На данной странице представлен практикум по описанию G-квадруплексного сигнала, а также построению и проверке позиционно весовой матрицы (PWM) для последовательности Козак человека. Скрипты были написаны в соавторстве с Гуковым Борисом и Литвиновой Анастасией.
1) Описание G-квадруплексного сигнала:
G-квадруплексы (G4) представляют собой разновидность неканонической четырехцепочечной ДНК, которые формируются гуанин-богатыми последовательностями и складываются в многоуровневую (минимально 3 уровня) конструкцию, состоящую из G-тетрад (рис. 1, 2). В большинстве случаев G4 мотивы локализованы в консервативных регуляторных участках генома, в том числе в промоторах онкогенов, влияя на их уровень экспрессии. Способность данных последовательностей формировать G4 в геноме сильно снижена из-за термодинамической нестабильности, приводящей к преимущественному образованию двуспиральной ДНК. На равновесие дуплекс-квадруплекс может оказывать влияние большое количество факторов: длина петель между G-тетрадами, наличие стабилизирующих белков и низкомолекулярных лигандов, связывающихся с квадруплексом. Смещение данного равновесия в сторону образования квадруплекса влияет на различные клеточные процессы, в том числе на канцерогенез, т.к. затрудняет связывание транскрипционных факторов с промотором. Минимальная последовательность, необходимая для формирования G-квадруплекса: NGGGNGGGNGGGNGGGN, где N - один или несколько неклеотидов. Сигнал адресован различным транскрипционным факторам и другим белковым молекулам и комплексам, участвуя в их взаимодействии с ДНК и РНК. В зависимости от типа квадруплекса (рис. 3) и конкретного белка данное взаимодействие упрощается или наоборот усожняется. Эффективность сигнала сильно зависит от клеточных условий и низкомолекулярных лигандов, взаимодействующих с квадруплексом. Так, одновалентные и двухвалентные ионы металлов, а также лиганды с ароматической р-системой стабилизируют квадруплексы, снижая уровень экспрессии, если данный квадруплекс находится в промоторе. Это дает простор для исследований различных низкомолекулярных соединений и их влиянию на различные квадруплексы, как способ борьбы с определенными видами раковых заболеваний.
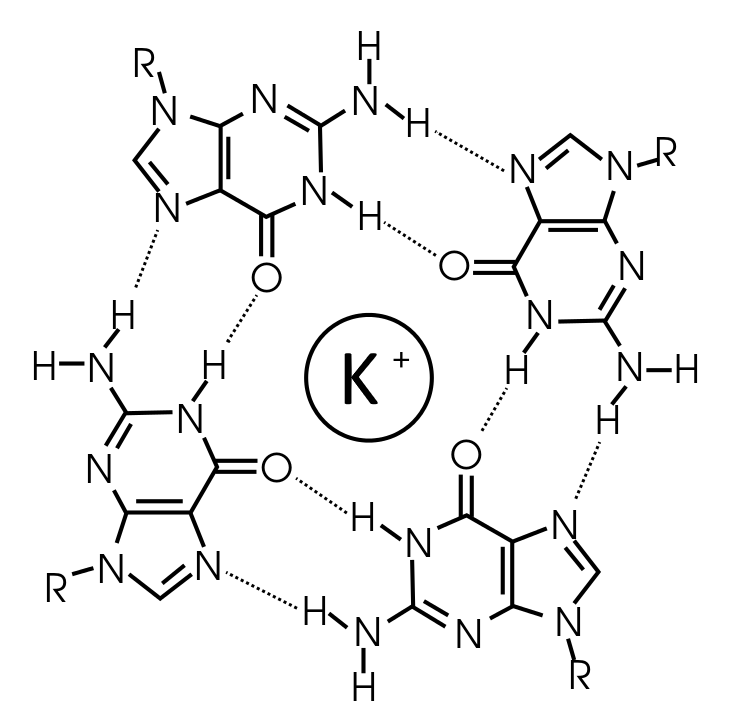

2) Построение позиционно весовой матрицы (PWM) для последовательности Козак:
Для получения последовательностей, в которых в дальнейшем будет искаться послндовательность Козак, случайным образом из таблицы с генами были случайным образом выбраны 195 строк, относящихся к 9 хромосоме человека. С их списком можно ознакомиться по ссылке. Далее с помощью скрипта из данных последовательностей были вырезаны участки длины 13: 7 нуклеотидов до старт-кодона, 3 нуклеотида старт-кодона и 3 нуклеотида после. В скрипте используются множества, т.к. опытным путем было обнаружено, что если этого не делать в выравнивании обнаруживаются много повторяющихся последовательностей (возможно, мне не стоило этого делать, но, как мне кажется данные повторы обусловлены неверной аннотацией генов, а не высокой консервативностью в данных позициях). С полученным выравниванием можно ознакомиться по ссылке, в нем 167 последовательностей.
Для получения отрицательного контроля был выполнен скрипт, который из тех же генов, что были взяты для получения выравнивания, вырезает последовательности с подпоследовательностью ATG в 8-10 позициях, но не относящейся к старт-кодону. Это было сделано за счет сдвига рамки поиска подстроки ATG от начала гена (thikstart) на 10 нуклеотидов. Здесь также использовались множества. С полученными последовательностями можно ознакомиться по ссылке, их получилось 153.
Для получения GC состава 9 хромосомы человека был написан скрипт, с помощью которого было получено значение 40,4%.
Для построения PWM, вычисления среднего веса последовательностей для положительного и отрицательного контроля и визуализации полученных данных был написан скрипт, который делит полученные 167 последовательностей на 2 группы: учебная объемом 65 последовательностей и тестовая объемом 102 последовательности. На основании учебной выборки строится матрица PWM:
1 2 3 4 5 6 7 8 9 10 11 12 13
A -0.184 0.086 -0.470 0.132 0.260 -0.067 -0.391 1.213 -5.270 -5.270 -0.391 -0.067 -0.317
G -0.098 0.359 0.458 -0.184 0.505 -0.278 0.124 -4.890 -4.890 1.585 1.023 -0.184 0.671
T -0.317 -0.391 -0.391 -0.871 -1.003 -0.124 -2.868 -5.270 1.213 -5.270 -1.552 -0.317 -0.556
C 0.549 -0.098 0.359 0.591 -0.184 0.410 0.995 -4.890 -4.890 -4.890 -0.184 0.505 0.055
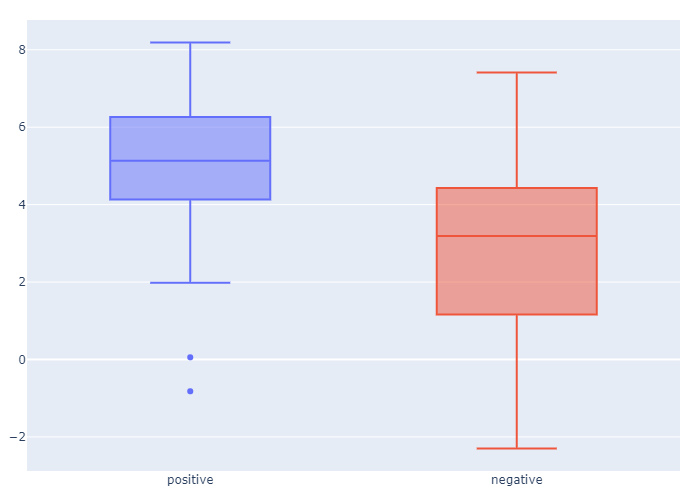
Далее этим же скиптом с помощью данной матрицы был определен вес для отрицательного контроля и тестовой выборки и построены бокс-плоты для визуализации различий в данных грппппах (Рис. 1). Как можно увидеть, средний вес последовательности сильно отличается у изучаемых последовательностей, что говорит о том, что PWM составленна корректно.
3) Подсчет информационного содержания и создание Logo:
Для подсчета информационного содержания был написан скрипт, который на основании учебной выборки определяет информационное содержание каждого нуклеотида в каждой позиции. Матрица информационного содержания:
1 2 3 4 5 6 7 8 9 10 11 12 13
A -0.092 -0.037 -0.101 0.015 0.265 0.09 -0.012 1.747 0.0 0.0 0.09 -0.037 -0.118
G 0.005 0.31 0.019 -0.044 0.151 -0.089 0.133 0.0 0.0 2.308 0.616 -0.021 0.289
T -0.126 -0.144 -0.072 -0.157 -0.149 -0.092 -0.125 0.0 1.747 0.0 -0.125 -0.139 -0.101
C 0.354 0.005 0.227 0.399 -0.021 0.169 0.354 0.0 0.0 0.0 -0.095 0.332 0.049
Также с помощью веб-сервиса Web Logo 3 было построено Logo для изучаемых последовательностей (Рис. 2).