| Участок структуры | Позиции в структуре (по результатам find_pair) | Результаты предсказания с помощью einverted | Результаты предсказания по алгоритму Зукера |
|---|---|---|---|
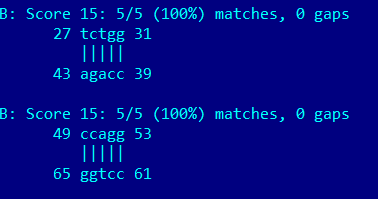
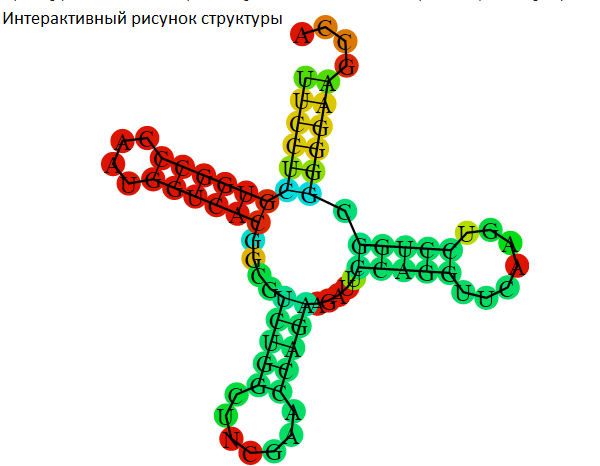
| Акцепторный стебель | 5'-901-907-3' 5'-966-972-3' Всего 7 пар |
0 | Предсказаны 6/7 |
| D-стебель | 5'-910-913-3' 5'-922-925-3' Всего 4 пары |
0 | ПРедсказаны 6/4 |
| T-стебель | 5'-949-953-3' 5'-961-965-3' Всего 5 пар |
Предсказано 5 из 5 реальных | Предсказаны 5/5 |
| Антикодоновый стебель | 5'-939-944-3' 5'-926-931-3' Всего 6 пар |
Предсказано 5 пар из 6 реальных | ПРеедсказаны 5/6 |
| Общее число канонических пар нуклеотидов |
Общее число 22 пары | Общее число 10 пар | Общее число 22 пары |
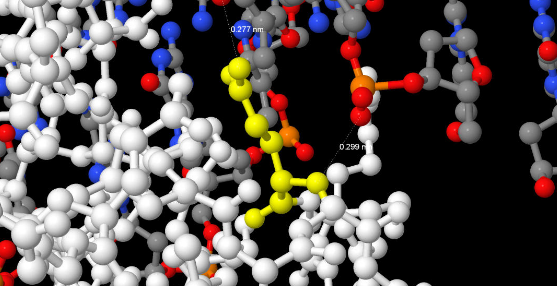
| Контакты атомов белка | Полярные | Неполярные | Всего |
| Остатками 2'-дезоксирибозы | 4 | 41 | 45 |
| Остатками фосфорной кислоты | 54 | 0 | 54 |
| Остатками азотистых оснований со стороны малой бороздки | 0 | 0 | 0 |
| Остатками азотистых оснований со стороны большой бороздки | 7 | 28 | 35 |