Алгоритмы множественного выравнивания
1. Различия во множественных выравниваниях
Первое задание состоит в сравнении множественных выравниванй, построенных разными программами (T-Coffee и Muscle). Раскраска ClustalX (Identity 100%). Для примера я решила вязть пять белков, гомологичность которых
я проверила в предыдущем практикуме [1]. А именно:
| ID |
Name |
Coverage (%) |
Identity (%) |
E-value |
Homology(+/-) |
| WP_002258782.1 |
pilin family protein |
93% |
97% |
3e-56 |
+ |
| WP_061734064.1 |
pilus assembly protein PilS |
98% |
82% |
6e-52 |
+ |
| WP_061818162.1 |
pilin |
97% |
77% |
7e-48 |
+ |
| WP_002225897.1 |
fimbrial protein MS11-D1 precursor |
98% |
77% |
6e-47 |
+ |
| WP_079758344.1 |
fimbrial protein P9-2 precursor |
98% |
75% |
4e-45 |
+ |
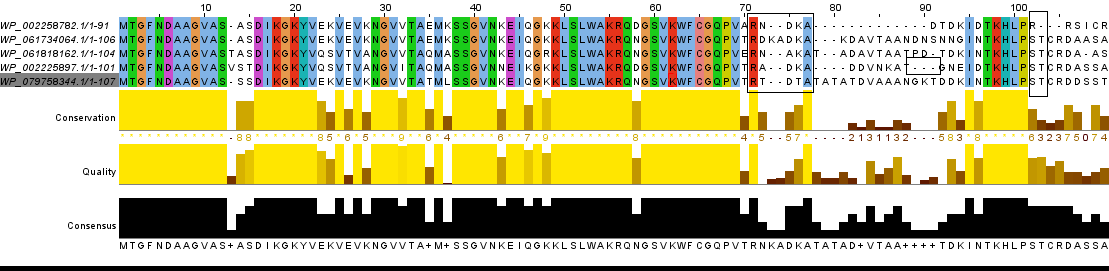
Рис.1 Выравнивание при помощи T-coffee

Рис.2 Выравнивание при помощи Muscle
Различия в выравниваниях в двух разных программах выделены
на рис. 1 и 2 черными прямоугольниками.Во-первых, интересно, что между 70 и 80 позициями есть две абсолютно консервативных колонки: R и A, и в выранивании T-coffee между ними есть еще 4 колонки и почти во всех строчках есть гэп, тогда как в выранивании Muscle между консервативными аминокислотами - 3 колонки, есть только один индель в одной из последовательностей.
Во-вторых, В позиции с 89 по 91 четвёртой последовательности:в T-coffe в этих позициях гэп, а в Muscle - TGN. В-третьих, после консевативного блока в районе 100й позиции в T-coffe есть гэп, а в Muscle его нет. Длина выравнивания в обоих
случаях совпадает.
В целом можно отметить, сравнение двух выравниваний в разных программах в какой-то cтепени отражает и биологический смысл: мы видим, что "показания" программ в случе консервативных блоков сходятся, что указывает на высокую вероятность гомологии этих участков. Области между блоками несколько отличаются, поэтому точно предсказать
эволюционные события с помощью алгоритма в этом случае довольно сложно. Три описанных отличия просто отражают то, что разные алгоритмы могут по-разному интепритировать различия в гомологичных последовательностях. Для уточнения таких неясных моментов, необходимо проверять выравнивание вручную. Здесь, как мне кажется, сравнение выравниваний в нескольких разных программах может оказаться очень полезным.
2. Доменные архитектуры
Необходимо описать 3 доменных архитектуры, содержащих один и тот же домен. Для выполнения практикума я взяла белок пилин (ANW70673.1)
[2] организма Neisseria meningitidis [3].
С помощью ресурса Pfam [4] я нашла 13 архитектур своего белка.
Рассмотрим три архитектуры из найденых:
1. Самая простая и растространенная

Наиболее частая доменная архитектура (636 последовательнстей). Сотстоит из двух доменов: 1) N-methyl - прокариотический N-концевой метилирующий мотив. Этот короткий
мотив работатет с фенилаланином и чаще всего предшествует пилину и некоторым похожим на него белкам. 2) Всё верно, слудующий домен - Pilin :). Пилин - белок, из которого состоят
бактериальные структуры пили, которые участвуют в обмене генетическим материалом между бактериями (коньюгация). Пилин обладает рядом функий, так, у
"моего" организма - Neisseria meningitides, трансформация требует присутствия коротких DNA uptake sequences (DUSs), которые узнаются пилином 4го типа, ComP.
2. Дупликация

Длина - 252 аминокислоты, нашлось 4 последовательности, соответстующие такой доменной архитектуре. Эта доменная архитектура включает два домена пилина, идущих подряд. Возможно, её эволюционное "развитие" включало событие дупликации.
3. Домен, не похожий по функции

Длина - 402 аминокислоты, нашлось 7 последовательностей, соответстующие такой доменной архитектуре.
Помимо в этой архитектуре пилику предшествует пептидаза М48 (не совсем понимаю, это просто совпаделие, или расположение пептидазы рядом с доменом пилина имеет какой-то биологический смысл).
Модель пилина:
Источники:
1. Практикум 12
2. Краткая информация о белке
3. Краткая информация о прокариоте
4. Pfam
|