1. Описание мотива в белках паттерном
Для анализа были выбраны белки с мнемоникой ENO - Enolase. Енолаза — фермент гликолиза (предпосследний этап), катализирующий превращение 2-фосфоглицерата в фосфоенолпируват.
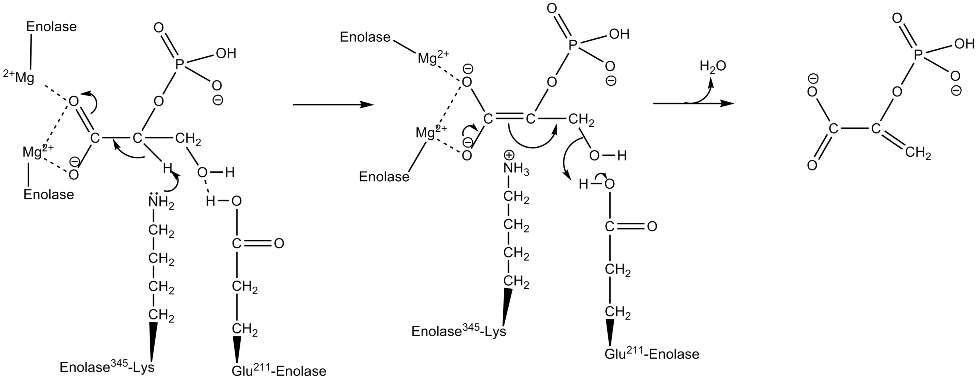
Рис. 1. Механизм преобразования 2-фосфоглицерата (2PG) в фосфоенолпируват (PEP).
По базе данных Swiss-Prot при помощи запроса (id:ENO_*) AND (taxonomy_id:2) было найдено 748 белков с мнемоникой ENO. Я выбрала 9 из них со следующими мнемониками:
- CHLAA
- NITV9
- BACSU
- ECOLI
- MYCGA
- VIBPA
- AERHY
- STRPN
- LISMO
Далее я скачала эти последовательности в формате fasta, затем выравнивание программой Muscle.
Паттерн был построен по позициям выравнивания, соответствующим 365-377 позициям последовательности ENO_ECOLI. Полученный паттерн:
T-[AT]-V-[IV]-S-H-R-S-G-E-T-E-D
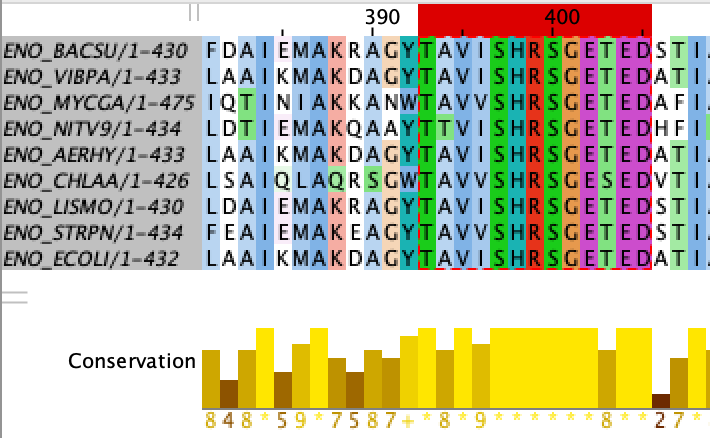
Рис. 2. Консервативный участок длиной 13 аминокислот у белков с мнемоникой ENO.
Для поиска по построенному паттерну среди бактериальных белков из Swiss-prot использовалась программа fuzzpro:
fuzzpro -sequence "/P/y24/term4/bacteria-sw.fasta" -pattern "T-[AT]-V-[IV]-S-H-R-S-G-E-[TS]-E-D" -outfile "eno_report.fuzzpro"
Программой fuzzpro по данному паттерну было найдено только 367 белков и все с мнемоникой ENO. Это означает, что наш паттерн слишком строг, попробуем его ослабить:
fuzzpro -sequence "/P/y24/term4/bacteria-sw.fasta" -pattern "T-x-V-x-S-H-R-S-G-E-x-E-D" -outfile "eno1_report.fuzzpro"
Результат - 506 находок
Попробуем сократить паттерн до "x-S-H-R-S-G-E-x-E-D"
Результат - 735 находок
Дальнейшее ослабление паттерна не приводит к лучшему результату.
2. Поиск мотивов в белках программой MEME и поиск этих мотивов в банке
Далее мотивы для этих белков искались с помощью программы MEME, заданную со следующими параметрами:
meme eno.fasta -protein -mod oops -nmotifs 3 -minw 8 -maxw 15 -oc eno_meme_out, где
'-protein' – аминокислотные последовтельности
'-mod oops' – в каждой последовательности мотив встречается один раз
'-nmotifs 3' – количество найденных мотивов в одной последовательности
'-minw 8' и '-maxw 15' – найти мотив длиной от 8 до 15 аминокислот
Каждый найденный мотив длиной 15 аминокислотных остатков (Width=15), присутствует во всех аминокислотных последовательностях (Sites=9). Первый из них использовался ранее для поиска с помощью fuzzpro.

Рис. 3. Мотивы, найденные с помощью MEME. Здесь E-value - матожидание числа находок мотивов с таким же или большим информационным содержанием в таком же числе последовательностей таких же длин.
Далее результат работы MEME был передан программе MAST для поиска белков, содержащих найденные мотивы среди последовательностей белков из Swiss-Prot:
mast 'eno_meme_out/meme.html' '/P/y24/term4/bacteria-sw.fasta' -oc eno_mast_out
В результате было найдено 778 последовательностей с Е-value меньше 10. Всего 6 находок, чье E-value > 0.001, с мнемониками ZNUC, RBFA, CLPX. Остальные 772 находки имеют хорошее значение E-value < 0.001, где, помимо мнемоники ENO, присутствуют также ENO1, ENO2, ENO3, что не является ложноположительным результатомы, так как это эукариотические изоформы енолазы.
ZNUC - белок системы транспорта цинка ZnuABC, АТФ-связывающая субъединица импортера цинка ZnuC.
RBFA - 30S ribosome-binding factor A, фактор созревания и сборки малой субъединицы бактериальной рибосомы.
CLPX - АТФ-зависимая Clp-протеаза, АТФ-связывающая субъединица ClpX, участвующая в распознавании и разворачивании белков перед их деградацией.
Таким образом, мотивы, найденные программой MEME, вероятно соответствуют функционально важным участкам энолазы, необходимым для сохранения её структуры и каталитической активности.
3. Поиск последовательности Шайна — Дальгарно в геноме Brachybacterium halotolerans subsp. Kimchi
Последовательность Шайна–Дальгарно — короткий пурин-богатый участок бактериальной мРНК, располагающийся перед старт-кодоном и участвующий в инициации трансляции. Последовательность комплементарна 3'-концу 16S рРНК малой субъединицы рибосомы. Типичная последовательность Шайна–Дальгарно: AGGAGG. По ней и проведём поиск:
fuzznuc -sequence "~/GCF_029542785.1_ASM2954278v1_genomic.fna" -pattern "A-G-G-A-G-G" -complement -outfile "sd.fuzznuc"
'-complement' - для поиска и по прямой, и по комплементарной цепи.
Из него видно, что в 9 последовательностях программа смогла найти 7705 совпадений с паттерном последовательности Шайна-Дальгарно.
С помощью программы compseq посчитали частоты нуклеотидов:
compseq -sequence ~/GCF_029542785.1_ASM2954278v1_genomic.fna -word 1 -outfile nucleotide.txt
По результату выдачи P(A) = 0.1883687; P(C) = 0.3119888; P(G) = 0.3109129; P(T) = 0.1887295. Согласно этим частотам, вероятность получить последовательность AGGAGG, если это случайные независимо распределённые буквы: P(AGGAGG) = P(A)^2 * P(G)^4 = (0.1883687)^2 * (0.3109129)^4 = 0,00033157 = 3,3157 * 10^-4. А количество находок в геноме тогда: P(AGGAGG) * длина генома = 3,3157 * 10^-4 * 8433779 = 2796. Это в 2.7 раз меньше, чем реальное число находок.
Было проанализировано 20 случайно выбранных сайтов, содержащих последовательность AGGAGG. Лишь только 4 сайта (20%) располагались в правильной позиции относительно старт-кодона CDS — на расстоянии 5–15 нуклеотидов перед началом гена и на той же цепи. Остальные находоки находятся в позициях, не соответствующих функциональной ПШД (внутри генов, на противоположной цепи или слишком далеко/близко от старт-кодона). Несмотря на большое число найденных мотивов AGGAGG в геноме, только часть из них соответствует функциональным последовательностям Шайна–Дальгарно. Для остальных генов могут использоваться более вариабельные варианты ПШД (GGAG, GGAGG, GAGG) либо альтернативные механизмы инициации трансляции.