Для этого практикума было выбрано семейство PF00808 (CBFD_NFYB_HMF) - гистоноподобные факторы транскрипции и гистоны архей, в нем взято подсемейство из 338 белков с одинаковой доменной архитектурой - два домена PF00808. Для всего семейства выравнивание seed содержит 25 белков, а full - 21808. Я взял 335 белков для выравнивания доменов из подсемейства и построения профиля HMM программой hmmbuild, а также 29402 белка для поиска по ним полученным профилем программой hmmsearch.
Для получения последовательностей доменов в белках подсемейства и обработки таблицы находок hmmsearch был использован скрипт Python. 2 белка с похожей доменной структурой из другого подсемейства были удалены из выравнивания вручную.
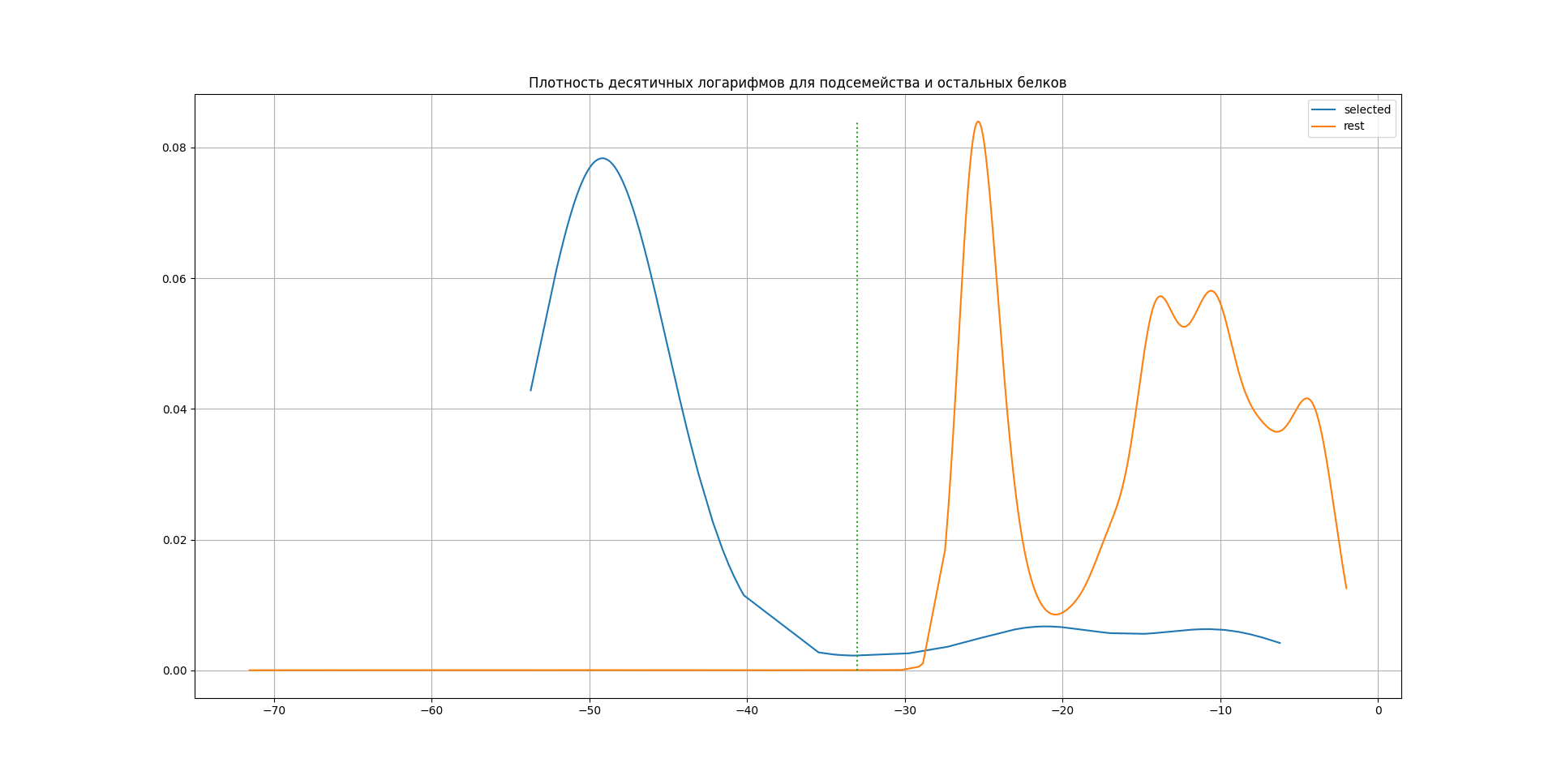
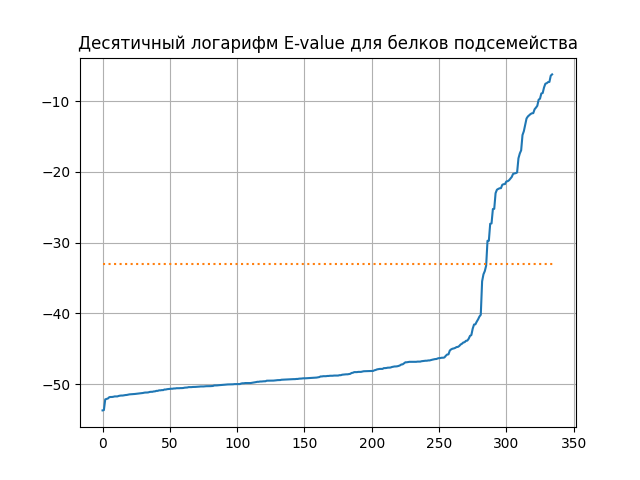
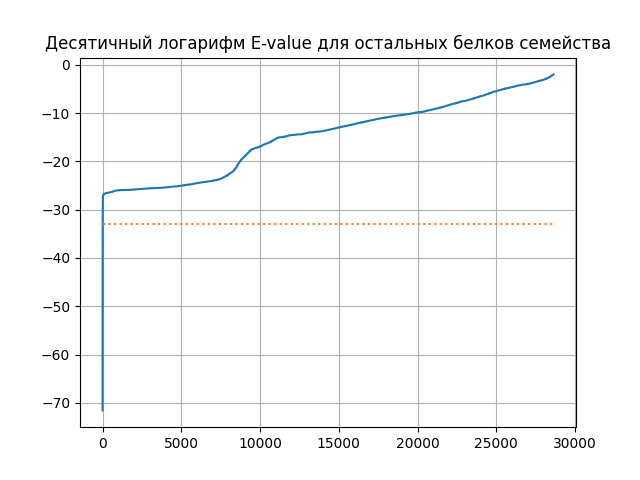
На мой взгляд, оптимальный порог E-value для выделения выбранного мной подсемейства - 1е-33: он отсекает 85% последовательностей подсемейства и 0.03% остальных последовательностей. Как видно из графиков (см. ниже), ниже этого порога располагаются почти исключительно выбранные последовательности, а выше него начинаются остальные. Тест Фишера для таблицы численных характеристик выделения подсемейства профилем дает p-value 7.193e-09, с учетом поправки Бонферрони - 2.115е-04; таким образом, можно принять гипотезу о том, что представленность выбранного подсемейства до порога статистически значимо отличается от его представленности после порога.
| True | False | |
| Positives | 286 | 9 |
| Negatives | 28615 | 49 |
Численные характеристики выделения подсемейства профилем.