Секвенирование по Сэнгеру
Исходные файлы с прочтениями ДНК: прямое и обратное. Контиг.
Отредактированные последовательности: прямая и обратная. Контиг из отредактированных последовательностей. Выравнивание.
Я работала с прочтениями в программе CodonCodeAligner.
Характеристика хроматограммы
Длина трудно читаемых участков:
- для прямого прочтения: 40 нуклеотидов в начале и 44 в конце
- для обратного прочтения: 34 нуклеотида в начале и 42 в конце
Оценка качества


- Высота шума в среднем составляет около 5% от высоты сигнала
- Неравномерность силы сигнала и шума вдоль последовательности: сила шума в несколько раз увеличивается на начальном и конечном участках
Как видно из Рис.1 и Рис.2, на начальном и конечном участках качество сигнала очень низкое, в основном виден шум, а не пики нуклеотидов. Качество первых 20ти букв близко к нулю, от 20го до 90го нуклеотлда качество в среднем растет, а начиная с 90го становится более-менее стабильным, выравнивается в среднем до 45 и падает значительно ниже только в единичных случаях. Шум при этом практически не виден. Примерно с 660го нуклеотида качество начинает падать и в конце доходит практически до нуля, хотя, в отличие от самого начального участка хроматограмма (первые 20 нуклеотидов), где не встречается ни одного нуклеотида с качеством выше 10, здесь есть единичные буквы с нормальным качеством.
Редактирование прочтений
Для того, чтобы отредактировать прочтения, я выравняла их, удалила трудно читаемые участки, а затем искала проблемные нуклеотиды и сравнивала их с нуклеотидами в другом прочтении: смотрела качество и количество пиков и исходя из сравнения принимала решение. Снизу я представила примеры участков, которые посчитала проблемными.
Прим.: сверху расположено прямое прочтение, снизу обратное.

На верхней хроматограмме видно, что программа не смогла однозначно определить 70й нуклеотид. Но в обратном прочтении на том же месте стоит тимин с достаточно явным пиком (качество: 56). Поскольку в прямом прочтении на месте N пик тимина также наиболее явный, я заменила N в 70м положении на T.

Здесь аналогичным образом я заменила N на С в нижнем прочтении и Y на T в верхнем.
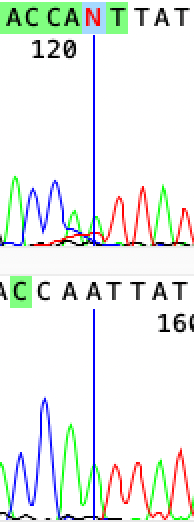
То же самое для 122го нуклеотида. На верхней хроматограмме видно, что на месте N присутствует два заметных пика: аденина и тимина, но пик первого все же выше, а также видно, что на нижней хроматограмме пика тимина нет. Таким образом, красный пик в прямом прочтении, скорее всего, просто шум, поэтому я заменила N на A.
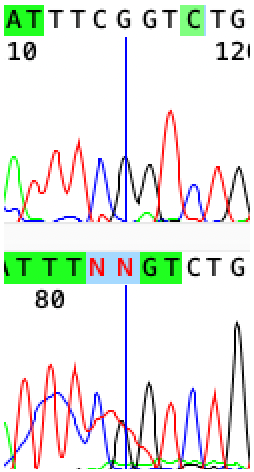
На этом фрагменте прочтений видно, что на нижней хроматограмме пики нуклеотидов довольно значимо перекрываются шумом, но последовательность все же можно восстановить благодаря явным пикам на верхней хроматограмме. Здесь я заменила NN на CG.
Пример нечитаемого фрагмента хроматограммы

На данном фрагменте видно, что присутствует несколько рядов сигналов с пиками сравнимой высоты. При этом наложенние различных пиков появляется не на отдельных участках, а на протяжении всей хроматограммы, так что это не полиморфизм. Такая картина говорит о том, что, вероятнее всего, в секвенатор попало несколько ДНК с разной последовательностью. Поскольку разделить сигналы, исходящие от различных образцов, невозможно, данный фрагмент нечитаем.