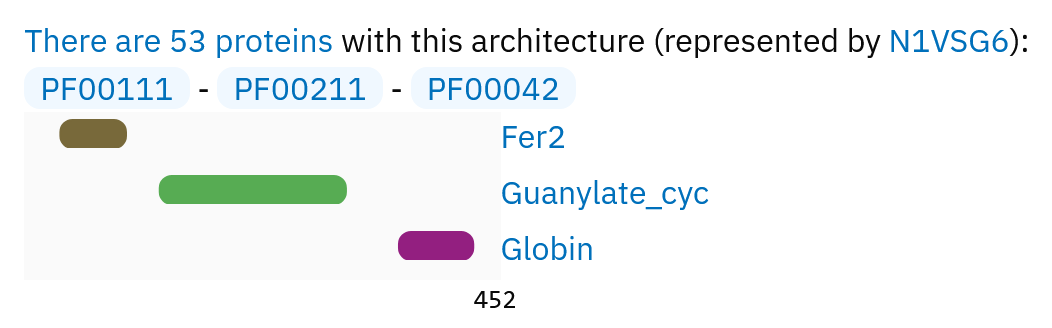
Для выполнения практикума я выбрала семейство: PF00042 (ID: Globin), полное имя -- Globin. Глобины представляют собой гемосодержащие белки, участвующие в связывании и/или транспортировке малых молекул газов, в частности, кислорода. В выравнивании seed 73 последовательностей, в выравнивании full -- 20705 последовательностей.
В данном семействе было выделено подсемейство с доменной архитектурой: PF00111 - PF00211 - PF00042 (рис. 1). В нём 53 белка, репрезентативный -- N1VSG6
После этого я скачала последовательности белков подсемейства, выровняла их программой muscle, отсортировала по сходству и выделила нужный домен PF00042 (координаты: 369-445).
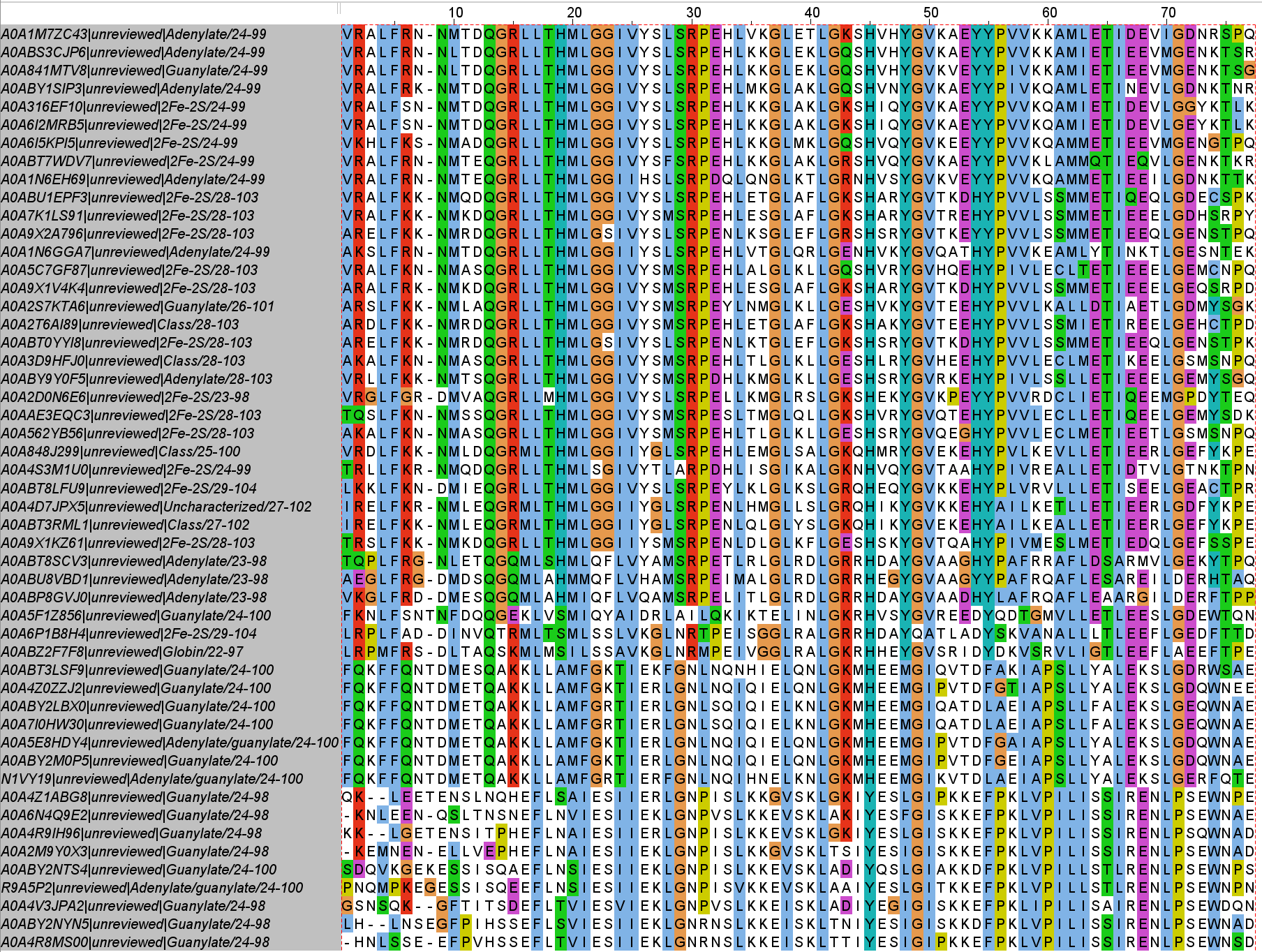
Чтобы построить hmm-профиль по выбранному домену, была запущена программа hmmbuild из пакета HMMER:
hmmbuild profile.hmm aligment_part.faСамо семейство глобинов достаточно большое (42 тысячи), но белки моего подсемейства содержатся преимущественно в бактериях. Поэтому, чтобы выделить подсемейство на фоне остальных глобинов, я выбрала таксон Pseudomonadati. Поиск проводился программой hmmsearch из пакета HMMER. Команда, которой проводился поиск:
hmmsearch --tblout hmmsearch_b1.txt profile.hmm bacteria.fastaВсего было найдено 7383 (из 7598) белков. Все 53 белка из подсемейства тоже нашлись, вес для них варьировался от 118.1 до 78.9. Искать порог я буду по столбцу "вес для одного лучшего домена". В процессе подбора score, я построила график распределения весов находок (рис. 3)
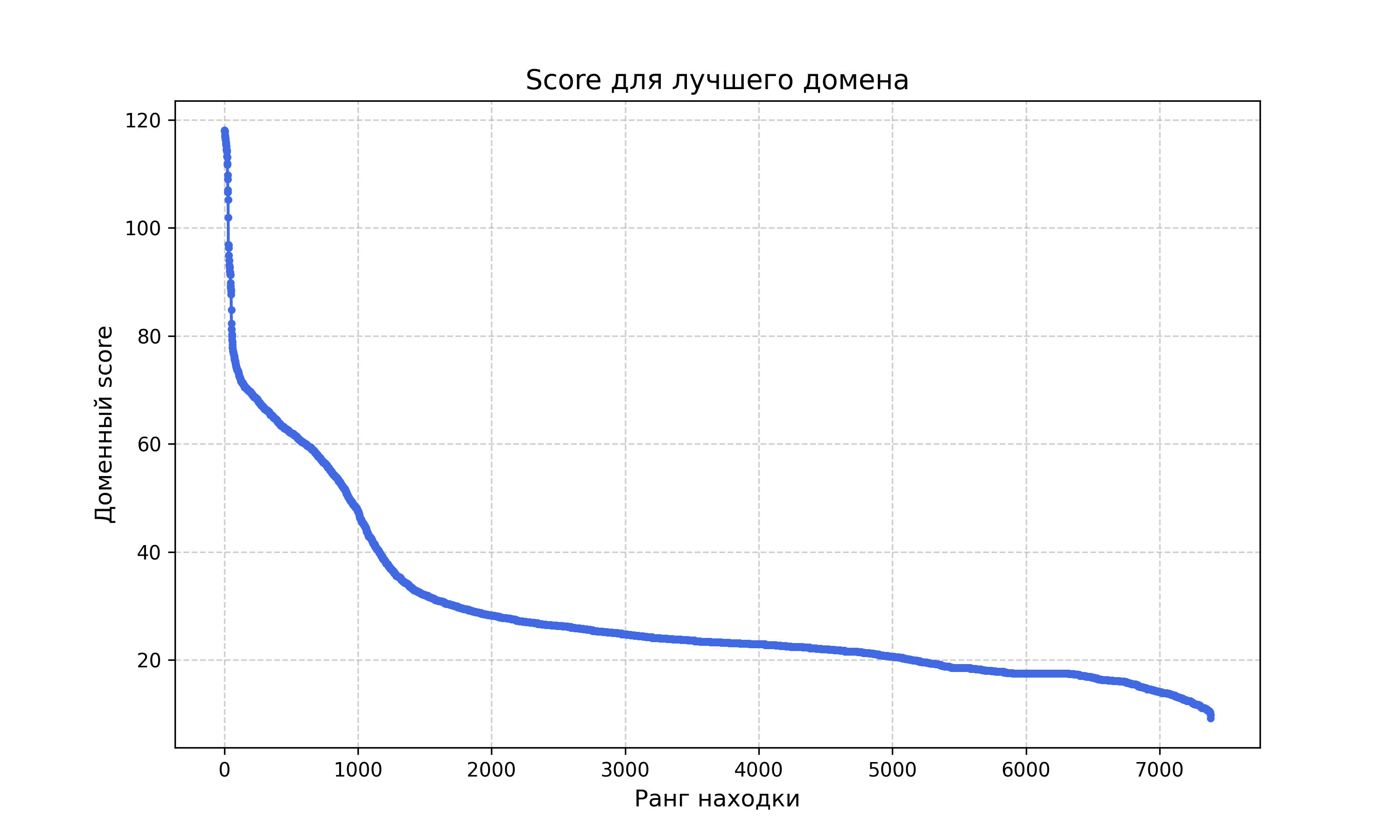
На графике (рис. 3) видно, что снижение веса у находок происходит неравномерно, есть участки, где вес падает очень быстро. Если смотреть на самый большой разрыв между score для находок и использовать его как порог, то почти половина белков из моего подсемейства имеют score ниже этого порога. При подборе оптимального score, было обнаружено, что при весе 83 ложноотрицательных результата всего два, ложноположительных тоже два. При понижении порога число ложноположительных результатов быстро увеличивается, а белки из моего подсемейства всё равно не ищутся. Поэтому я остановилась на пороге 83. Делала всё с помощью скрипта.
Итог -- порог равен 83.
Таблица 1. Результаты выделения подсемейства профилем по порогу 83.
| True | False | |
| Positives | 51 | 2 |
| Negatives | 7328 | 2 |