На данной странице представлен практикум по созданию и анализу файлов с последовательностями ДНК, полученных на основании работы с хроматограммами из капиллярного секвенатора.
1) Получение последовательностей ДНК на основании данных, полученных из капиллярного секвенатора. Отчёт о проблемах при чтении хроматограмм
Для анализа качества хроматорграмм, полученных капиллярным секвенатором, и создания консенсусной последовательности, были загружены файлы прямого и обратного прочтений.
Параметры хроматограммы:
Параметры прямой хроматограммы (32_F.ab1):
- Длина прочтения: 376 нуклеотидов
- GC-состав: 58.24%
- Визуально определенный нечитаемый участок: 1-16 со стороны 5'-конца; 374-376 со стороны 3'-конца
- Уровень шума примерно 10%
Параметры обратной хроматограммы (32_R.ab1):
- Длина прочтения: 386 нуклеотидов
- GC-состав: 58.55%
- Визуально определенный нечитаемый участок: 1-24 со стороны 5'-конца; 382-386 со стороны 3'-конца
- Уровень шума примерно 10%
Сборка консенсуса:
Для создания первичного консенсуса был использован инструмент выравнивания прочтений на референсную последовательность в программе Ugene. В качестве референса была взята одна из последовательностей (32_F.ab1),
относительно которой были выровнены изучаемые прочтения. Полученный консенсус считаю первичным, он был выгружен и использован в качестве референсной последовательности в следующем выравнивании с теми же ридами. Полученный контиг (без корректировки) можно загрузить в формате fasta по
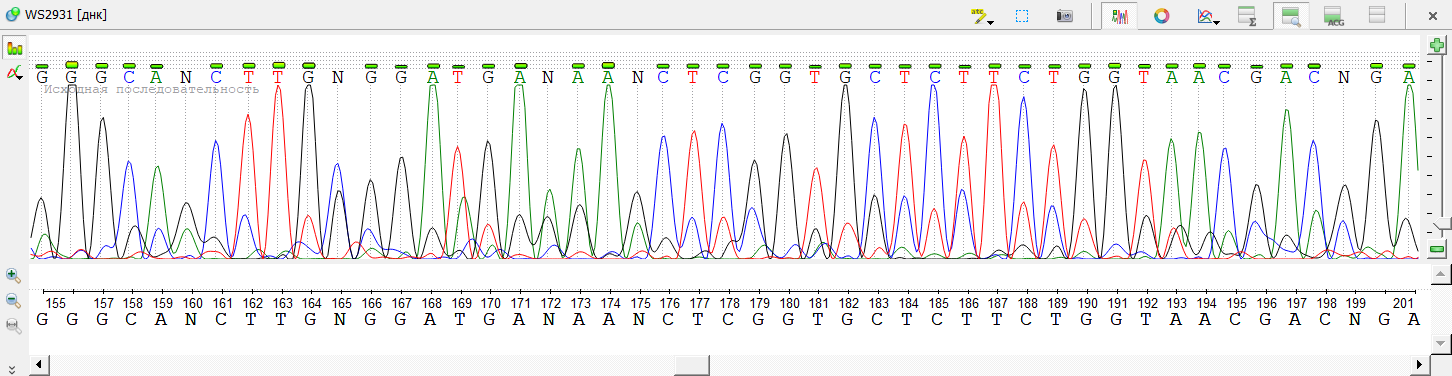
ссылке, а также увидеть на рисунке 1; консенсус данного выравнивания считаю вторичным, его можно загрузить по ссылке.
Общая длина выравнивания: 409 нуклеотидов; длина перекрывающегося участка: 300 нуклеотидов. При создании контига Ugene автоматически обрезает нечитаемые концы:
- Для 32_F.ab1 20 нуклеотидов c 5'-конца и 1 с 3'-конца;
- Для 32_R.ab1 27 нуклеотидов c 5'-конца и 1 с 3'-конца
Несмотря на то, что автоматическое определение нечитаемых концевых участков прочтений более сторго, т.е. обрезает большие фрагменты, в сравнении с визуальной оценкой, различия у этих 2 методов в данном случае суммарно меньше 10 нуклеотидов, что не является критичным для аннотации ридов.
Далее производилась корректировка аннотации хроматограммы и создание более точного консенсуса с учетом знания прямого и обратных прочтений. Некоторые проблемные места описаны в следующем пункте данного упражнения. Итоговый консенсус: ссылка; проект в Ugene: ссылка.

Проблемные места хроматограммы:

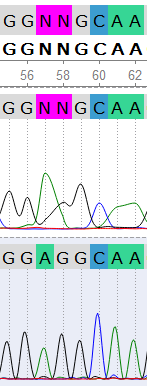
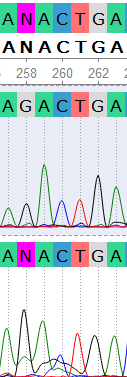
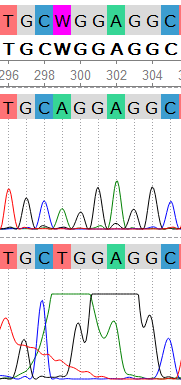
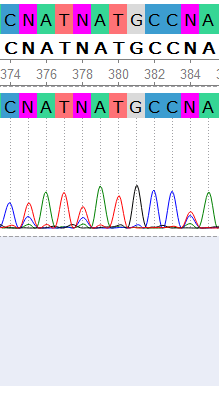
Кроме вышеперечисленных, были отрецензированы все проблемные нуклеотды в данном выравнивании. С результатами составления консенсуса можно ознакомиться:
- В проекте Jalview. Первая строка - консенсус, две другие - риды. Все нуклеотиды, относительно которых принимались какие-либо решения изменены на строчные.
- В проекте Ugene. Первые два файла - прямая и обратная хроматограммы; третий файл - выровненный контиг из этих ридов. Все проблемные нуклеотиды также отрецензированы.
- Консенсус в формате fasta.
2) Нечитаемые фрагменты хроматограммы:
Участки хроматограмм могут быть нечитаемыми по разным причинам, две из которых будут разобраны в данном упражнении:
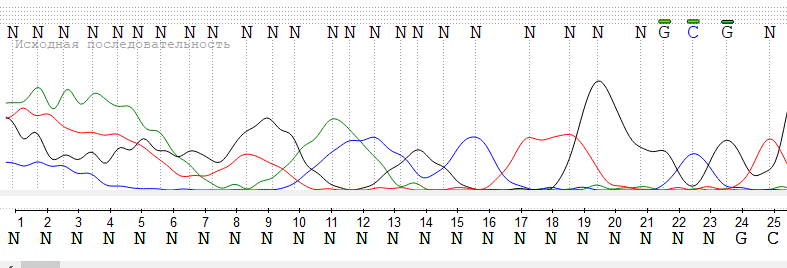
В данном случае приведен участок с начала хроматограммы, где помимо изучаемого образца фиксируется свечение отдельных нуклеотидов, флуорофоров и других неспецифичных коротких последовательностей, которые сильно затрудняют расшифровку хроматограммы.
На этой хроматограмме видно характер распределения пиков, когда в изучаемой последовательности происходит инсерция-делеция. Этот участок находится посередине хроматограммы, и можно увидеть момент, когда начинается несовпадение пиков. В данном случае индель величиной 1 нуклеотид.