Поиск домена и доменной архитектуры
В рамках этого практикума я буду работать с доменом Carbohydrate binding module 77 (ID: CBM77, AC: PF18283).Этот домен представляет собой некаталитический углеводсвязывающий модуль 77 (CBM77), присутствующий в Ruminococcus flavefaciens. CBM выполняют критическую функцию нацеливания при деполимеризации клеточной стенки растений. В CBM77 кластер консервативных основных остатков (Lys1092, Lys1107 и Lys1162) обеспечивает независимое от кальция распознавание гомогалактуронана. Я использовал Google Таблицы для поиска домена.
Основные характеристики выбранного домена представлены ниже.
- Число белков в выравнивании seed:
13 - Число белков в выравнивании full:
96 - Число белков в выравнивании UniProt:
412 - Длина HMM профиля из базы данных Pfam:
109 позиций - Средняя длина домена
108.1 - Среднее сходство
42% - Средний процент покрытия последовталеьности белка доменом (coverage)
11.82% - Число доменных архитектур
22
Далее были найдены доменные архитектуры, соответвующие критериям: есть еще домен, помимо CBM77 и встречается более, чем у 20 белков, но менее чем у половины белков с выбранным доменом. Таких две: первая с Pectate_lyase_4 (41 последовталеьность) , вторая с Pectate_lyase_4 и Por_Secre_tail (25 последовталеьностей). Для дальнейше работы выбрали первую архитектуру, AC:PF00544 (Рис 1).

Были скачаны все последовательности выбранного семейства, выделены их AC и убраны 3 пары дубликатов. Были скопированы все AC белков, соответствующих выбраной архитектуре. Затем были скачаны белковые послдовательности, соответвующие этим AC. Эти последовательности были выравнены в Jalview алгоритмом Muscle. В выравнивании были найдены и вырезаны участки с доменами. Также были убраны последовательности, которые плохо выравнялись и имели высокую (почти 100 %) схожесть.
Был построен HMM профиль выбранной двухдоменной архитектуры и был нормирован вес:
$ hmm2build hmm_profile sorted_domains.fasta
$ hmm2calibrate hmm_profile
Затем был проведен поиск профиля по последовательностям из всего семейства.
hmm2search -E 0.1 --cpu=2 hmm_profile domain_all.fasta > hmm_search.txt
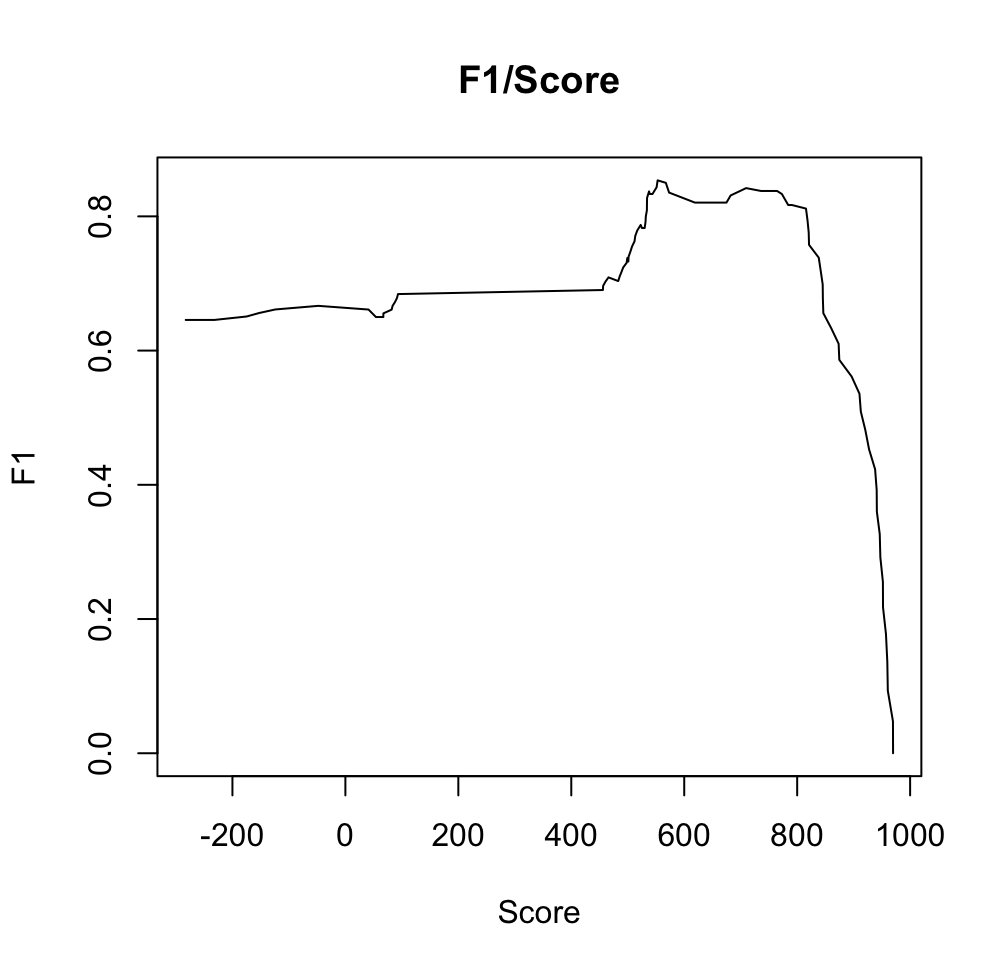
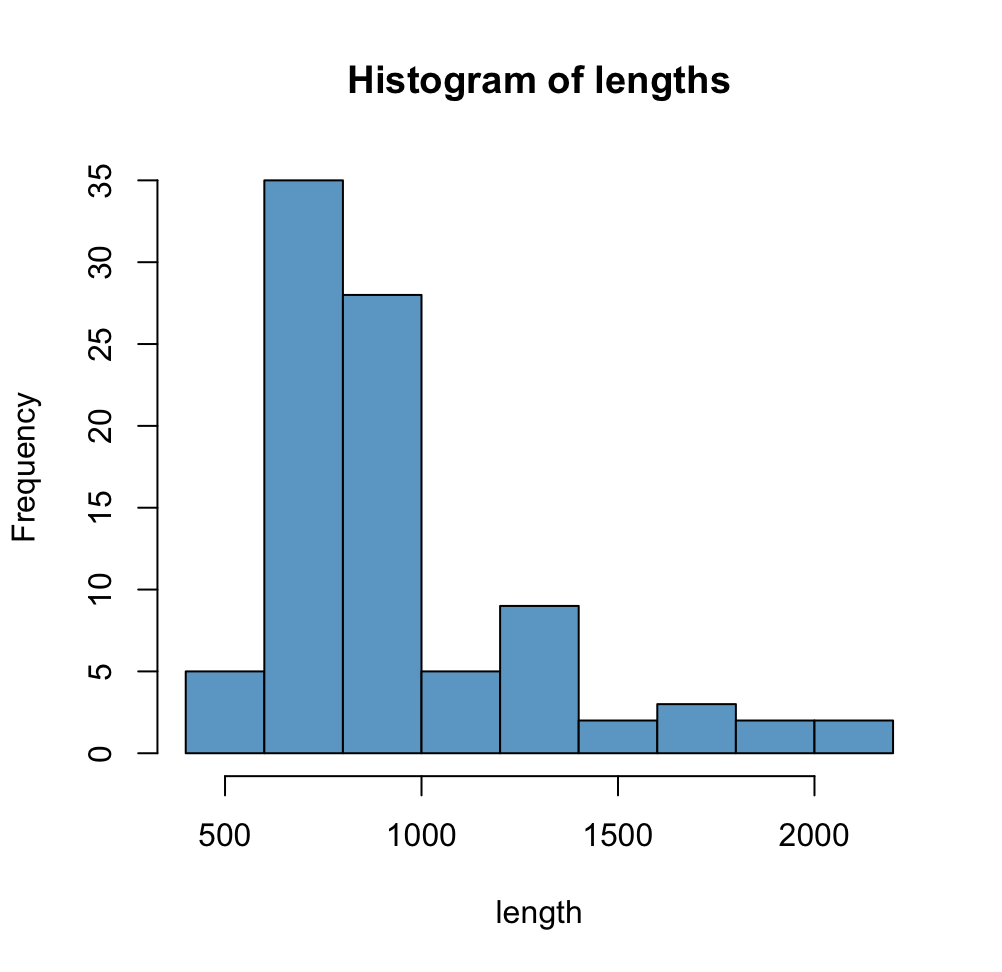
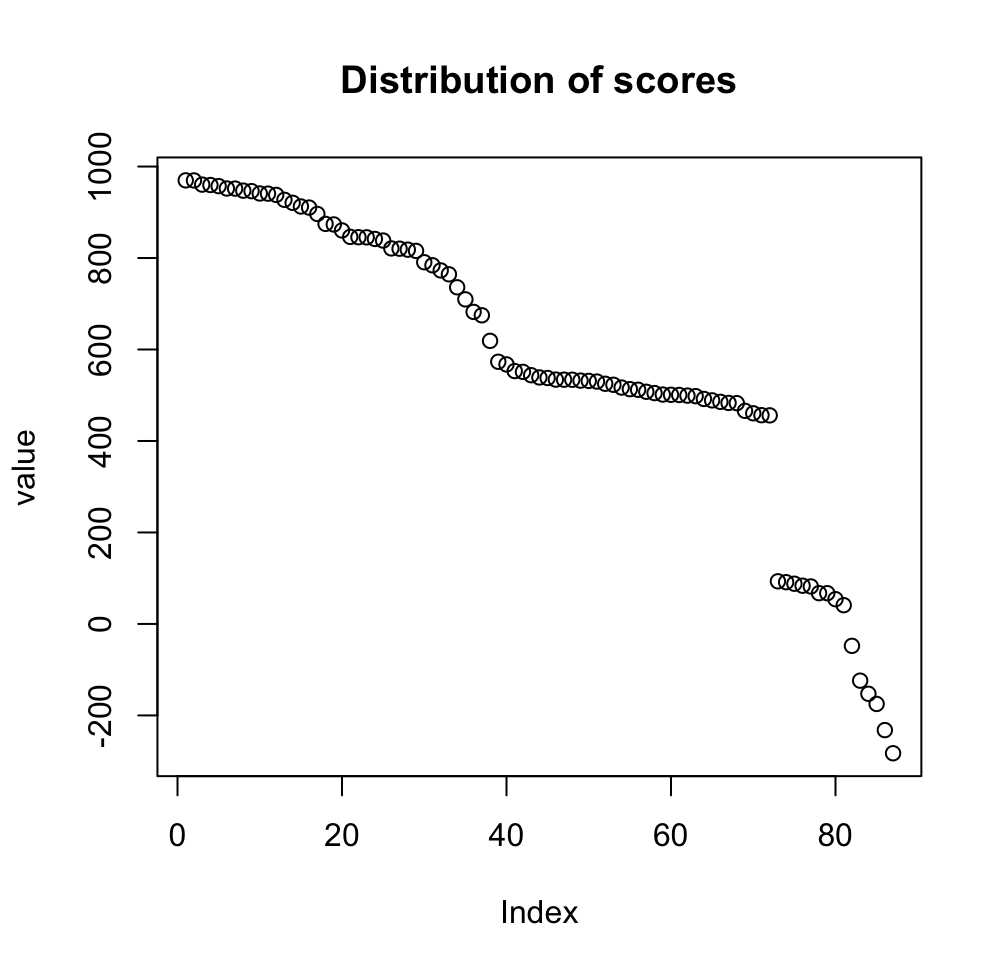
Из файла полученного hmm2search была создана таблица. Была построена гистограмма длин белков семейства (Рис 2), для белков из нашего домена характерна длина в диапазоне 733-1003.Также было построено распределение весов находок, где из интересного мы наблюдаем после 450 резкий спад до 90 (Рис 3).
Был построен график зависимости F1. При миниальных значениях чувствительности линия плавная, затем растёт, достигает пика и убывает.