Алгоритмы и программы множественного выравнивания
Сравнение выравниваний одних и тех же последовательностей разными программами
Множественные выравнивания были построены для seed белковых доменов семейства PF01601, Coronavirus spike glycoprotein S2. Для выравнивания были использованы программы - MUSCLE, TCOFFEE и MAFFT. Сравнивались выравнивания TCOFFEE и MAFFT, TCOFFEE и MUSCLE с помощью программы сравнения множественного выравнивания написанного студентами 2 курса(Гагарочкин Виталий, Масленников Всеволод и Нагорный Даниил) MACHO. Далее результаты были проверены вручную в программе Jalview.
| № | TCOFFEE и MUSCLE | TCOFFEE и MAFFT |
|---|---|---|
| 1 | (26,36)=(26,36) | (159,164)=(146,151) |
| 2 | (443,452)=(383,392) | (311,320)=(268,277) |
| 3 | (465,481)=(405,421) | (402,410)=(362,370) |
| № | TCOFFEE и MUSCLE | TCOFFEE и MAFFT |
|---|---|---|
| 1 | (245,253)=(201,209) | (278,286)=(237,245) |
| 1 | (349,386)=(294,331) | (349,365)=(306,322) |
Ссылкана файл проекта в Jalview.
TCOFFEE, MUSCLE, MAFFT - ссылки на выравнивания, выполненные с помощью различных программ, в FASTA-формате.
Были посчитаны проценты совпадений по колонкам. Самыми похожими оказались выравнивание TCOFFEE и MUSCLE с 20.28% совпадением для выравнивания MUSCLE, а для TCOFFEE 18.03%, это связано с тем, что выравнивание TCOFFEE длинее(732 колонки против 651). При этом процент совпадения колонок для TCOFFEE и MAFFT равен 13.33% для MAFFT(705 колонок) и 12.84% для TCOFFEE.
Выравнивание по совмещению структур и сравните его с выравниванием MSA
Для выравнивания по совмещению структур было выбрано 3 белка из семейства PF01601 Coronavirus spike glycoprotein S2: 9E0I, 6LZG, 7E3J.
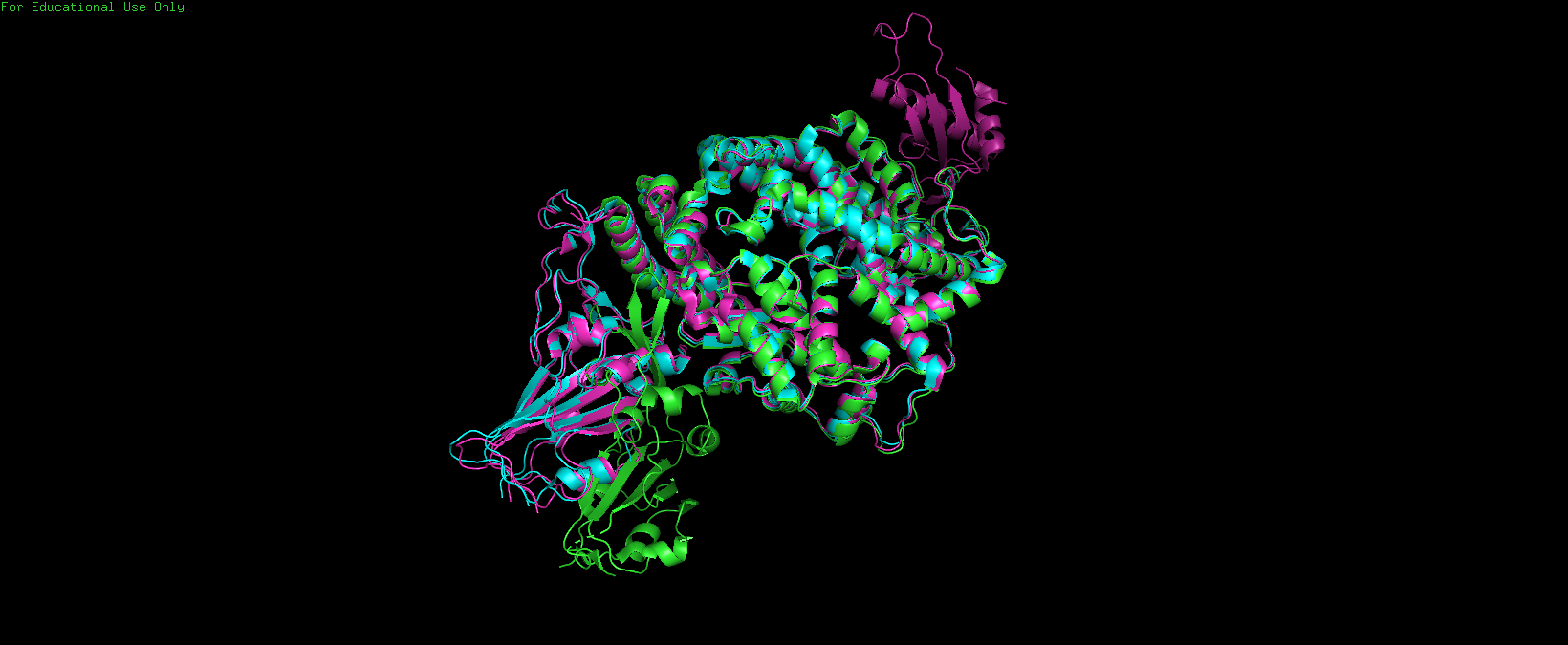
С помощью программы PDBeFold было получено множественное выравнивание по совмещению структур (Рис. 1). Белки также были выравнены программой TCOFFEE для сравнения результатов. Полученные выравнивания проанализированы программой MACHO.
Выравнивания похожи на 15%, вероятно наиболее консервативный участок белка попал в самую большую область совпадения выравниваний, а дальше гэпы расставлялись по разным алгоритмам, что привело к большому количеству только единично совпадающих колонок. В целом количество гэпов в выравнивании PDBeFold выше, чем в TCOFFEE, что делает его длиннее. Совпадающие участки выравнивания чаще соответсвтуют альфа-спиралям, а несовпадающие неупоряоченным участкам.
| № | Совпадения | Несовпадения |
|---|---|---|
| 1 | (3,118)=(3,118) | (119,126)=(119,126) |
| 2 | (369,369)=(369,369) | (201,294)=(201,294) |
| 3 | (507,508)=(507,508) | (476,501)=(476,501) |
Ссылкана файл проекта в Jalview.
TCOFFEE, PDBeFold - ссылки на выравнивания, выполненные с помощью программ, в FASTA-формате.
Описание программы T-COFFEE
Алгоритм TCOFFEE имеет дву главные особенности. Во-первых, он использует различные библиотеки парных выравниваний (как локальных, так и глобальных) для построения множественных выравниваний (Рис. 2). Во-вторых, TCOFFEE использует метод опттимизации, который нужен для поиска множественного выравнивания в библиотеке, которая подается на вход, которая наиболее удовлетворяет попарным выравниваниям. Алгоритм учитывает выравнивания между всеми парами на каждом этапе прогрессивного выравнивания, что уменьшает количество ошибок
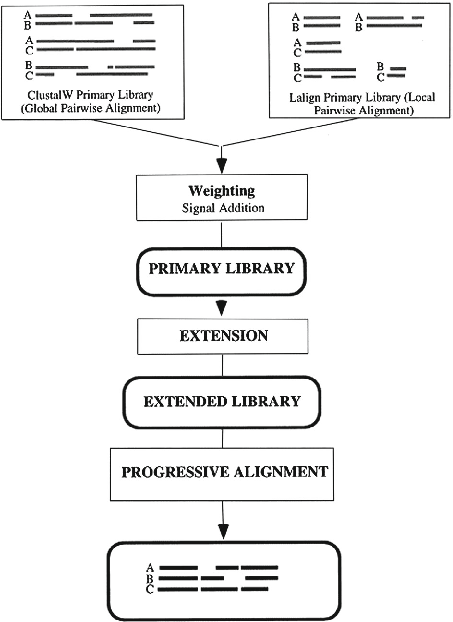
Генерация основной библиотеки выравниваний. Библиотека содержит набор парных выравниваний между всеми последовательностями, которые выравниваются. Для каждой пары используется два выравнивания: глобальное, построеное с помощью СlustalW; локальное, построеное с помощью Lalign. В библиотеке каждое выравнивание представлено в качестве листа попарных совпадений. Не все пары равноценны, что решается использованием весовых коэффицентов библиотеки, которая дает приоритет более правдоподобным парам оснований.
Вывод основных весовых коэффицентов. Каждой паре в библиотеке присваивается свой вес, равный проценту идентивности попарного выравнивания из которого они пришли.
Комбинирование библиотек. Комбинирование достигается благодаря простому процессу добавления. При этом, если некоторые пары повторяются в двух библиотеках, то они объединяются в одну, а вес суммируется. Затем исследуется согласованность каждой пары остатков с парами остатков из других выравниваний. ДЛя каждой пары выровненных остатков в библиотеке присваивается вес, отражающий степень согласованности этих остатков с остатками всех остальых последовательностей. Этот процесс называется расширением библиотеки.
Расширение библиотеки. Если исследуемая пара присутствует в других выравниваниях, например, если остаток последовательности А выравнивается с остатком из C, а тот, в свою очередь с остатком из B, то соответсвие A и B считается согласованным и получает дополнительный вес. При этом добавляется минимальный вес среди выравниваний А и С/В и С. Затем все такие вклады суммируются и получается расширенная библиотека весов. В худшем случае сложность этих вычислений O(N3L2), где L - средняя длина последовательности.
Стратегия прогрессивного выравнивания. Сначала строится дерево с помощью метода neighbor-joining. Самые близкикие последовательности выравниваются с помощью динамического программирования. Затем выравнивается другая ближайшая пара либо же последовательность добавляется к уже готовому выравниванию и так далее пока все последовательности не войдут в выравнивания.
Список литературы
- Notredame, Cédric, Desmond G. Higgins, and Jaap Heringa. "T-Coffee: A novel method for fast and accurate multiple sequence alignment." Journal of molecular biology 302.1 (2000): 205-217.
- Di Tommaso, Paolo, et al. "T-Coffee: a web server for the multiple sequence alignment of protein and RNA sequences using structural information and homology extension." Nucleic acids research 39.suppl_2 (2011): W13-W17..