Предсказание генов прокариот
Информация о плазмиде
Моей задачей было предсказать гены в плазмиде CP015437. Она пренадлежит бактерии Anoxybacillus sp. B7M1 со следующем положением в систематике: Bacteria, Firmicutes, Bacilli, Bacillales, Bacillaceae, Anoxybacillus. Бактерии данного рода являются палочковидными и спорообразующими. Они встречаются в геотермальных источниках, навозе и на заводах по переработке молока.
Плазмида состоит из 54,976 пн и содержит 78 белок-кодирующих генов.
Сравнение предсказаний генов в базе данных GenBank и по данным Prodigal для плазмиды
Для начала я с помощью программы seqret пакета EMBOSS получила файл plasmid.fasta с последовательностью исследуемой плазмиды.
seqret embl:CP015437 plasmid.fasta
Затем я создала файл с особенностями plasmid.gff, в котором указаны предполагаемые гены.
seqret embl:CP015437 -feature plasmid.gff
Далее я запустила программу Prodigal с параметрами -i (указывает специфичный входной файл формата FASTA), -o (указывает специфичный выходной файл; по умолцанию stdout) и -f (выбор формата вывода: gbk, gff или sco; по умолчанию gbk). По совету я выбрала самый минималистичный формат sco, так как он удобен для дальнейшей работы.

Я получила файл plasmid.pro на выходе.
Для сравнения данных о предполагаемых генах я перевела файлы plasmid.gff и plasmid.pro к более удобному виду. Я воспользовалась программой gff.py, которая перевела файл plasmid.gff в gff.txt при вводе в командной строке:
python gff.py plasmid.gff gff.txt
Затем я воспользовалась программой pro.py, которая перевела файл plasmid.pro в pro.txt при вводе в командной строке:
python pro.py plasmid.pro pro.txt
Последним шагом было написание программы comparison.py, сравнивающей файлы gff.txt и pro.txt. Ниже представлен результат её работы.

Программа раборает по следующему алгоритму:
На вход она принимает два файла. Первым указывается файл gff.txt, с которым сравнивается полученный с помощью Prodigal файл pro.txt. Сначала строчки файлов переводятся в соответствующие массивы (gff_cds и pro_cds). Размер массива gff_cds (переменная all) будет равен числу генов в плазмиде. Далее он будет использоваться для подсчёта процентов. Затем я ввела и обнулила счётчики nc, n и c для посчёта числа полных совпадений, совпадений по N-концу и совпадений по C-концу соответственно. Следующим шагом я прохожу алгоритмом по каждой строчке из файла gff.txt (по каждому элементу из массива gff_cds) и разбиваю каждую строчку на отдельные "слова". Для конкретной строчки из gff_cds, если третье "слово" является символом "+", что обозначает положение гена на прямой цепи, то первое "слово" указывает на координаты начала рамки считывания (N-конец), а второе "слово" указывает на координаты её конца (С-конец). Если же запись относится к обратной цепи, то первое "слово" укажет С-конец, а второе "слово" - N-конец. Таким образом, я в переменные gff_n и gff_c записываю координаты начала и конца рамки считывания соответственно. Так, имея данные о конкретной строчке из файла gff.txt, я начинаю просматривать все строчки из файла pro.txt и аналогично записываю в переменные pro_n и pro_c координаты начала и конца рамки считывания с учётом направленности гена в цепи. Далее, если в файле pro.txt найдётся такая строчка, для которой хотя бы один из концов совпадёт с таковым в фиксированной строчке из файла gff.txt, то в случае совпадения обоих координат, прибавляется 1 к счётчику nc, иначе прибавляется 1 к счётчику n или c в зависимости от того, какие именно концы совпали. По завершении обоих циклов я имею:
- Число полных совпадений (nc)
- Число совпадений только по C-концу или число несовпадений по N-концу (c)
- Число совпадений только по N-концу или число несовпадений по C-концу (n)
- Число ошибочно предсказанных генов или число несовпадений по обоим концам (all - nc - c - n)
Для удобства я оформила результаты сравнения в таблице 1.
| Таблица 1. Результаты сравнения предсказаний генов в базе данных GenBank и по данным Prodigal для плазмиды CP015437 | ||||
| Полностью совпавшие гены | Ошибка только по N-концу | Ошибка только по С-концу | Ошибочно предсказанные гены | |
| Число | 76 | 1 | 0 | 1 |
| Процент | 97.4% | 1.3% | 0.0% | 1.3% |
Анализ несовпадений
Программа Prodigal сработала достаточно хорошо. Так что я имею всего 2 несовпадения. Рассмотрим сперва несовпадение только по N-концу. В файле gff.txt указано "28468 29013 +", а предсказано программой "28495 29013 +".
Последовательность ДНК с 28468 по 29013:
atgaaagacaggaaaaggggtattgaaatgaggaagtttatatcaacagctaatcggggc atgggcctcgaaaattacattaacgccgcaaacacggcgtataaattaaaaaaaattgca ttgattgacaaaaaacctgttcctatcaagtttagaactgataagaggacagggcgtatt aaggaagcttggtttgaaaaacaaagtacggttgactactacggcattgtaaacggcgtc cccgtcgcttttgagtgcaaaagcacacgagaagagactagattcccgctcaacaacatt gaggagcatcaatacgagtatttgagggagtttcatttgcaaaaaggtgtcagcttcttg cttgttgaattcgccgcacatcaagagatatacatactaaagtttgagcaactgcaacaa tggtggttcgaatcacgccgtggtggccgcaagagcattccttataaatggttccaggaa aattgtaagaagtgtggtcctggacgcggtctttctgttgactatctagcggcggcggga ttatga
Предполагаемый кодируемый белок:
MKDRKRGIEMRKFISTANRGMGLENYINAANTAYKLKKIALIDKKPVPIKFRTDKRTGRI KEAWFEKQSTVDYYGIVNGVPVAFECKSTREETRFPLNNIEEHQYEYLREFHLQKGVSFL LVEFAAHQEIYILKFEQLQQWWFESRRGGRKSIPYKWFQENCKKCGPGRGLSVDYLAAAG L
Последовательность ДНК с 28495 по 29013:
atgaggaagtttatatcaacagctaatcggggc atgggcctcgaaaattacattaacgccgcaaacacggcgtataaattaaaaaaaattgca ttgattgacaaaaaacctgttcctatcaagtttagaactgataagaggacagggcgtatt aaggaagcttggtttgaaaaacaaagtacggttgactactacggcattgtaaacggcgtc cccgtcgcttttgagtgcaaaagcacacgagaagagactagattcccgctcaacaacatt gaggagcatcaatacgagtatttgagggagtttcatttgcaaaaaggtgtcagcttcttg cttgttgaattcgccgcacatcaagagatatacatactaaagtttgagcaactgcaacaa tggtggttcgaatcacgccgtggtggccgcaagagcattccttataaatggttccaggaa aattgtaagaagtgtggtcctggacgcggtctttctgttgactatctagcggcggcggga ttatga
Предполагаемый кодируемый белок:
MRKFISTANRGMGLENYINAANTAYKLKKIALIDKKPVPIKFRTDKRTGRI KEAWFEKQSTVDYYGIVNGVPVAFECKSTREETRFPLNNIEEHQYEYLREFHLQKGVSFL LVEFAAHQEIYILKFEQLQQWWFESRRGGRKSIPYKWFQENCKKCGPGRGLSVDYLAAAG L
Мне кажется странным, что программа предложила ген, кодирующий на 9 аминокислот меньше, чем на самом деле. Возможно, это объясняется частотой кодонов. По аннотации последовательность гена принадлежит рекомбинантному белку из U семьи. Интересно, что запустив в BLASTP по очереди оба варианта белковой последовательности, мы в обоих случаях получим схожие находки, большинство которых относится к белку Holliday junction resolvase RecU. Окружение данного гена с N-конца весьма свободно:
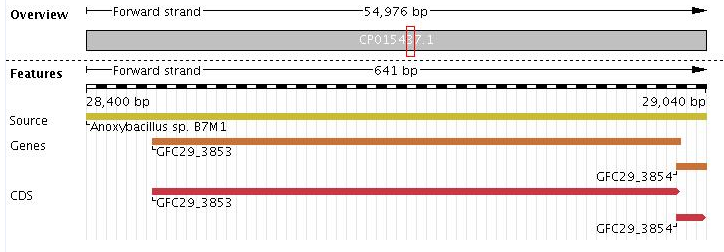
Что же касается полного несовпадения, то для него в файле gff.txt указано "54398 54709 -", а предсказано программой "53903 54976 +". Ниже представлено окружение гена в промежутке 53903 - 54976.
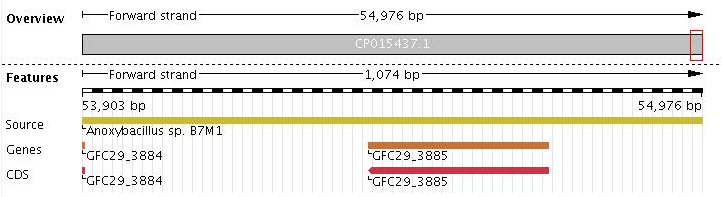
Если бы предложенный программой ген существовал, то он бы перекрывался с предыдущим геном "53214 53906 +" на 4 нуклеотида, что в принципе возможно у прокариот, но не желательно. Последовательность такого гена "53903 54976 +":
atgagaaatatttcaccgacgttgctacagtccatttcgagccagttccagctagcggct gatgatcgggaaccgaatcaatatgttttagtgcgaaatcgtttttatggccgttcggat gatccaggactgatggatgtagaatgggcgcggcttcctaatgtcatcagcattgaaatt gatgaaacggtcgaaacaccggctaaatcgttcacaattgtggtggctaacaacgatggt cgtttttcaccggactattatgcgggaaaatggccgcaacgatatctatttggcgatgaa gtaccggagagcccctgggcgcgacaactattcccgaataccgaaattgcgattcatctc ggatacggtgaggaagtcatcccttatttgcggggactcattgatgaggtgaccatcaac tccgacgcgcaaacgctaacgattactgggcgttctatgtataaaaaagtattgacgacg acaatcaagcctccatcaaacaagcagtactttctgaacgataaaactatgaacataggc gaggcggtaaaaaaattggtcgaaggagcgggcgtgccatgcaccgctccttttattacg gttccaggcagtaacccgccagaatcgtatgagcttggtgtggctaggggcgaaaggttt cagacgtttgacgatgcagttcgcgatattgtagattcgttgttttttacgatggttgaa gatgcacaggggaaggttactctcaagtcgattcctcggtattcccaagcggatgaccca aaggtggtagtcgacgactttctccatctgaaagaactcgagtacaccatgagtgacaat gacctatatgggaccatcatcattaaatccgggaaaaaggcggatattttccatagcggt tttatcaccaatcaaattttgcgcgggcagagaagagaggcagaatacgaagtcccttgg gcgaacacgtcatttaagcggaaattagcggcgcaagcctatttcacgcaaatgttacac cgctggagaaaactatcgattgctatccccgctaacccagcgattgaattatgg
Если сделать поиск по выше написанной последовательности ДНК в TBLASTX, то программа не выдаст достоверные находки.
Запустим BLASTP с последовательностью белка из аннотации гена "53214 53906 +":
MEKVVDYHLWVIRLGIPRNRLESNLPLCIFNHRKKQRIYNIANCIVKRLKPFAPSHTKLI RFWRVTAWNRNKRSGAWHARSFDQFFYRLAYVHSFIVQKVLLV
В качестве единственной находки мы получим гипотетический белок GFC29_3885 из исследуемой нами плазмиды.
Таким образом, в обоих случаях несовпадения сложно однозначно определить рамку считывания. Тем не менее важные, известные, консервативные гены определяются весьма точно программой Prodigal.