В качестве исходных данных для этого задания я выбрал 8 белков из семейства, найденного на прошлом практикуме. Fasta-файл с последовательностями этих белков можно посмотреть тут.
Для построения множественного выравнивания я использовал 2 алгоритма, доступных на сервере факультета. Команда для запуска программы, реализующей muscle (исходный файл с последовательностями называется seq.fasta):
muscle –in seq.fasta –out al_muscle.fasta
Другой алгоритм – mafft – вызывается такой командой:
mafft seq.fasta > al_mafft.fasta
Полученные выравнивания можно посмотреть в проекте JalView в окошках al_muscle и al_mafft соответсвенно.
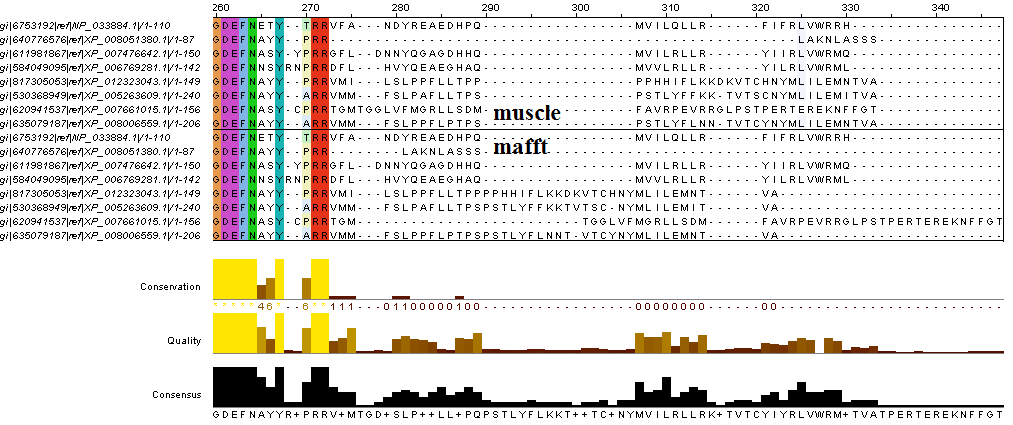
Для сравнения этих выравниваний можно вновь воспользоваться muscle – построить выравнивание выравниваний. Результат можно также увидеть в проекте JalView в третьем окне (combined). Видно, что выравнивания не идентичны только на C-конце белков, где располагаются неконсервативные участки. С-концевые участки приведены на рисунке 1.
Рисунок 1. Фрагмент сравнения двух выравниваний, полученных разными алгоритмами
Так как участки явно негомологичны, с биологической точки зрения не имеет значения, как на них расставлены гепы. По-видимому, веса таких выравниваний также одинаковы. В консервативных участках различий в работе алгоритмов нет, что может быть доказательством качества обоих выравниваний.
База данных Pfam содержит информацию о беловых семействах, часто встречающихся доменах и их сочетаниях. Для поиска я использовал один из белков этого практикума (bcl-2-like protein 11, Mus musculus). Этот белок содержит 2 домена, описанного в Pfam: семейство Bim_N (идентификатор PF06773) и Bclx_interact (идентификатор PF08945).
В Pfam можно найти все доступные последовательности, содержащие исследуемый домен и скачать выравнивание этих доменов. Для второго семейства выравнивание наиболее сходных доменов можно скачать тут.
Последнее обновление: 29.02.2016