Практикум 11
Домены и профили
Поиск консервативных мотивов в выравнивании
Для выполнения этого практикума я взяла домен, который уже использовала ранее, DACZ_N (PF19294). DAC_N - N-терминальная диаденилат циклаза, которая катализирует конденсацию 2 молекул АТФ в циклический ди-АМФ. Для этого домена есть 5 архитектур, я решила выбрать эту:
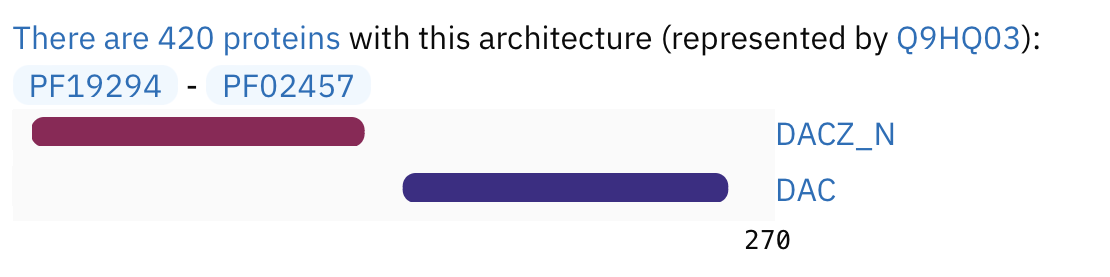
Она встречается в 420 белках. Выравнивание последовательностей всех белков подсемейства(позитивная выборка)
Эти последовательности были выровнены, был оставлен только участок N-конца первого домена до С-конца второго и затем снова производилось выравнивание. Были удалены последовательности, имеющие крупные делеции в районах доменов. Провела ревизию выравнивания: удалила последовательности с идентичностью выше 85% (remove redudancy 85%). Обучающая выборка
Так как всего белков с этим доменом 431, то в качестве негативной выборки мы можем взять их все. Негативная выборка
С помощью следующих команд из пакета HMMER был создан и откалиброван HMM-профиль. Также с помощью него был проведен поиск по итоговой выборке (которая состоит из позитивной, обучающей и негативной выборок):
hmm2build -g hmm_out_new.txt training1.fa
hmm2calibrate hmm_out_new.txt
hmm2search --cpu 1 hmm_out_new.txt full.fasta > hmm2search_out_new.txt
Выдачи программ: HMM профиль двухдоменной архитектуры, находки в итоговой выборке
Потом с помощью скрипта Карины Каримовой, за который я ей выражаю огромную благодарность, была получена итоговая таблица, были построены гистограммы весов выборок и графики ROC Curve и F1 Score.
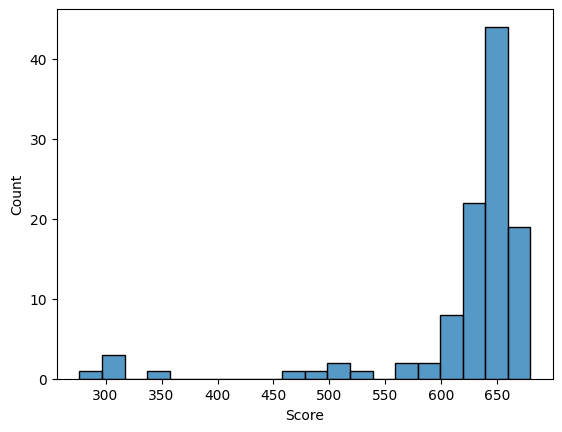
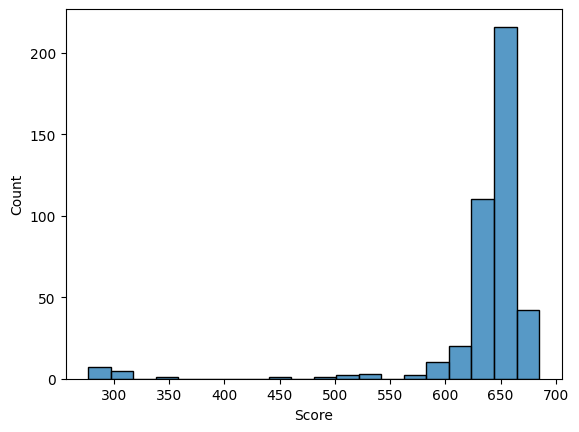
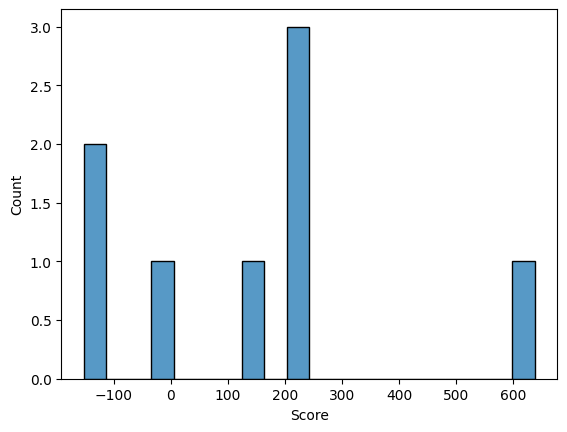
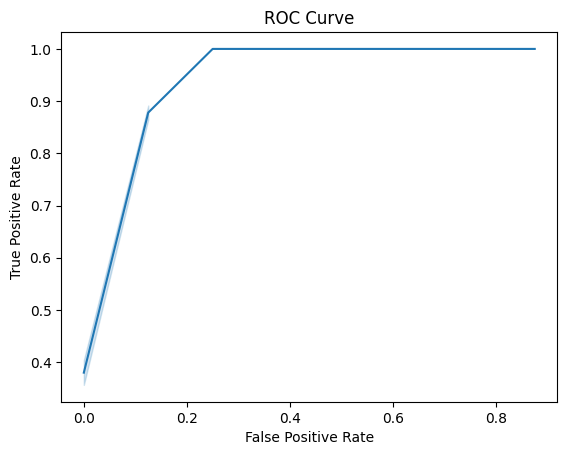
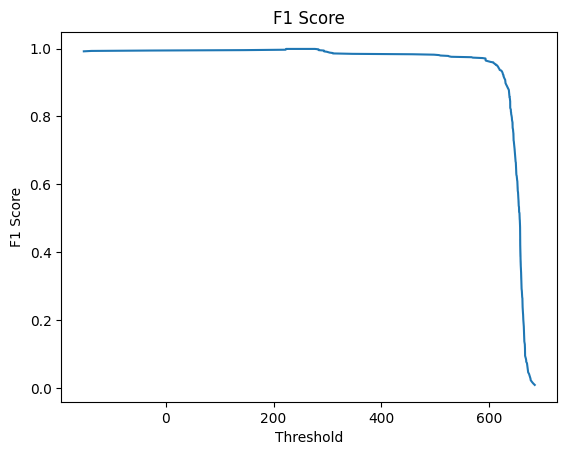
По гистограммам видно, что позитивная и негативная выбрки хорошо разделяются. Также графики показывают, что наша модель очень точно распознает заданную архитектуру