Практикум 7
Базы данных
Я получил список генов для общего анализа по различным базам данных: Гены
Я решил использовать для общего анализа веб сервис EnrichR с которым я уже работал.
В EnrichR я использовал весь список своих генов.
EnrichR — это веб-сервис, который предоставляет инструменты для анализа функционального обогащения генов. Он помогает исследователям интерпретировать большие наборы данных, такие как списки генов, выявленные в экспериментах, например, в исследованиях экспрессии генов.
Основные функции EnrichR включают:
Анализ обогащения: Enrichr использует различные базы данных для определения, какие биологические процессы, пути или функции статистически обогащены в заданном списке генов.
Богатые библиотеки данных: Сервис включает множество библиотек с информацией о путях, биологических процессах и молекулярных функциях, таких как GO (Gene Ontology), KEGG, Reactome и другие.
Визуализация данных: Сервис предоставляет различные способы визуализации результатов, включая графики и диаграммы, что помогает в интерпретации данных.
Из всего обилия я выбрал интересующие меня базы данных, такие как KEGG 2021 Human и GO Biological Process 2023.
GO Biological Process 2023
В базе данных GO Biological Process 2023 можно найти информацию о различных биологических процессах, в которых участвуют гены и белки. Эта база данных является частью Gene Ontology и включает:
Описание процессов: Подробные описания биологических процессов, таких как клеточный цикл, метаболизм, сигнальные пути и другие.
Иерархическая структура: Процессы организованы в иерархическую структуру, от общих категорий до более специфичных.
Аннотации генов: Информация о том, какие гены и белки участвуют в каждом процессе.
Взаимосвязи между процессами: Как различные процессы связаны друг с другом и как они взаимодействуют.
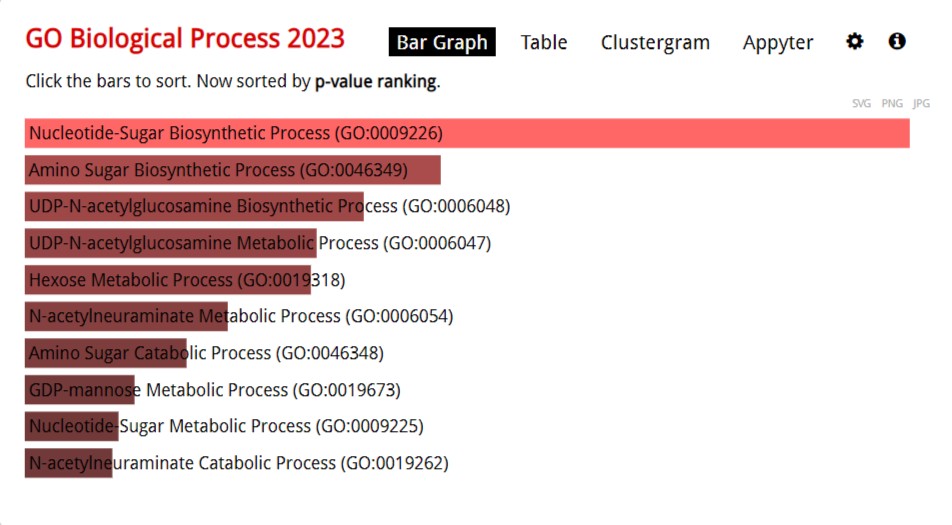
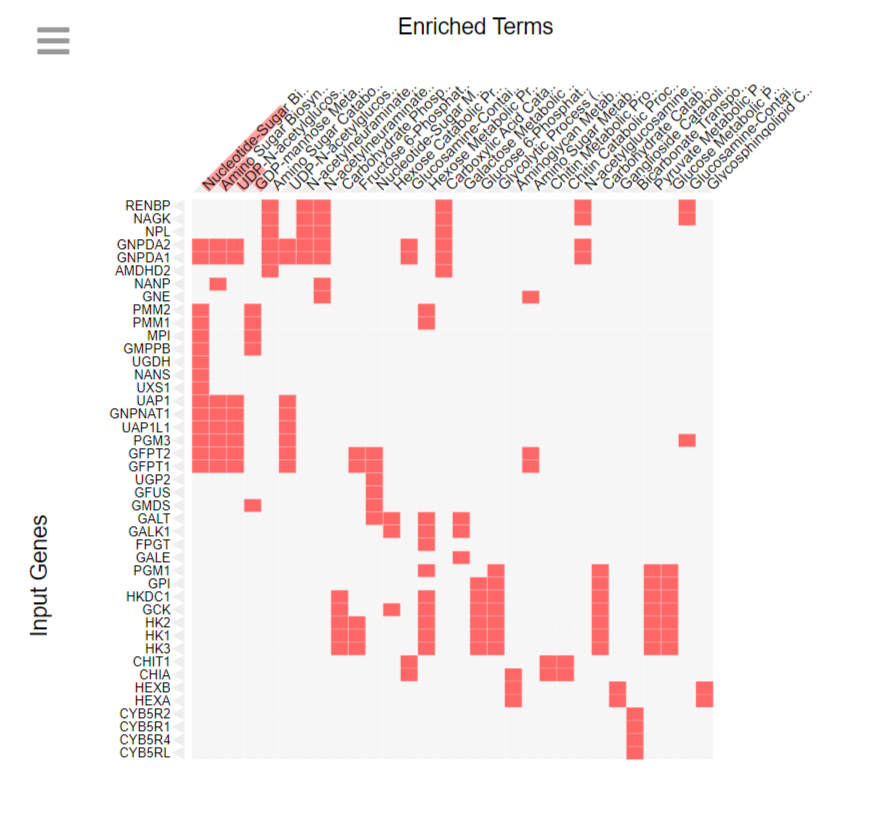
Выданные мне гены учавствуют в таких процессах как синтез нуклеотид-сахаров, синтез аминосахаров, таких как глюкозамин и галактозамин, синтез УДФ-N-ацетилглюкозамина (UDP-GlcNAc), который является ключевым промежуточным продуктом в метаболизме углеводов и тд.
Можно сделать вывод, что эти гены играют ключевую роль в метаболизме углеводов и могут быть объединены в функциональные группы, связанные с биосинтетическими путями и регуляцией клеточных процессов.
Наше предположение легко подтверждается поиском по базе данных KEGG 2021 Human
KEGG 2021 Human
База данных KEGG (Kyoto Encyclopedia of Genes and Genomes) — это интегрированная база данных, используемая для понимания биологических систем, таких как клетки, организмы и экосистемы, на основе молекулярной информации, особенно геномов. KEGG предоставляет информацию о генах, белках, метаболических путях и взаимодействиях.
KEGG Pathway:
Содержит информацию о метаболических и сигнальных путях.
Визуализирует взаимодействия между молекулами в клетке.
KEGG Genes:
Включает информацию о генах и их функциях в различных организмах.
KEGG Modules:
Представляет функциональные единицы, такие как комплексы и метаболические модули.
KEGG Orthology (KO):
Группирует гены из различных организмов на основе их функциональной аналогии.
KEGG Compound:
Содержит информацию о химических соединениях, участвующих в биологических процессах.
KEGG Reaction:
Описывает химические реакции, катализируемые ферментами.
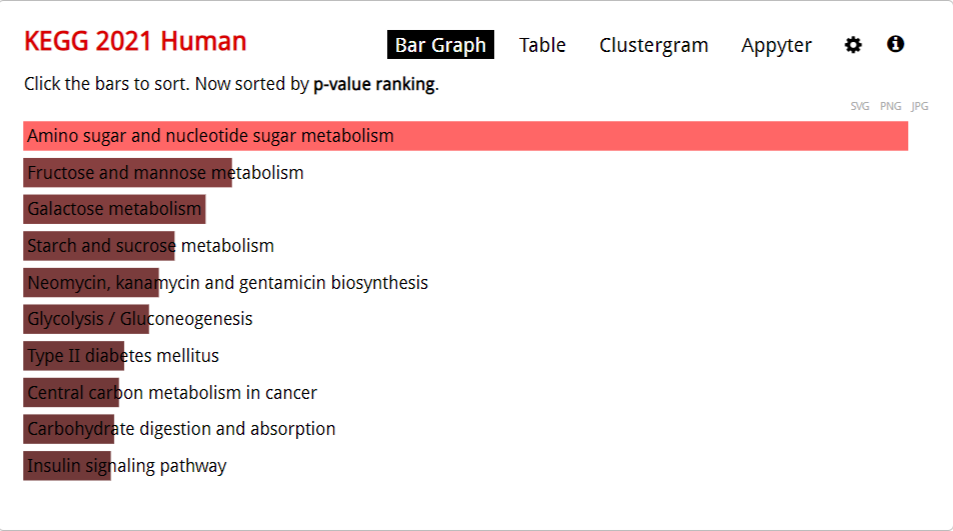
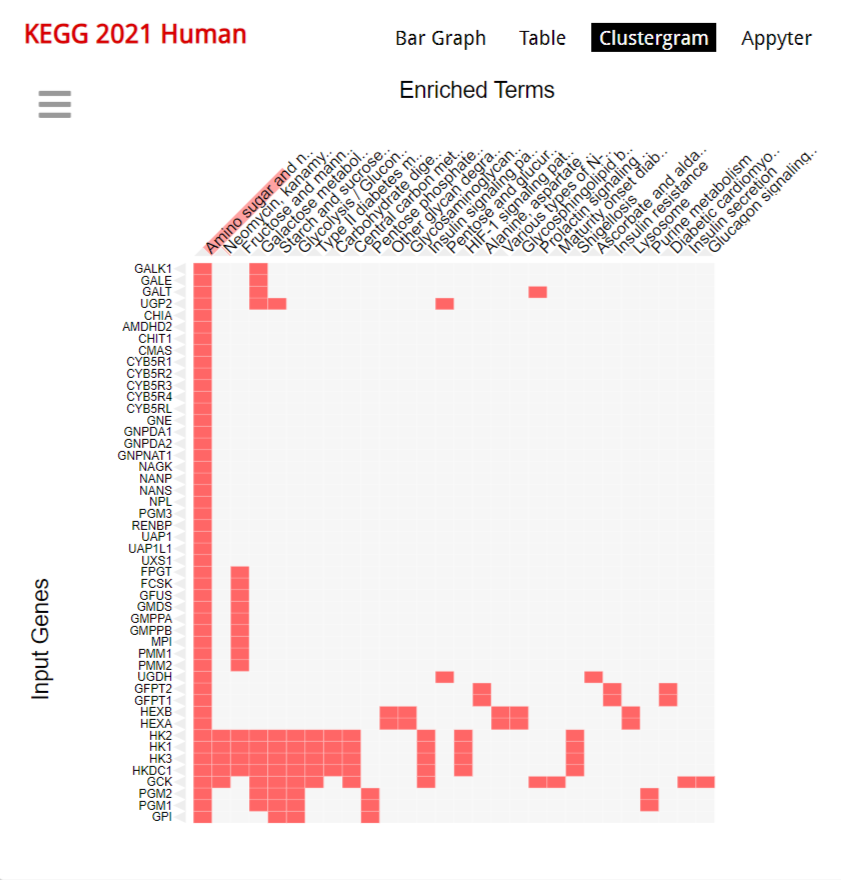
Выводы:
Ключевые процессы:
Наши гены участвуют в важных метаболических процессах, таких как синтез нуклеотид-сахаров и аминосахаров.
Они играют значительную роль в синтезе UDP-N-ацетилглюкозамина, который является важным промежуточным продуктом в метаболизме углеводов.
Функциональные группы:
Гены могут быть сгруппированы по их участию в биосинтетических путях и регуляции клеточных процессов.
Подтверждение данных:
Использование EnrichR и KEGG 2021 Human позволило подтвердить предположения о функциональной значимости этих генов.
Применение:
Результаты могут быть полезны для дальнейших исследований в области метаболизма и разработки терапевтических стратегий.