Для упрощения своей работы я написал скрипт, который можно посмотреть по ссылке - файл. Данный скрипт скачивает архив, отбирает адаптеры и запускает триммирование и программу velveth.
После работы программы были отсеяны сначала 41858 (0.51%) чтений и осталось 8212774 (99.49%), а потом еще отсеялось 297300 (3.62%) чтений и остались 7915474 (96.38%) чтений.
Значение N50 составляет 43070. Ниже представлены все log-файлы, из которых взята информация:
Ниже можно видеть информацию по контигам, которые использовались для анализа программой megablast.
| ID | длина | покрытие | fasta |
| 1 | 113474 | 33.52 | contig1 |
| 2 | 41715 | 36.31 | contig2 |
| 3 | 11607 | 31.55 | contig3 |
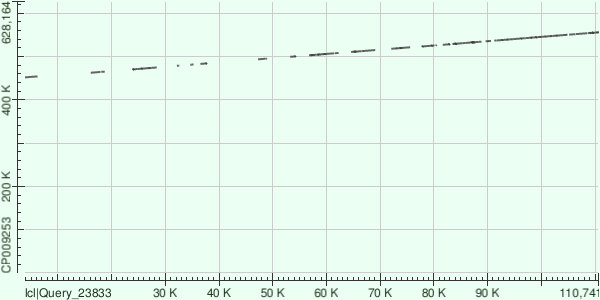
Как видно с графика, данный контиг расположен примерно с 450К и до 550К. Сама последовательность консервативная, но наблюдаются участки, в которых не получилось выровнять, скорее всего, это не является никакой делецией, а попросту ошибка при сборке.
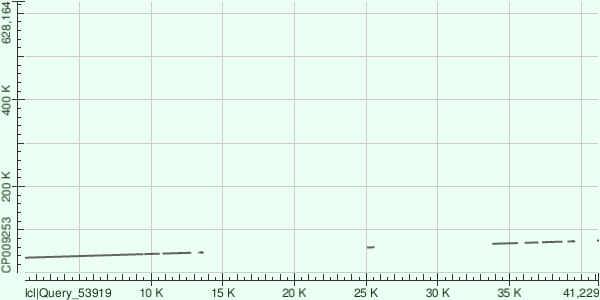
Данный контиг расположен примерно с 40К и до 80К. Остальное же аналогично прошлому контигу: шум отсутствует, последовательность достаточно консервативна, но опять есть пустые области.
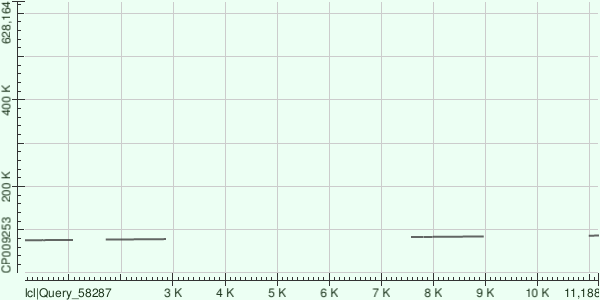
Последний контиг находится с 80К и до 90К. Прочее остается аналогичным прошлому, за исключением того, что "разрывы" становятся все больше.
В завершении хотелось бы сказать, что данные пустые области растут с уменьшением длины контигов, что прекрасно видно из графиков (длины контигов соответственно 110К, 40К и 10К). Это объясняется парой пунктов: для начала стоит вспомнить, что мы отсеивали часть чтений, что могло повлиять на эти контиги, а также из-за того, что мы по сути просто выкидывали некоторые чтения, итоговая сборка могла пройти с небольшими ошибками.