поиск гомологов и анализ геномов
1. поиск в геноме эукариота гена, кодирующего δ-субъединицу атф-синтазы
в качестве исходного организма я использовала синего кита balaenoptera musculus (refseq-сборка gcf_009873245.2). при просмотре файла с белковыми последовательностями (protein.faa) был найден белок с accession xp_036702995.1, аннотированный как atp synthase subunit delta, mitochondrial; его аминокислотная последовательность сохранена в отдельном файле blue_whale_atp_synthase_delta_protein.fasta.
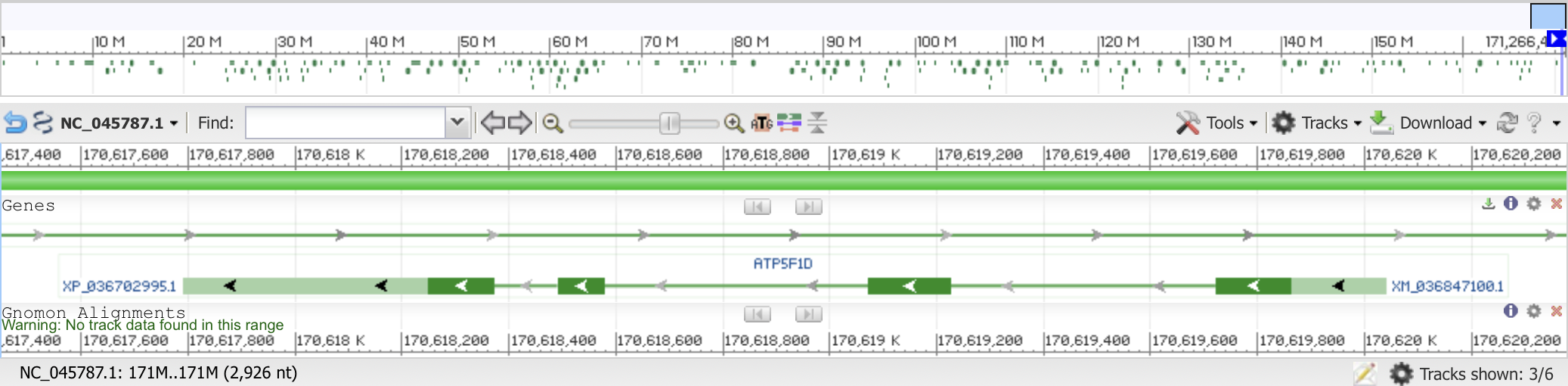
в аннотированном геноме синего кита (хромосома 3, запись nc_045787.1) эта δ-субъединица кодируется геном atp5f1d. в genbank-файле genomic.gbff этому белку соответствует cds-аннотация:
2. пробы разных вариантов blast для фрагмента днк
в качестве запроса для нуклеотидного blast использовался фрагмент хромосомы nc_045787.1, содержащий ген atp5f1d: ref|nc_045787.1|:170617452-170620377; он покрывает кодирующую область δ-субъединицы и небольшие фланкирующие участки. поскольку синий кит - вторичноротое животное, в качестве далёкого таксона для поиска выбраны первичноротые araneae (пауки); поиск проводился по базе refseq_genomes с ограничением по taxid:6893.
2.1. поиск blastn
так как megablast нужен для поиска почти идентичных последовательностей, есть сомнения в том что он предоставит хорошую выдачу. воспользуемся сначала blastn. на вход он принимает нуклеотидную последовательность и сравнивает её просто с нуклеотидной базой данных. в разделе algorithm parameters длина слова (word size) была уменьшена до 7, что повышает шансы найти более отдалённые нуклеотидные гомологи. однако в этом режиме blast сообщил no significant similarity found, не было найдено ни одной значимой гомологии.
blastn.txt2.2. поиск tblastn
будем сравнивать с выдачей tblastn - он берёт на вход аминокислотную последовательность, и алгоритм ищет совпадения уже по шестирамочно переведённой нуклеотидной базе данных. поэтому выдача должна быть в разы больше (или хотя бы просто быть), чем в blastn.
ну и как ожидалось, по этой выдаче я получила целых 4 хита, все с e‑value ниже 10⁻¹⁰; лучший хит имеет e‑value 10⁻¹⁴.
tblastn.txt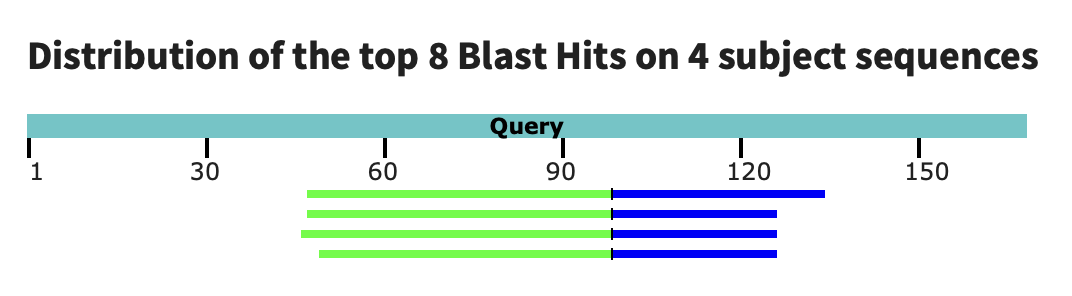
3. поиск генов ррнк в геноме эукариота по далёкому гомологу
3.1. запросы: 16s и 23s ррнк e. coli и параметры blast
в качестве запросов использовались последовательности 16s и 23s ррнк escherichia coli k-12 mg1655 из файла rrna_ecoli.txt с сайта курса; файл содержит две fasta-записи: фрагмент гена 16s ррнк (cp014225.1:complement(926804-928359)) и фрагмент гена 23s ррнк (cp014225.1:2234710-2237641). обе молекулы входят в состав бактериальной рибосомы и выполняют структурные и каталитические функции.
так как и запросы, и база - нуклеотидные последовательности, а также из-за большой филогенетической дистанции, был использован blastn. однако из-за того, что на локальном компьютере бласт не выдавал верные результаты, я воспользовалась веб версией программы. в параметрах я установила в поле Database «refseq_genomes», blastn и ввела последовательность 16S и 23S ррнк E.coli, в поле Organism ввела «Blue whale (taxid:9771)». На выводе получила следующие файлы:
16S.txt 23S.txt3.2. число хитов
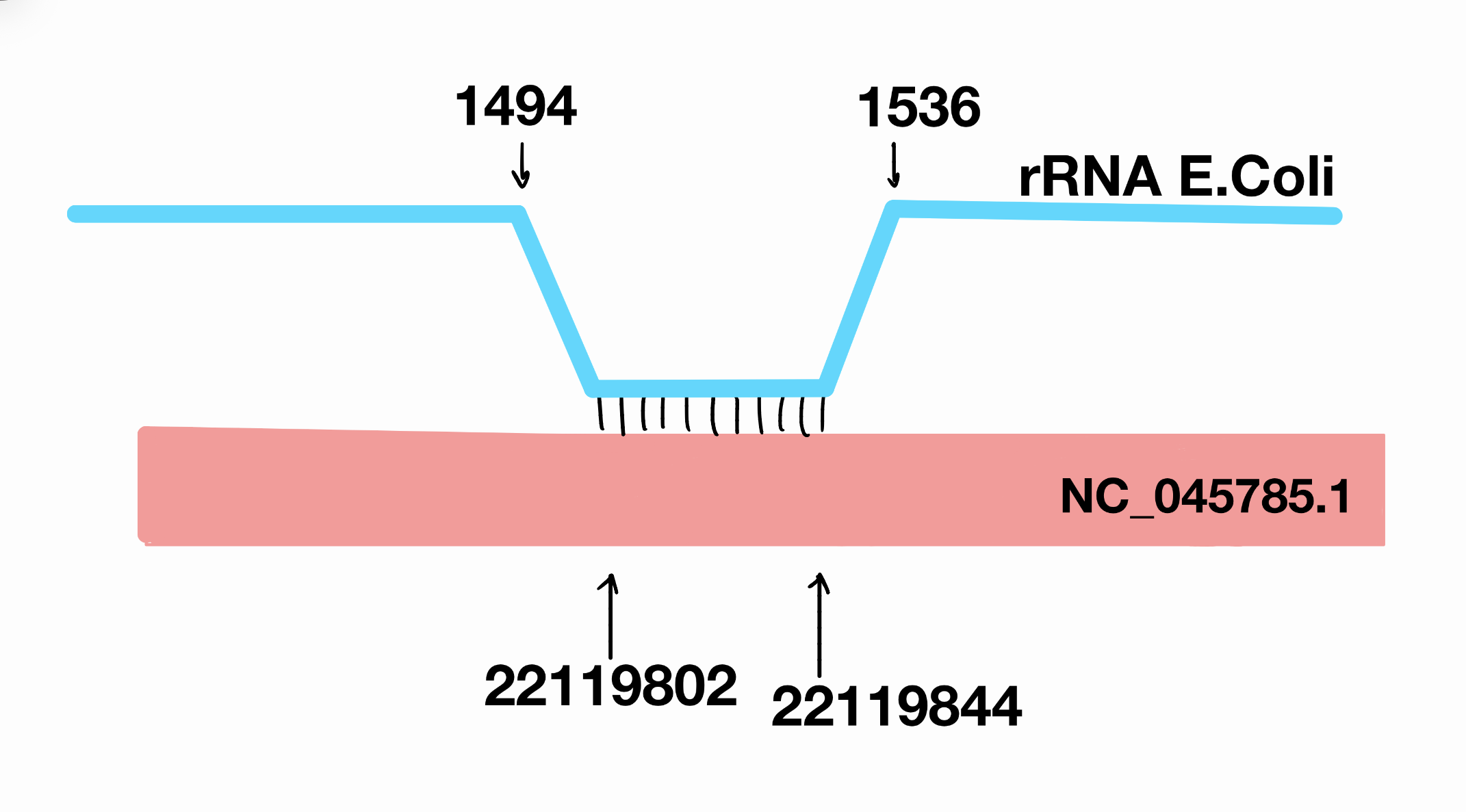
веб версией blastn получилось найти 2 находки (хита) для 16S рРНК, из которых можно выделить однин потенциальный гомологичный участок,основываясь на более значимом e-value (7.68×10^−5) и более высоким score, для 23S - 1 находку. на рис. 3 я привела схему для одного участка 16S рнк на скэффолде NC_045797.1 (цифрами обозначены концы участков выравнивания):
CP014225.1:complement(926804-928359)|16S_rRNA|Escherichia NC_045797.1 86.047 43 6 0 1494 1536 18256514 18256556 0.001 51.8
4. подбор пары геномов и построение карт локального сходства
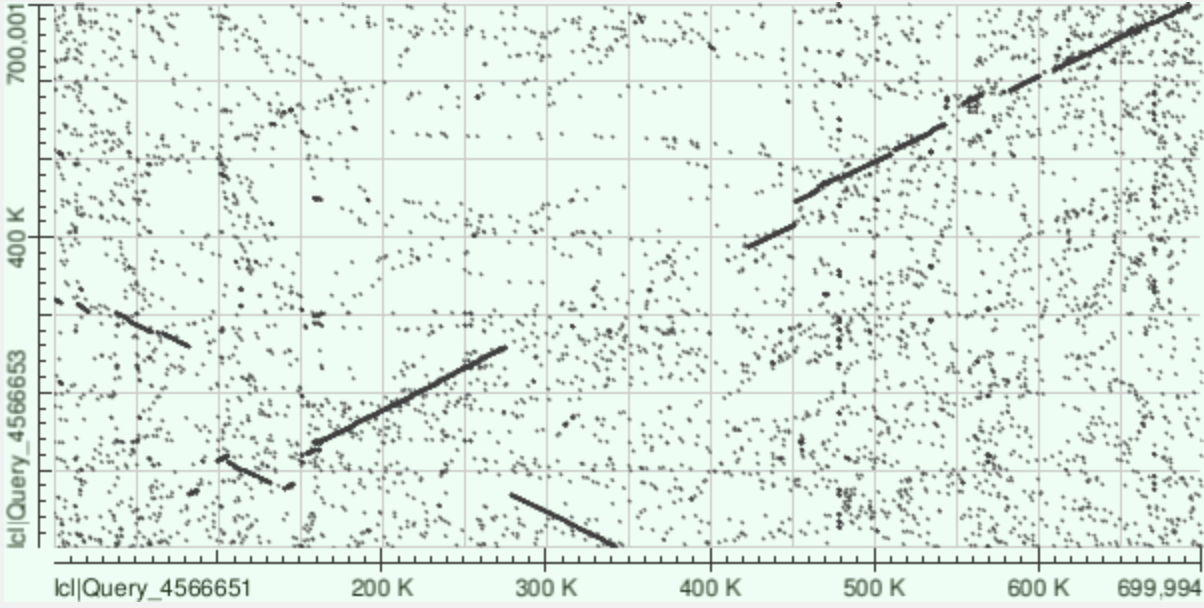
для задания 4 были выбраны два близкородственных бактериальных генома из семейства enterobacteriaceae: референтный геном escherichia coli k-12 substr. mg1655 (nc_000913.3) и shigella flexneri 2a str. 301 (nc_004337.2, assembly gcf_000006925.2). полные последовательности в формате fasta были скачаны с ncbi nucleotide и сохранены локально как ecoli_k12.fna и shigella_2a.fna.
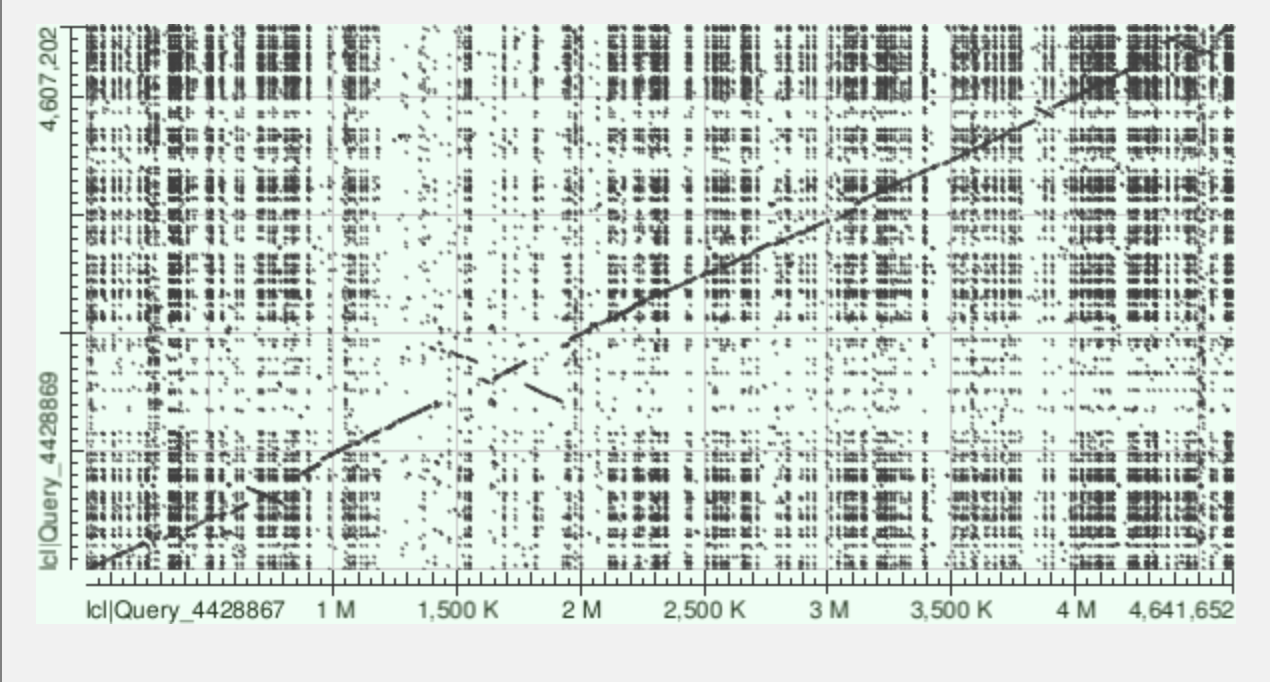
на мегабласт‑картинке основная диагональ и инверсии сохраняются, но фон немного шумный, но незначительно. длинное слово и жёсткие параметры делают megablast менее чувствительным к слабым совпадениям, поэтому на карте в основном остаются длинные и почти идентичные участки, а значительная часть шума отфильтрована алгоритмом.
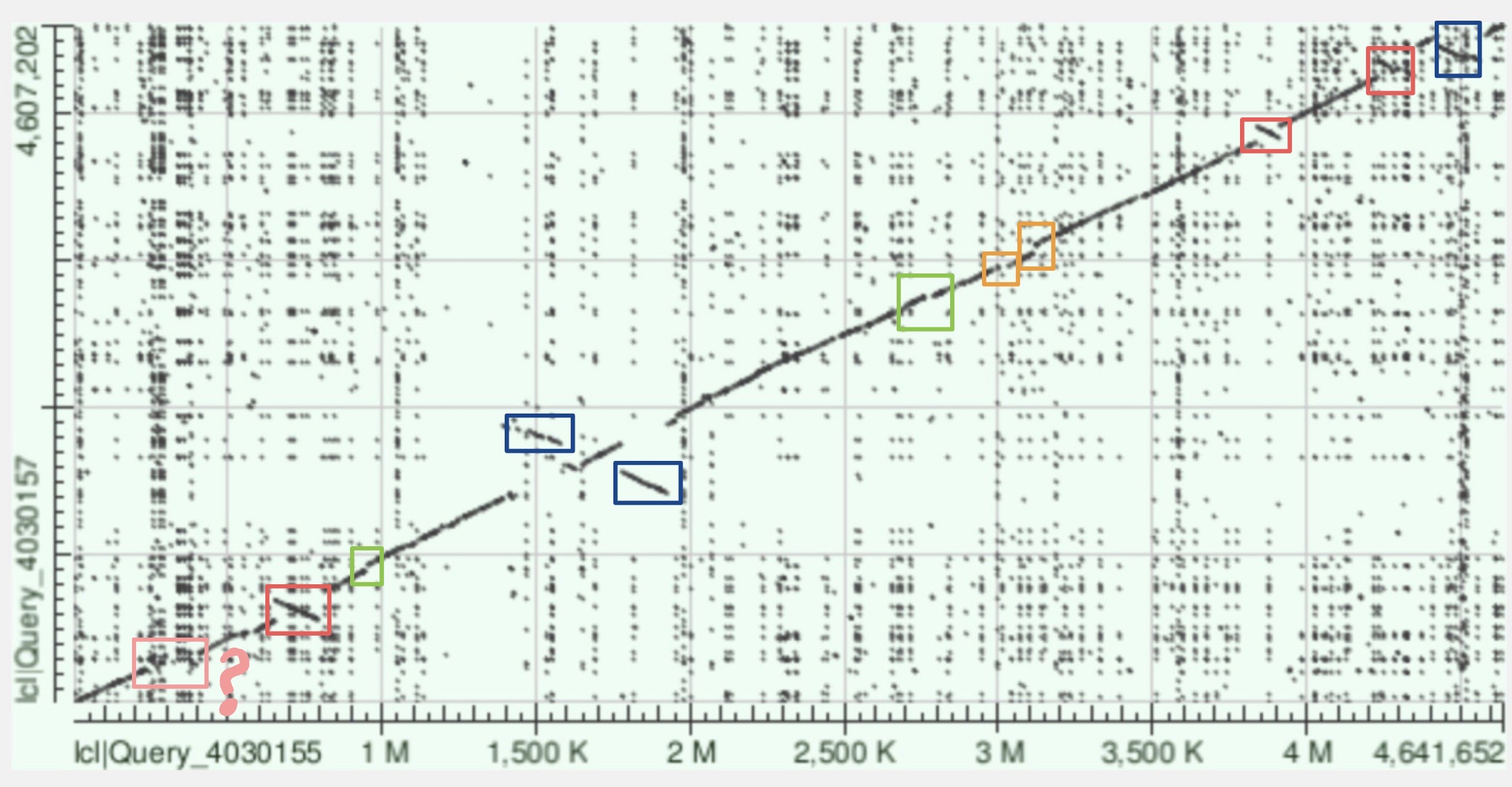
дотплот blastn сильно шумный: вокруг диагонали и по всему полю видно множество коротких локальных совпадений. этот шум обусловлен высокой чувствительностью blastn: меньшая длина слова и параметры поиска позволяют поднимать множество коротких, часто повтор‑индуцированных и частично случайных хитов, которые не складываются в протяжённые синтенные блоки.
веб версия tblastx не справилась с большими геномами, страница с результатами зависала. поэтому поиск проводила, выравнивая по фрагменту генома 1500000-2200000 (наиболее интересный участок, с двумя крупными транслокациями с инверсией). Просто выделив этот фрагмент в веб версии, у меня получился очень неразборчивый дотплот. Было принято решение с помощью EMBOSS скачать последовательности и вырезать нужные фрагменты. Я использовала команды:
После чего файлы с вырезанными фрагментами загрузила на сайт и выровняла последовательности.
В результате получила дотплот (рис.6), в котором можно заметить транслокации с инверсией (30-80к или 1530000-1580000 в полном геноме; 280-340к или 1780000-1840000 в полном геноме), инверсии (100-130к или 1600000-1630000 в полном геноме), крупную делецию (350-430к или 1850000-1940000 в полном геноме), вставки (450-460к или 1950000-1960000 в полном геноме; 540-550к или 2040000-2050000 в полном геноме; 560-570к или 2060000-2070000 в полном), мисматч (600-610к или 2100000-2110000 в полном)