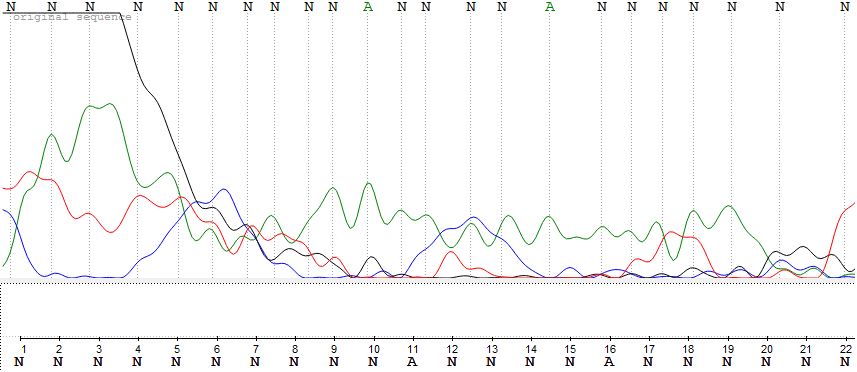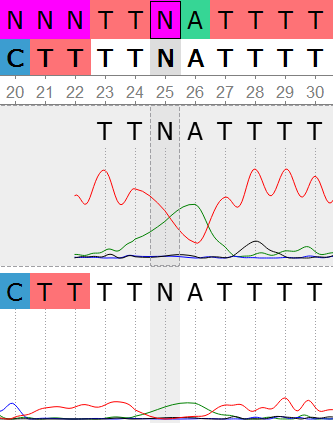
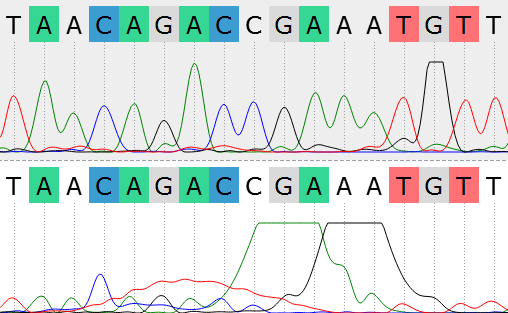
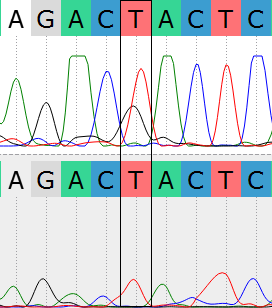
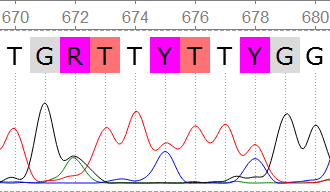
В начале были даны 2 файла с хроматограммами 23_F.ab1 и 23_R.ab1 прямой и обратной цепочками ДНК. Анализ хроматограмм был проведен в программе UGENE. При первом рассмотре хроматограмм были примерно определены концевые нечитаемые участки последовательностей. Для F последовательности с 1 по 20 и с 709 по 714, для R - с 1 по 34 и с 711 по 724. В итоге, после выравнивания в консенсус не вошли нуклеотиды с 1 по 22 и с 707 по 714 в прямой последовательности и с 1 по 37 и с 713 по 724 в обратной последовательности. Уровень шума, как и ожидалось, был наиболее высок вначале и в конце хроматограмм. В середине же последовательностей уровень шума в среднем был минимален. Была получена последовательность консенсуса и выравнивание, экспортированное из UGENE (+ выравнивание прямой и обратной консенсусной последовательности). В результате работы также были обнаружены проблемные нуклеотиды (слева направо 1-4):
Снизу представлен нечитаемый фрагмент из начала (3'-конца) хроматограммы первоначальной R последовательности. В нем видно сильное перекрывание аденином остальных нуклеотидов, однако также есть и несколько пиков, соизмеримых друг с другом, что так же мешает определить последовательность ДНК.