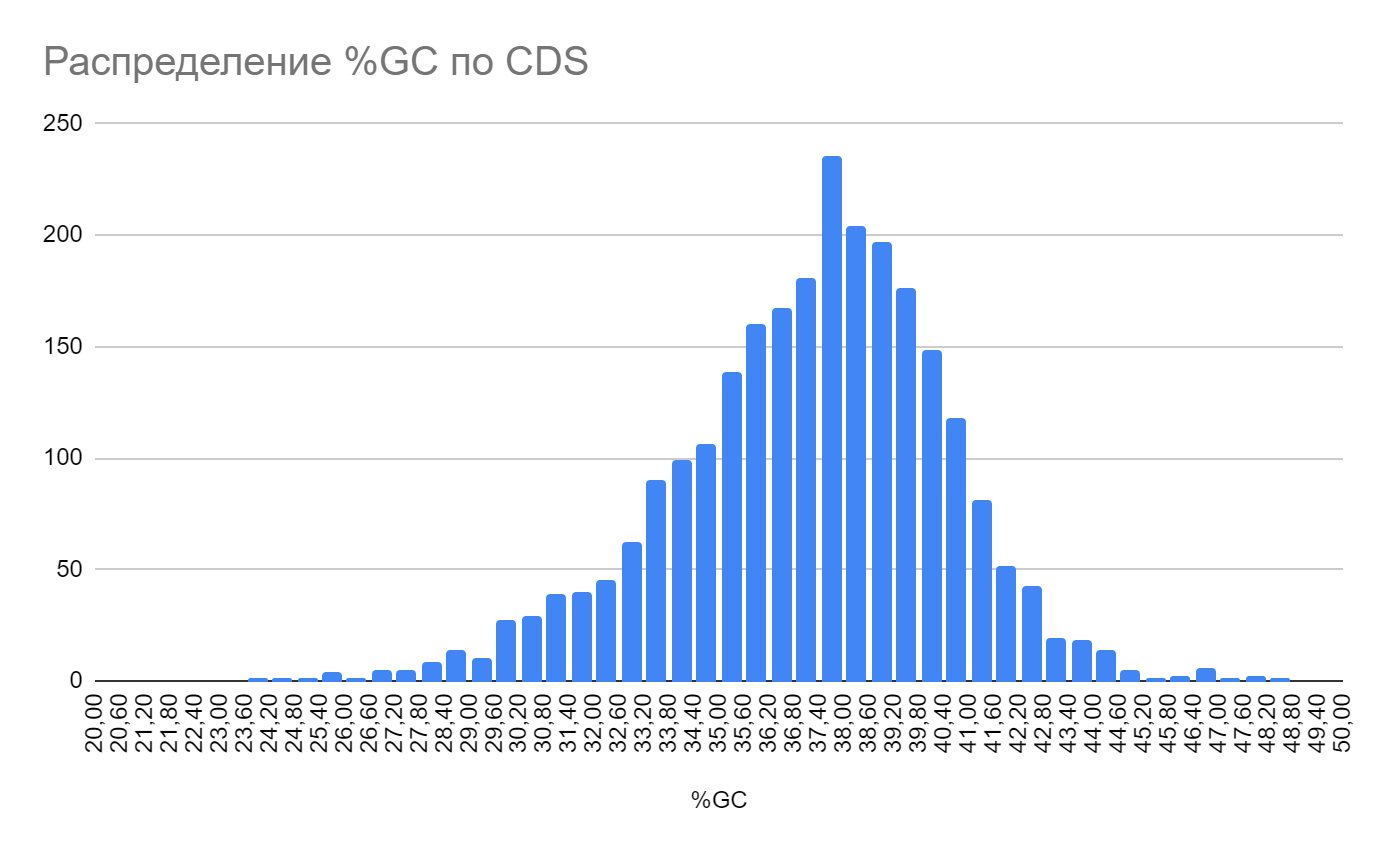
Чаще CDS имеют в своем составе чуть больше гуанина и цитозина нежели по всему геному (~37,5% против 36,92%) (Рис.4).
Это можно объяснить тем, что последовательности CDS более консервативны, поэтому мутации в них проходят реже, и цитозин реже метилириуется, а значит реже превращается в тимин.
Следует отметить, что график распределения напоминает нормальное распределение, за исключением правой стороны от самого большого значения, ведь увеличение содержания гуанина и цитозина в определенном месте – сложный процесс.
8. АНАЛИЗ GC-СОСТАВА ВСЕЙ ХРОМОСОМЫ
Теперь же рассмотрим GC-состав всей хромосомы.
Рассчитав температуру плавления для каждых двадцати нуклеотидов с перекрываниями (то есть, для нуклеотидов 1-20, 2-21, 3-22 и т.д.), можно установить местные отклонения от среднего значения.
Расчет температуры плавления по формуле:
T=4*(G+C)+2*(A+T)
Можно видеть, что график получился вполне равномерный, но есть места, отличающиеся от других (Рис. 5).
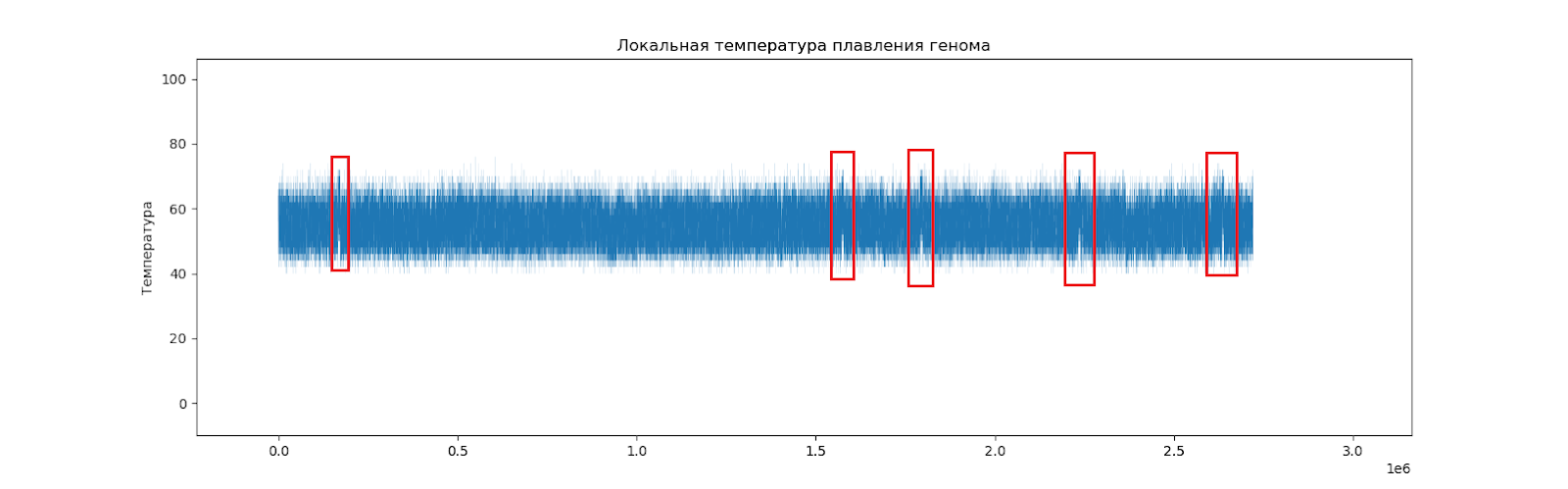
Есть 5 заметных локальных подъемов температуры плавления (Рис.6).
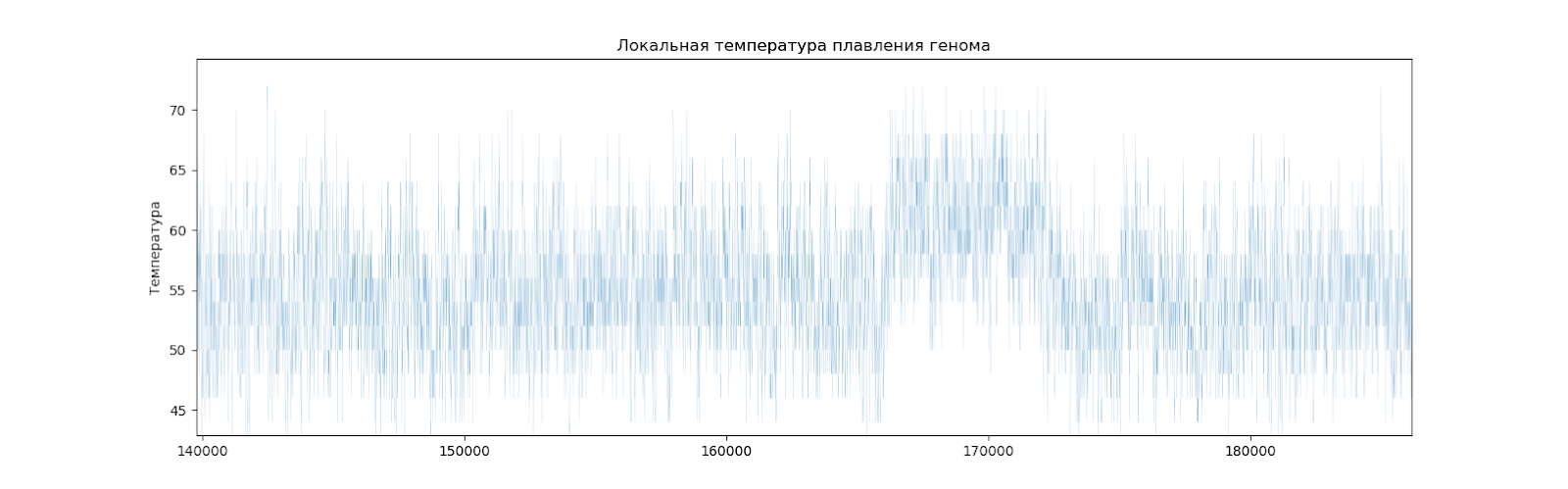
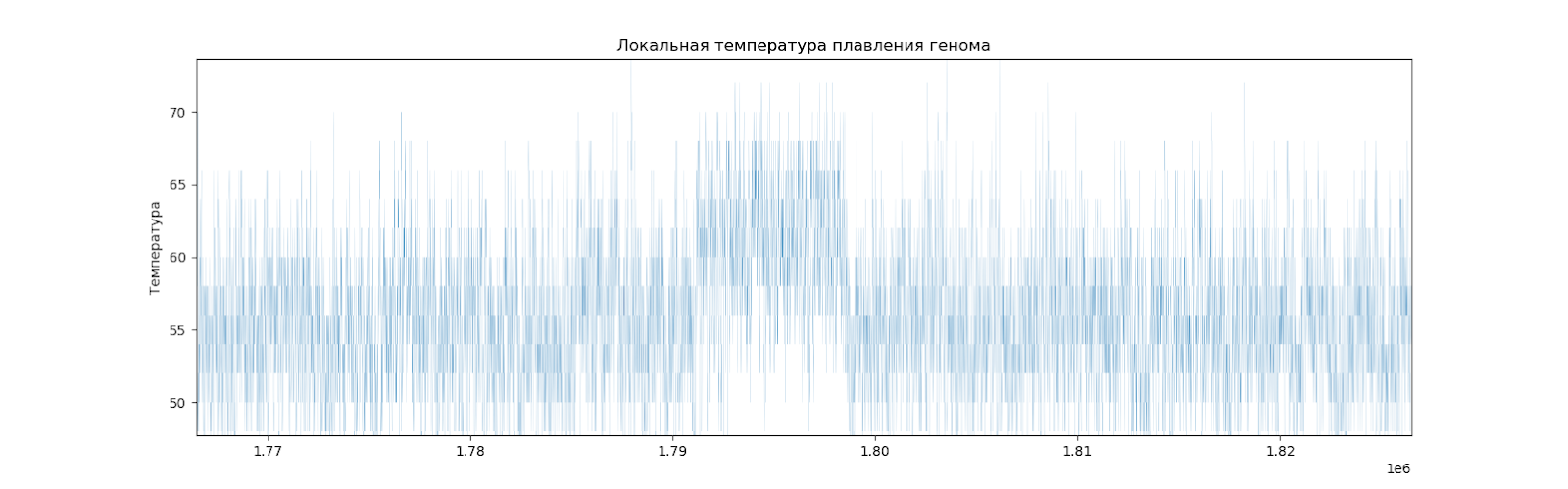
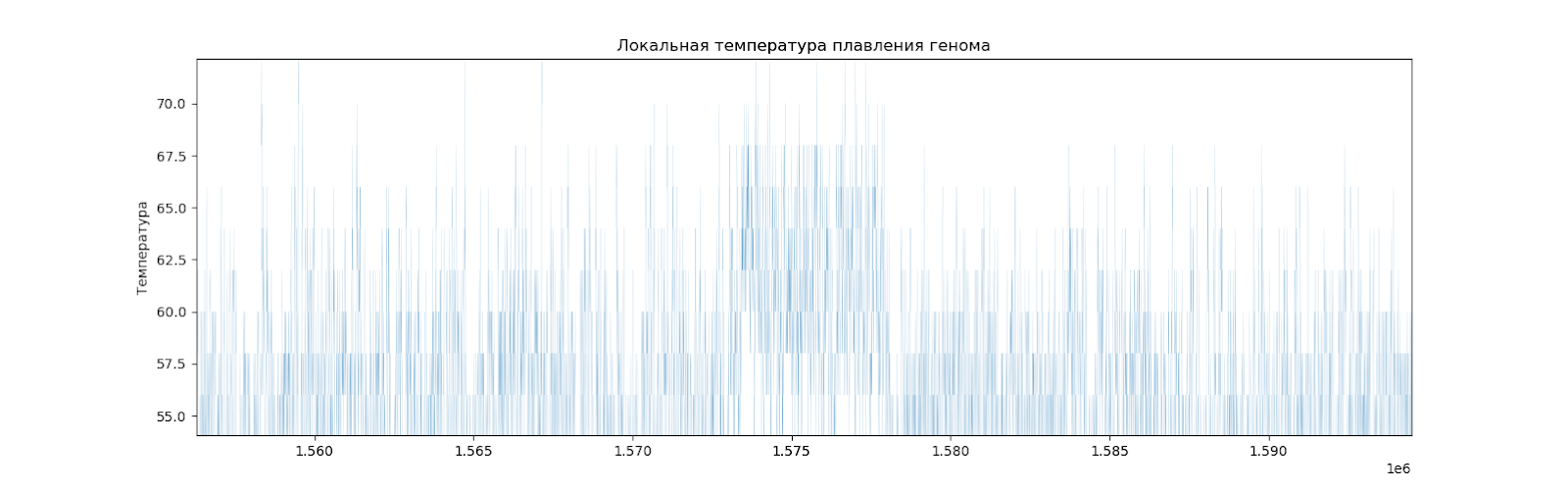
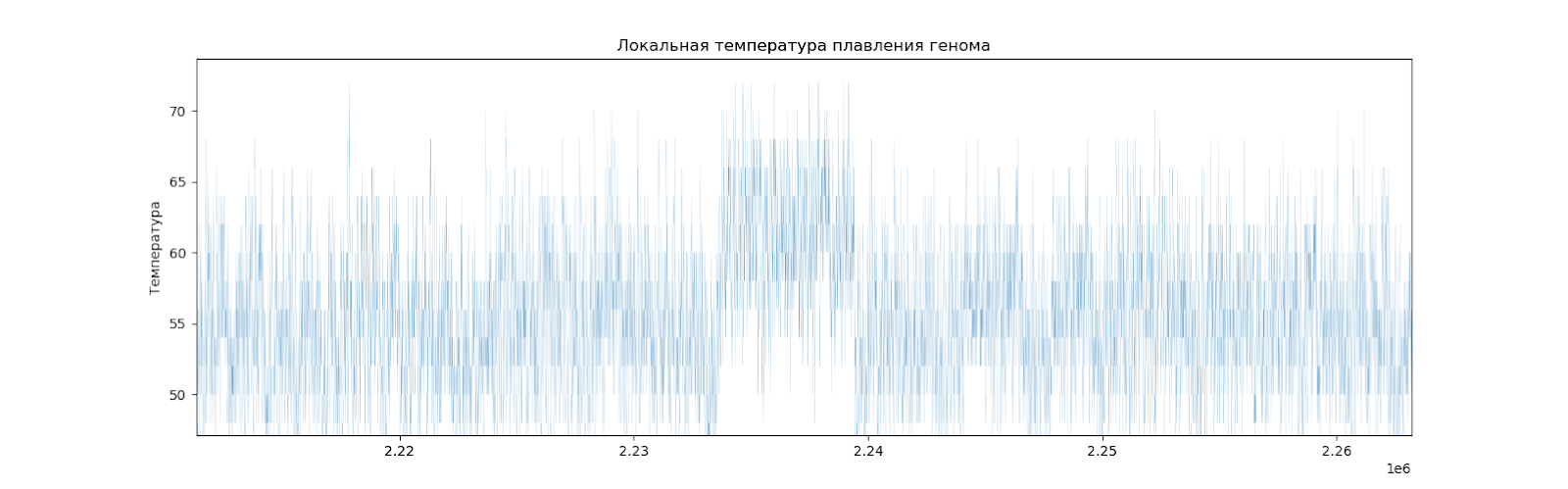
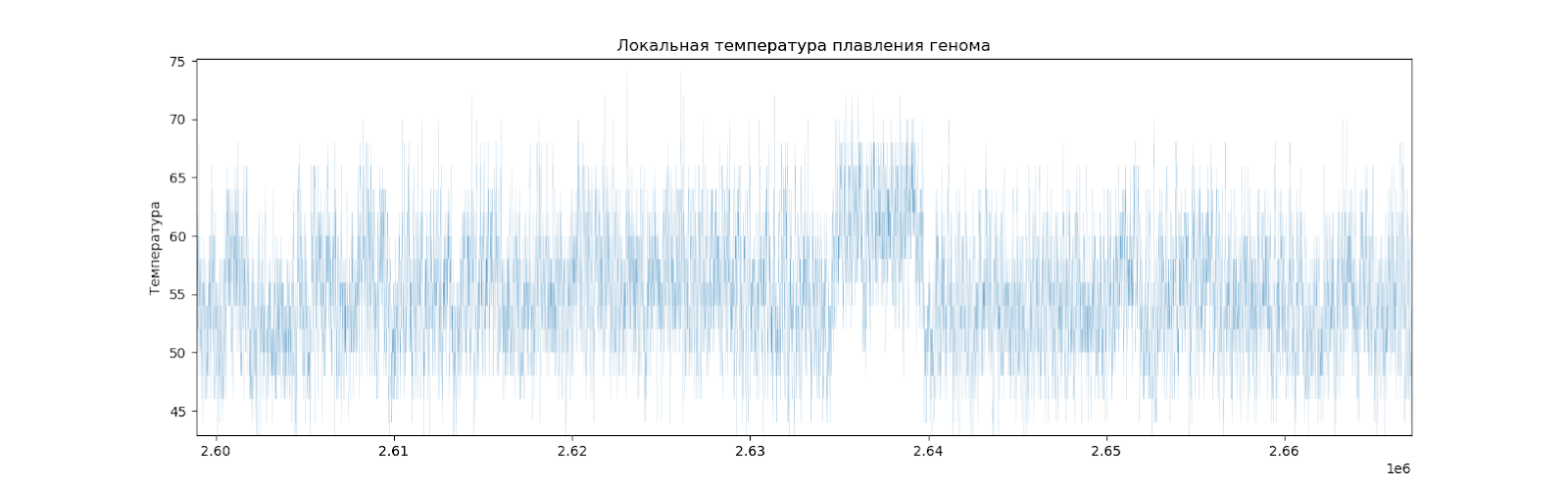
Рассмотрим повнимательнее каждый участок, его длину, и координаты. (Табл. 8).
| участок | примерные координаты | примерная длина |
|---|---|---|
| 1 | 166000-172000 п.н. | 6 Кб |
| 2 | 1573000-1578000 п.н. | 5 Кб |
| 3 | 1792000-1798000 п.н. | 6 Кб |
| 4 | 2234000-2239000 п.н. | 5 Кб |
| 5 | 2635000-2640000 п.н. | 5 Кб |
Известно, что в этих местах нет никаких генов и любых других кодирующих последовательностей. Это может означать, что эти участки заимствованы из генома другого вида.
9.СТАРТ И СТОП КОДОНЫ
Теперь непосредственно обратимся к анализу кодонов самих CDS. Рассмотрим старт и стоп кодоны генов и псевдогенов.
Всего генов 2478, а псевдогенов - 80 (Таблица 1).
В генах большая часть старт-кодонов ATG (Таблица 9).
TTG, CTG, GTG получаются лишь одной мутацией из ATG, поэтому тоже часто встречаются. TTG мог также получатся из-за дупликации T старт-кодоне и может там на самом деле ATTG (тиминовые динуклеотиды нередки у прокариот).[4],[5]
CTG начинается с пиримидина, поэтому встречается так редко, по отношению к предыдущим. [6]
ATT, ATA, ATC тоже получаются лишь одной мутацией из ATG, разницу в их количествах можно объяснить также, как и первых трех старт-кодонов, отличных от ATG.
Бактерия может иметь отличный от ATG старт-кодон для более тонкой регуляции экспрессии генов. Рибосома будет реже узнавать такой не каноничный старт-кодон.
| кодон | гены | псевдогены |
|---|---|---|
| ATG | 2 027 | 47 |
| TTG | 240 | 2 |
| GTG | 172 | 4 |
| ATT | 16 | 3 |
| ATA | 10 | 2 |
| ATC | 7 | 1 |
| CTG | 6 | 0 |
| CAA | 0 | 2 |
| GTT | 0 | 2 |
| TTA | 0 | 2 |
| TTT | 0 | 2 |
| AAA | 0 | 1 |
| AAG | 0 | 1 |
| AAT | 0 | 1 |
| AGA | 0 | 1 |
| AGT | 0 | 1 |
| CGT | 0 | 1 |
| CTT | 0 | 1 |
| GCC | 0 | 1 |
| GCT | 0 | 1 |
| GGC | 0 | 1 |
| GTA | 0 | 1 |
| TAT | 0 | 1 |
| TTC | 0 | 1 |
Для псевдогенов провести анализ трудно, потому что в них происходит множество мутаций. Но всё равно ATG встречается в более половины случаев.
Перейдем к анализу стоп-кодонов (Таблица 10).
| кодон | гены | псевдогены |
|---|---|---|
| TAA | 1 524 | 38 |
| TGA | 472 | 9 |
| TAG | 417 | 16 |
| A | 26 | 2 |
| AA | 26 | 0 |
| GA | 5 | 0 |
| AG | 4 | 0 |
| G | 4 | 0 |
| AAG | 0 | 2 |
| GTT | 0 | 2 |
| TTA | 0 | 2 |
| TTT | 0 | 2 |
| AAC | 0 | 1 |
| AAT | 0 | 1 |
| ATT | 0 | 1 |
| CCG | 0 | 1 |
| GAA | 0 | 1 |
| GAT | 0 | 1 |
| TCA | 0 | 1 |
Первые три стоп-кодона табличные, затем идут не кодоны, а динуклеотиды и нуклеотиды полученные в результате сдвига рамки считывания, а значит в CDS произошла мутация по типу делеции или инсерции.
Все остальные представлены лишь в псевдогенах, возможно получены в результате мутаций.
И следует отметить, что приоритет из трех обычных стоп-кодонов бактерия отдает именно ТАА, а не равное, как можно было бы подумать.
10. АНАЛИЗ ПРИОРИТЕТНЫХ КОДОНОВ
Анализ генома различных живых организмов показывает, что, несмотря на универсальность кодонов, в разных геномах они используются с разной частотой. [7]
Это имеет практическое значение, например, если в бактерию вставить ген человеческого инсулина, помимо всего прочего стоит также оптимизировать кодоны (то есть составить последовательность кодон, кодирующую тот же белок, но состоящую из предпочтительных для бактерии кодонов).
К сожалению, анализ по всем хромосомам затруднен из-за двух вещей, во-первых это наличие псевдогенов с множеством мутаций, во-вторых это из-за наличия CDS, в которых произошла инсерция или делеция.
Поэтому можно проанализировать первые 30 CDS, а затем первые 40 CDS, и посмотреть тенденцию к изменению приоритетности кодонов.
Более приоритетные кодоны даже на таком маленьком количество CDS встречаются на порядок чаще других кодонов.
При сравнении результатов анализа частот кодонов в 30 и 40 CDS, нет никаких противоречий, наоборот, “отрыв” приоритетного кодона от других только увеличивается (см. таблицы S9 сопроводительных материалов).
В Таблице 11 представлены аминокислоты и их кодоны, в порядке убывания приоритетности.
| Аминокислота | Кодоны |
|---|---|
| V | GTT, GTA, GTG, GTC |
| A | GCT, GCA, GCG, GCC |
| G | GGC, GGT, GGA, GGG |
| D | GAT, GAC |
| E | GAA, GAG |
| M | ATG |
| I | ATT, ATC, ATA |
| T | ACA, ACT, ACC, ACG |
| N | AAT, AAC |
| K | AAA, AAG |
| R | CGT, AGA, CGC, CGA, CGG, AGG |
| L | TTA, TTG, СТА, СТТ, CTG, CTC |
| P | ССТ, ССА, СCG, CCC |
| H | CAT, CAC |
| Q | CAA, CAG |
| S | AGT, TCT, TCA, AGC, TCG, TCC |
| F | TTT, TTC |
| Y | TAT, TAC |
| C | TGT, TGC |
| W | TGG |
ЗАКЛЮЧЕНИЕ
Был исследован геном бактерии Tetragenococcus koreensis.
Исследовано количество разных типов генов и их процентное содержание, получена гистограмма длин белков, а также гистограмма GC-состава по CDS. Также исследовано расстояния между CDS на разных цепях. Были описаны некоторые опероны путем оценки расстояний между CDS. С помощью исследования GC-состава по всей хромосоме были предсказаны участки генома, которые скорее всего были заимствованы. Также было подсчитано количество стоп-кодонов и старт-кодонов. Была исследована приоритетность кодонов в CDS.
БЛАГОДАРНОСТИ
Хочу выразить благодарности Андрею Владимировичу Алексеевскому, Александру Сергеевичу Спирину, Ивану Сергеевичу Русинову, Даниилу Хлебникову и остальным преподавателям за скорую помощь и понятные объяснения.
А также Федору Павличенко, Юле Шигаевой, Виталию Гагарочкину, Всеволоду Масленикову, Даниилу Нагорному за моральную поддержку и возможность обсудить результаты.
СОПРОВОДИТЕЛЬНЫЕ МАТЕРИАЛЫ
S1. Таблица с числом и длиной генов, псевдогенов, разных типов РНК: percents of length.
S2. Сайт с данными о сборки генома Tetragenococcus koreensis: https://www.ncbi.nlm.nih.gov/datasets/genome/GCF_003795145.1/.
S3. Таблица с гистограммами распределения длин белков и GC-состава по CDS: CDS from genome of Tetragenococcus koreensis.
S4. Таблица с анализом пересечений CDS и расстояний между ними: Analyse of CDS.
S5. Два конвейера в терминале, получающих на вход последовательность генома Tetragenococcus koreensis и возвращающих один из репликонов.
- Конвейер, возвращающий файл с последовательностью хромосомы:
grep -B1000000000000000000000 '>NZ_CP027787.1 Tetragenococcus koreensis strain KCTC 3924 plasmid pTK, complete sequence' < GCF_003795145.1_ASM379514v1_genomic.fna | head -n-1 | tail -n+2 > GC_chromosome.txt - Конвейер, возвращающий файл с последовательностью плазмиды:
grep -A10000000000000000000 '>NZ_CP027787.1 Tetragenococcus koreensis strain KCTC 3924 plasmid pTK, complete sequence' < GCF_003795145.1_ASM379514v1_genomic.fna | grep -v > 'NZ_CP027787.1 Tetragenococcus koreensis strain KCTC 3924 plasmid pTK, complete sequence' > plasmid.txt
S6. Ссылка на коллаб, с кодами на языке программирования Python, необходимых для выполнения поставленных задач: Мини-обзор.коды.
Описание кодов:
- Код получает на вход последовательность хромосомы, выдает количество нуклеотидов и динуклеотидов в ней.
- Код получает на вход последовательность плазмиды, выдает количество нуклеотидов и динуклеотидов в ней.
- На вход дается 30 первых CDS, а на выходе получается частота использования кодонов.
- На вход дается 40 первых CDS, а на выходе получается частота использования кодонов.
- Код получает на вход последовательность хромосомы, выдает график локальных температур плавления каждого участка хромосомы длины 20 нуклеотидов. Результат выдачи кода анализировался с помощью средств предоставленных интерфейсом matplotlib в VSCode, так там можно определять координаты участков.
S7. Следующие конвейеры получают на вход файл с последовательностями CDS.
- Конвейер, считающий количество старт-кодонов во всех CDS:
grep -A 1 '^>' < GCF_003795145.1_ASM379514v1_cds_from_genomic.fna | grep -v '^>' | grep -v '^-' | cut -c1-3 | sort | uniq -c > allstarts.txt - Конвейер считающий количество старт-кодонов в псевдогенах:
grep -A 1 'pseudo=true' <GCF_003795145.1_ASM379514v1_cds_from_genomic.fna | grep -v '^>' | grep -v '^-' | cut -c1-3 | sort | uniq -c > pseudostarts.txt - Конвейеры, считающий количество стоп-кодонов во всех CDS:
grep -B 1 '^>' < GCF_003795145.1_ASM379514v1_cds_from_genomic.fna | grep -v '^[>-]' > allstops2.txt tail -n 1 < GCF_003795145.1_ASM379514v1_cds_from_genomic.fna >> allstops2.txt rev < allstops2.txt | cut -c1-3 | rev | sort | uniq -c > allstops.txt - Конвейер считающий количество стоп-кодонов в псевдогенах:
grep -B1 '>' < GCF_003795145.1_ASM379514v1_cds_from_genomic.fna | grep -A2 pseudo=true | grep -v '^-' | grep -v '^>' | rev | cut -c 1-3 | rev | sort | uniq -c > pseudostops.txt
S8.Следующие конвейеры получают на вход файл с последовательностями CDS.
- Отбор первых 30 CDS:
grep -B100000000000000000000 '1_31 '< GCF_003795145.1_ASM379514v1_cds_from_genomic.fna | grep -v '>' | tr -d \\n > CDS.txt - Отбор первых 40 CDS:
grep -B100000000000000000000 '1_41 ' < GCF_003795145.1_ASM379514v1_cds_from_genomic.fna | grep -v '>' | tr -d \\n > CDS2.txt
S9
| Аминокислота | Кодон | Частота в 30 CDS | Частота в 40 CDS |
|---|---|---|---|
| V | GTT | 228 | 295 |
| V | GTA | 155 | 196 |
| V | GTG | 105 | 135 |
| V | GTC | 96 | 113 |
| A | GCT | 217 | 274 |
| A | GCA | 209 | 257 |
| A | GCC | 86 | 102 |
| A | GCG | 85 | 110 |
| G | GGC | 182 | 210 |
| G | GGT | 180 | 209 |
| G | GGA | 127 | 172 |
| G | GGG | 73 | 95 |
| D | GAT | 351 | 447 |
| D | GAC | 168 | 186 |
| E | GAA | 487 | 641 |
| E | GAG | 124 | 166 |
| M | ATG | 182 | 235 |
| I | ATT | 371 | 460 |
| I | ATC | 177 | 210 |
| I | ATA | 73 | 94 |
| T | ACA | 209 | 250 |
| T | ACT | 135 | 172 |
| T | ACC | 100 | 113 |
| T | ACG | 89 | 112 |
| N | AAT | 316 | 383 |
| N | AAC | 153 | 177 |
| K | AAA | 501 | 656 |
| K | AAG | 119 | 148 |
| R | CGT | 109 | 150 |
| R | AGA | 63 | 79 |
| R | CGC | 55 | 70 |
| R | CGA | 31 | 49 |
| R | CGG | 29 | 35 |
| R | AGG | 20 | 29 |
| L | TTA | 285 | 394 |
| L | TTG | 144 | 174 |
| L | CTA | 106 | 129 |
| L | CTT | 81 | 112 |
| L | CTG | 51 | 69 |
| L | CTC | 18 | 22 |
| P | CCT | 108 | 136 |
| P | CCA | 98 | 119 |
| P | CCG | 42 | 58 |
| P | CCC | 28 | 38 |
| H | CAT | 98 | 136 |
| H | CAC | 53 | 62 |
| Q | CAA | 309 | 411 |
| Q | CAG | 83 | 111 |
| S | AGT | 142 | 172 |
| S | TCT | 104 | 130 |
| S | TCA | 103 | 130 |
| S | AGC | 90 | 101 |
| S | TCG | 48 | 56 |
| S | TCC | 35 | 43 |
| F | TTT | 297 | 351 |
| F | TTC | 59 | 73 |
| Y | TAT | 222 | 288 |
| Y | TAC | 105 | 120 |
| C | TGT | 30 | 49 |
| C | TGC | 12 | 22 |
| W | TGG | 86 | 91 |
| Stop | TAA | 18 | 24 |
| Stop | TGA | 7 | 10 |
| Stop | TAG | 5 | 6 |
ЛИТЕРАТУРА
1.Amadoro C, Rossi F, Piccirilli M, Colavita G.
Tetragenococcus koreensis is part of the microbiota in a traditional Italian raw fermented sausage. Food Microbiol. 2015 Sep;50:78-82. doi: 10.1016/j.fm.2015.03.011. Epub 2015 Apr 8. PMID: 25998818.
2.Lee M, Kim MK, Vancanneyt M, Swings J, Kim SH, Kang MS, Lee ST. Tetragenococcus koreensis sp. nov., a novel rhamnolipid-producing bacterium. Int J Syst Evol Microbiol. 2005 Jul;55(Pt 4):1409-1413. doi: 10.1099/ijs.0.63448-0. PMID: 16014460.
3. Abdel-Mawgoud AM, Lépine F, Déziel E.
Rhamnolipids: diversity of structures, microbial origins and roles. Appl Microbiol Biotechnol. 2010 May;86(5):1323-36. doi: 10.1007/s00253-010-2498-2. Epub 2010 Mar 25. PMID: 20336292; PMCID: PMC2854365.
4.P E Gibbs, B J Kilbey, S K Banerjee, C W Lawrence
The frequency and accuracy of replication past a thymine-thymine cyclobutane dimer are very different in Saccharomyces cerevisiae and Escherichia coli.
J Bacteriol. 1993 May;175(9):2607–2612. doi: 10.1128/jb.175.9.2607-2612.1993
5.P E Gibbs, C W Lawrence
U-U and T-T cyclobutane dimers have different mutational properties
Nucleic Acids Res 1993 Aug 25;21(17):4059-65. doi: 10.1093/nar/21.17.4059.
6.Cherrak Y, Salazar MA, Näpflin N, Malfertheiner L, Herzog MK, Schubert C, von Mering C, Hardt WD.
Non-canonical start codons confer context-dependent advantages in carbohydrate utilization for commensal E. coli in the murine gut. Nat Microbiol. 2024 Oct;9(10):2696-2709. doi: 10.1038/s41564-024-01775-x. Epub 2024 Aug 19. PMID: 39160293; PMCID: PMC11445065.
7.H Grosjean, W Fiers
Preferential codon usage in prokaryotic genes: the optimal codon-anticodon interaction energy and the selective codon usage in efficiently expressed genes
Gene. 1982 Jun;18(3):199-209. doi: 10.1016/0378-1119(82)90157-3.