Секвенирование по Сэнгеру. Обработка хроматограмм, расшифровка результатов.
1. Чтение хроматограмм
В ходе данного практикума были обработаны 2 хроматограммы: с прямой и обратной последовательностями, собран контиг и выявлены неоднозначности в хроматограммах. Задание было выполнено при помощи программы UGENE. Для обработки мне были предложены следующие хроматограммы: прямая последовательность и обратная последовательность. Референсная последовательность была получена путем выравнивания прямого прочтения на обратное.
Получившиеся файлы:
консенсусная последовательностьвыравнивание последовательностей с референсом
Характеристика хроматограмм
Границы нечитаемых учатков
Прямая последовательность: 5'- конец – 1-16 нуклеотиды; 3'- конец – 692-702
Обратная последовательность: 5'- конец – 1-31; 3'- конец – нет
Программа Chromas определила как нечитаемые участки 1 - 24, 673 - 702 нуклеотиды прямой последовательности и 1 - 33 нуклеотиды обратной последовательности. UGENE удалил первые 17 нуклеотидов и нуклеотиды 688 - 702 из прямого прочтения, и 39 нуклеотида сконца обратного прочтения.Оценка отношения сигнала и шума, неравномерность силы сигнала и шума
Уровень шума на протяжении всей хроматограммы остается довольно низким (для обеих последовательностей), высота пиков практически везде сильно превосходит шумовые пики. Проблемы возникают вначале и в конце (отсутствуют выраженные пики, присутствуют перекрытия пиков), и в некоторых местах в середине (слишком высокие и широкие пики, появление которых можно объяснить разливом краски).
С помощью Python был получен график, иллюстрирующий качество сигнала для каждого нуклеотида (синий график - прямая последовательность, оранжевый - обратная). Видно, что качество сигнала низкое вначале у обеих хроматограмм, в середине можно заметить серьезные проседания, а в конечном участке наблюдается наибольшая хаотичность пиков, причем качество сигнала в целом хуже у прямой хроматограммы.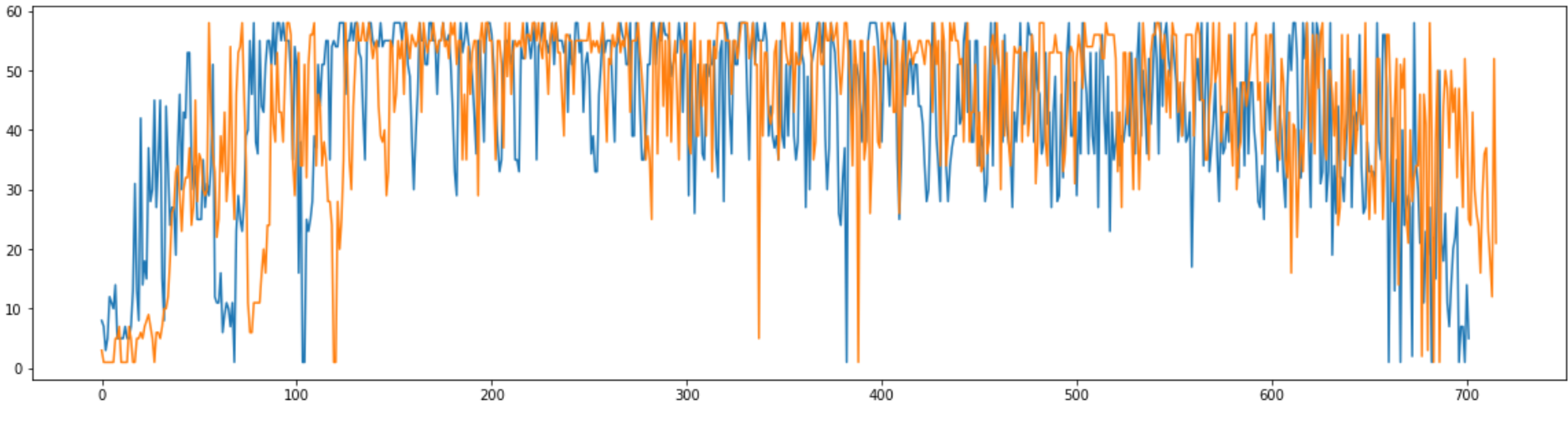
Рисунок 1. График, иллюстрирующий качество сигнала для каждого нуклеотида (синий график - прямая последовательность, оранжевый - обратная)
Problems: полиморфизмы и проблемные нуклеотиды
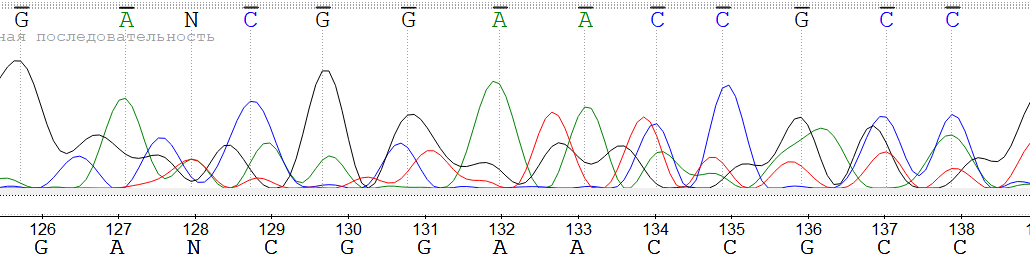
Первое проблемное место находится в районе от 108 до 112 позиции референса. Прямая последовательность находится снизу. Оно возникло по причине разлива краски 106 тимина при обработке прямой последовательности (здесь и далее нумерация ведется по референсной последовательности). Были удалены нуклеотиды прямой последовательности, находящиеся между 107 и 108, а также 109 и 110 позициями референса; 108 нуклеотид был изменен на цитозин, 110 на аденин и 112 на тимин - здесь произошел небольшой разлив при идентификации 111 аденина, что привело к неверной интерпретации сигнала. Все исправления были сделаны исходя из обратного прочтения.

→
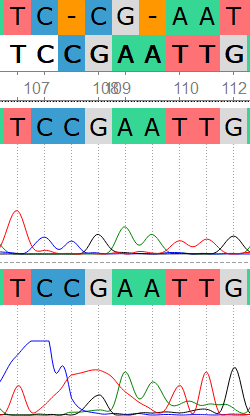
Нумерация съехала из-за удаления нуклеотидов
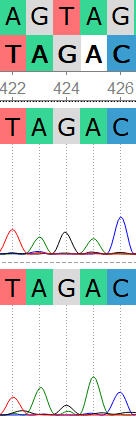
Еще один полиморфизм возник по причине слишком слабого сигнала, и программа интерпретировала данный сигнал как шум. Нуклеотид на 424 позиции был изменен на гуанин (исходя из обратного прочтения).

→
2. Нечитаемый фрагмент хроматограммы
В качестве примера плохого учатска хроматограммы был взят участок из файла kamp3_18SIII_R_F04_WSBS-Seq-1-08-15.ab1 директории bad. Пики очень сильно перекрываются, одной позиции соответствуют несколько пиков разной высоты, нет какого-то одного фиксированного расстояния между пиками. Четко видно, что в образце присутствовало несколько разных фрагментов ДНК.