Сборка генома Buchnera aphidicola
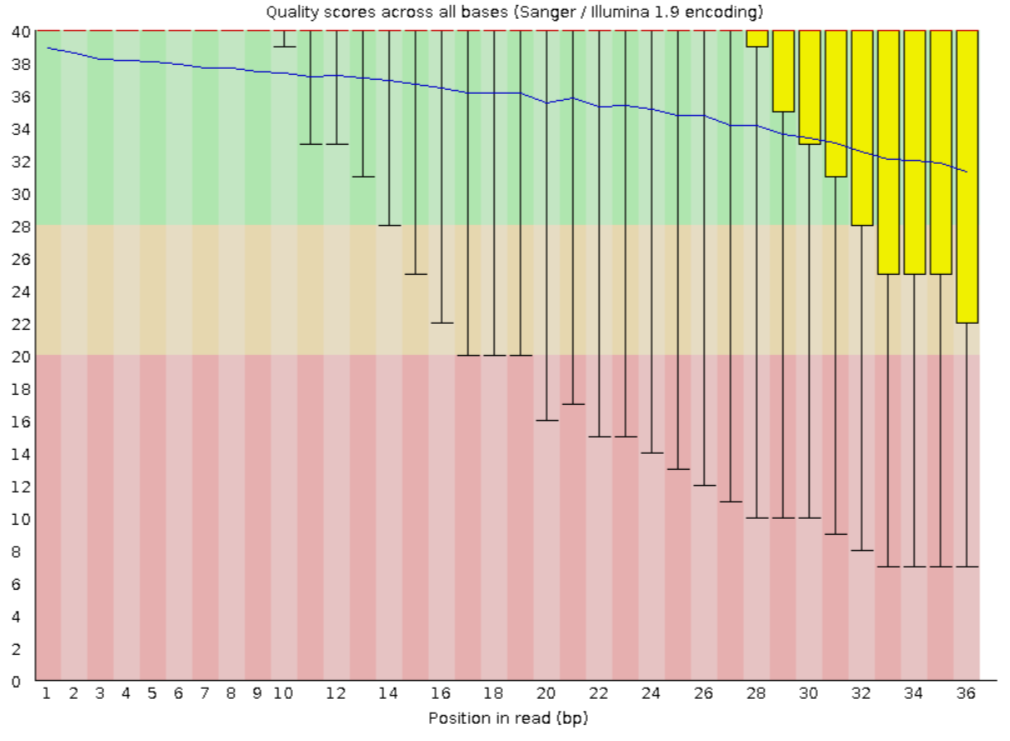
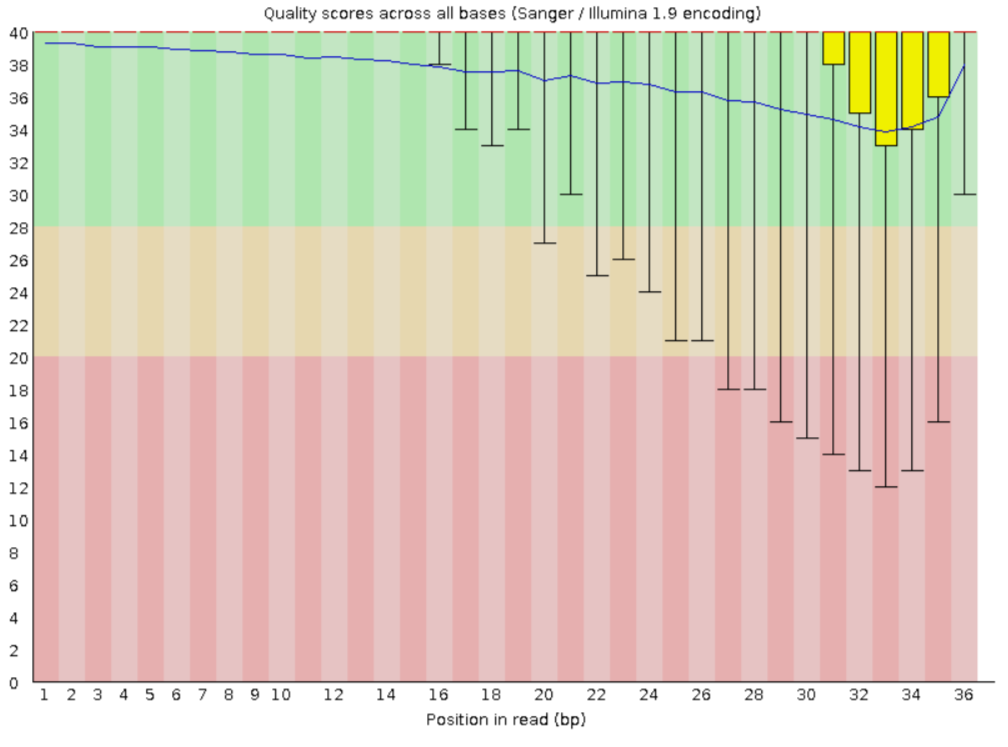
Во-первых, чтения с ID SRR4240361 были скачаны на кодомо. Эти чтения были обработаны с помощью TrimomaticSE, чтобы оставить только чтения с достаточно хорошим качеством и удалить адаптеры. На рисунках 1-2 показано качество чтений до и после тримирования. Как видно, у начальных данных конец прочитан довольно плохо, а после тримирования качество учучшилось.
С этими очищенными данными уже возможна сборка генома при помощи velvet. Эта программа работает в два шага: velveth строит граф на k-мерах (в нашем случае k=31), а velvetg собирает контиги на основе этого графа. Использованная команда:
$velveth assembly/ 31 -file_format fastqc assembly/SRR4240361_2.fastq.gz
$velvath assembly/
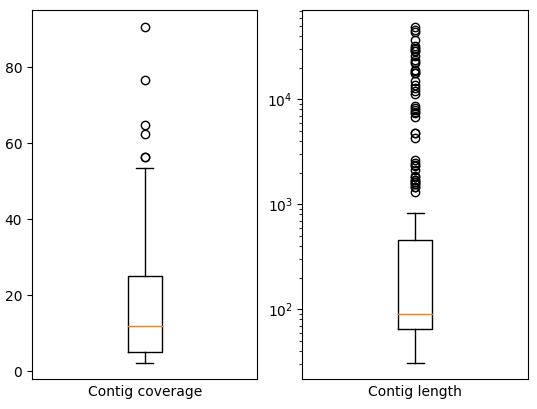
В результате выполнения этой программы я получил файл с контигами, для сборки N50 = 25,683, L50 = 10. 3 самых длинных контига имеют длину и покрытие соответсвеноо 49268 и 26.660851, 45585 и 26.450466, 43896 и 23.514977. На рисунке 3 показаны распределения покрытия и длин контигов. График - боксплот, оранжевая линия - медиана, нижняя и верхняя границы прямоугольника - квартили 1/4 и 3/4 соответсвенно, усы - расстояние до самой далекой точки в выборке на расстоянии не более 1,5 межквартильного размаха от соответсвующего квартиля, точки - выбросы (не попали в 1,5 IQR) 1. Как можно заметить, медиана покрытия примерно равна 12. Тогда есть буквально 3-4 контига с аномально большим/малым * покрытием (отличается в 5 раз от медианы). Например, контиг с покрытием 90.7 имеет длину всего лишь 77 и имееть GC состав 25,97 %. А контиг с покрытием 2.9 имеет длину 94 и GC состав 27.67 %. Для сравнения - GC состав всех контигов 26.61 %.
* - на графике не аномально низкое покрытие как выбросы, так как аномально низкое покрытие - в 5 раз, а усы на 1,5 IQR.
Далее 3 самых длинных контига были картированы на геном Buchnera aphidicola. Самый длинный контиг (длиной 49,268) картировался в 2 длинных участка генома бактерии: первый с 141477 координаты по 176738 (Identities 27019/35909(75%), Gaps 1000/35909(2%)) и второй с 127825 по 140555 (Identities 9533/12902(74%), Gaps 332/12902(2%)) + 60 участков короче 300 нуклеотидов. Возможно, что два длинных участках можно объединить, так как между ними промежуток меньше 1000 нуклеотидов (что значительно меньше их длин, а алгоритм BLAST не гарантирует оптимальность выравнивания). Контиг длинной 45585 картировался уже на 6 длинных участков (440755 to 445894; 462496 to 474667; 474834 to 485673; 447172 to 454069; 454232 to 458588; 460011 to 462351) и 180 коротких. Для длинных участков Identities 70-78%, Gaps 1-4%. Лично мне кажется, что эти 6 участков можно объединить в одно выравнивание, тк они очень близки друг другу, а некоторые вообще перекрываются. Контиг длиной 43896 картировался в общей сложности на 162 участка, из которых 8 длиннее 1000. Длинные участки - 252397 to 257544; 257642 to 264181; 264190 to 265908; 266073 to 285067; 285158 to 286535; 286670 to 291560; 291673 to 292602; 292569 to 294000, Identities 73-79%, Gaps 1-3%. В данном случае, опять же, длинные участки стоит объединить.
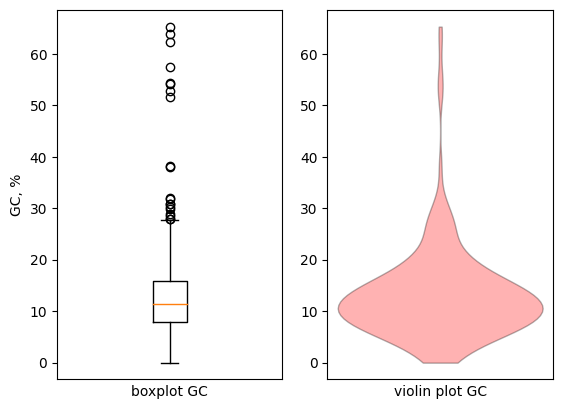
Что касается коротких выравниваний для всех трех контигов, они попоали на разные участки генома, то есть не являются кусками между длинными выравниваниями. Появление такого количества выравниваний, вероятно, связано c несбалансированным GC-составом (~ 25%). Интуитивно кажется, что это будут часто встречаться AT-богатые повторы, которые будут картироваться на повторы в геноме (повторы в геноме довольно частая штука). На рисунке 4 изображено распределение GC сотава участков 3 самых длинных контигов, которые попали в короткие выравнивания (боксплот и виолинплот). Violin plot - плотность вероятности GC состава, предсказанная на основе входных данных. После чего, такая же плотность строится зеркально относительно оси OX и вся эта конструкция поворачивается на 90 градусов. Как можно заметить, абсолютное большинство участков отличается по GC составу в сторону AT относительно контигов (те богаты AT-богатыми повторами, что можно заметить при рассмотрении выравниваний), однако есть и картировки, отличающиеся аномально большим GC-составом.