Обзор генома прокариот
Обзор генома бактерии Methylovorus glucosetrophus SIP3-4
Клещенко М.Д.
Факультет биоинженерии и биоинформатики, Московский Государственный Университет имени М. В. Ломоносова
КЛЮЧЕВЫЕ СЛОВА:
Methylovorus glucosetrophus SIP3-4, геном, метилотрофные бактерииВВЕДЕНИЕ
Methylovorus glucosetrophus SIP3-4 – бактерия, относящаяся к семейству Methylophilaceae. Оно включает в себя 4 рода, все представители которых – повсеместно распространенные облигатные или факультативные метилотрофы из наземных или пресноводных сред. Данная бактерия использует метиламин. Её геном кодирует ферменты: метанолдегидрогеназа, малатдегидрогеназа. Было установлено, что эти они являются отличительными для первичного окисления субстрата у этого вида[2]. Вероятное практическое применение:
- Метилотрофы выделают ауксин и цитокинин, которые влияют на прорастание семян и рост корней растений, а также помогают растениям переносить водный стресс[3]. Также такие бактерии выделяют осмопротекторы, как сахара и спирты, которые помогают защитить растения от высыхания и чрезмерного излучения[3], фиксируют азот, солюбизируют P, K, Zn. Использование метилотрофных штаммов, в качестве биоудобрений может способствовать надлежащему производству сельскохозяйственных культур[3][4].
- Возможно использование в почвах, покрывающих свалки (полигоны ТБО)[5], так как аэробные метаноокисляющие бактерии преобразуют метан в углекислый газ, тем самым снижая выбросы парниковых газов в атмосферу[1][5].
МАТЕРИАЛЫ И МЕТОДЫ
Для анализа бактерии использовались:
- таблица особенностей из файла GCF_000023745.1_ASM2374v1_feature_table.txt
- геном бактерии из файла GCF_000023745.1_ASM2374v1_genomic.fna
Расчеты проводились в программах Excel и Python:
- Для подсчета длин последовательностей и их GC-состава была написана программа в Python [СМ 2, программа 1]
- Для анализа распределения длин белков и построения диаграммы использовался Excel [СМ 1, лист «Гистограмма»]
- Для анализа распределения генов по функциям использовался Excel [СМ 1, лист «Статистика»]
- Для определения содержания нуклеотидов в молекулах ДНК использовалась программа в Python [СМ 2, программа 2]
- Ссылка на таблицу, в которой проводились статистические расчеты
- Ссылка на Google Collab, в котором написаны программы Python
- Ссылка дляния таблицы особенностей и генома бактерии
- Интернет источник
- Lapidus A, Clum A, Labutti K, Kaluzhnaya MG, Lim S, Beck DA, Glavina Del Rio T, Nolan M, Mavromatis K, Huntemann M, Lucas S, Lidstrom ME, Ivanova N, Chistoserdova L. Genomes of three methylotrophs from a single niche reveal the genetic and metabolic divergence of the methylophilaceae. J Bacteriol. 2011 Aug;193(15):3757-64. doi: 10.1128/JB.00404-11. Epub 2011 May 27. PMID: 21622745; PMCID: PMC3147524.
- Kumar, M., Kour, D., Yadav, A.N. et al. Biodiversity of methylotrophic microbial communities and their potential role in mitigation of abiotic stresses in plants. Biologia 74, 287–308 (2019).
- Yadav, Neelam & Yadav, Ajar Nath. (2018). Biodiversity and biotechnological applications of novel plant growth promoting methylotrophs. 5. 342-344. 10.15406/jabb.2018.05.00162.
- Rai, R.K., Chetri, J.K., Green, S.J., Reddy, K.R. (2019). Identifying Active Methanotrophs and Mitigation of CH4 Emissions in Landfill Cover Soil. In: Zhan, L., Chen, Y., Bouazza, A. (eds) Proceedings of the 8th International Congress on Environmental Geotechnics Volume 2. ICEG 2018. Environmental Science and Engineering(). Springer, Singapore.
РЕЗУЛЬТАТЫ
Общие сведения о геноме
Из таблицы особенностей мы узнали, что геном Methylovorus glucosetrophus SIP3-4 состоит из одной хромосомы и двух плазмид (pMsip01, pMsip02). Из данных о сборке генома можно узнать GC-состав, однако точность его определения мала, поэтому посчитаем значения с помощью программы, написанной в Python [СМ 2, программа 1]. Сведения о длине и GC-составе ДНК можно узнать из Таблицы 1.
| ДНК | Длина, п.н. | GC-состав, % |
|---|---|---|
| Хромосома | 2995511 | 0.54860 |
| pMsip01 | 76680 | 0.45713 |
| pMsip02 | 9816 | 0.47407 |
GC-состав генома свидетельствует о том, что бактерия проживает в умеренных условиях.
Статистические данные о белках протеома
На основании таблицы особенностей был проведен анализ данных о белках протеома, а также построена гистограмма, отражающая количественное распределение белков разной длины. В Таблице 2 приведены данные о диапазоне длин белков, а также среднем и медианном значениях.
| Показатель | Число аминокислотных остатков |
|---|---|
| Минимальная длина | 23 |
| Максимальная длина | 2907 |
| Средняя длина | 322,32 |
| Медиана | 268 |
Как видно из Рисунка 1, в диапазоне 143-183 аминокислотных остатков наблюдается пик. Распределение напоминает положительно скошенное распределение.
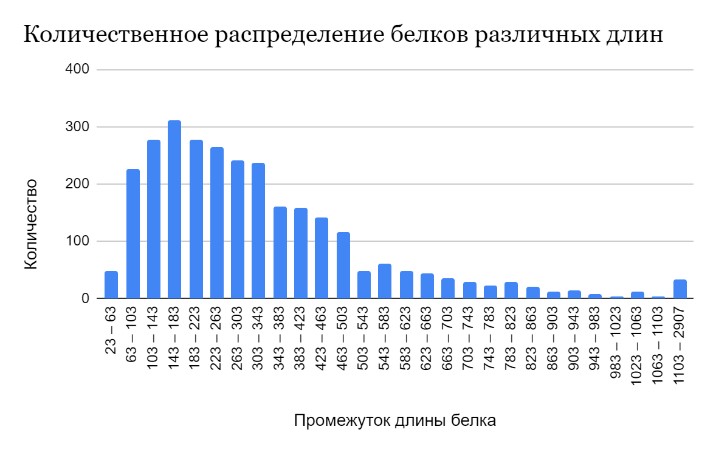
На горизонтальной оси располагаются интервалы, соответствующие количеству аминокислот, а на вертикальной оси – количество белков, длины которых попадают в данный диапазон.
Далее мною был проведен анализ белков по их функциям, результаты приведены в Таблице 3. Исходя из приведенных данных о том, что гипотетические белки составляют целых 14,16%, можем сделать вывод что геном изучен не до конца, ведь средняя длина таких белков составляет 189 аминокислотных остатков, медианное значение чуть меньше – 156, а самый длинный белок и вовсе 1452. Исходя из гистограммы, обсужденной выше, можно сделать вывод, что неизученными остаются белки, которые могут выполнять действительно важные функции, так как основную массу белков составляют протеины именно такой длины.
| Тип белков | Количество белков | Доля белков, % |
|---|---|---|
| Все белки | 2881 | 100,00 |
| Рибосомальные | 59 | 2,05 |
| Транспортные | 174 | 6,04 |
| Гипотетические | 408 | 14,16 |
Также был проведен анализ расположения генов, кодирующих белки, на прямой и комплементарной цепочках ДНК для каждой из молекул и рассчитана вероятность того, что при случайном распределении генов по двум цепочкам мы получим такую же или большую разницу между количествами генов на двух цепочках.
| Молекула ДНК | Цепь | Количество генов | Вероятность случайного распределения |
|---|---|---|---|
| Хромосома | прямая | 1342 | 0,0184 |
| Хромосома | обратная | 1468 | 0,0184 |
| pMsip01 | прямая | 20 | 0,00096 |
| pMsip01 | обратная | 54 | 0,00096 |
| pMsip02 | прямая | - | - |
| pMsip02 | обратная | 12 | - |
В случае, если вероятность больше 0,05 – можно говорить о том, что гены распределены случайно. В нашем случае значения как для хромосомы, так и для первой плазмиды значительно отличаются от 0,05 в меньшую сторону. О случайности распределения для второй плазмиды говорить не приходится, так как ни один ген не расположен на комплементарной цепочке.
Статистические данные о генах РНК
Из таблицы особенностей получены данные о различных закодированных РНК, результаты представлены в Таблице 5.
| Гены РНК | Количество генов |
|---|---|
| Все гены РНК | 60 |
| Гены тРНК | 49 |
| Гены рРНК | 6 |
| tmRNA | 1 |
| SRP_RNA | 2 |
| RNase_P_RNA | 2 |
Также я провела сравнение количества генов, кодирующих белки и различные РНК, получилось, что в 48,02 раза больше генов, несущих информацию про белки.
Описание нуклеотидного состава ДНК
Для этого исследования был написан код в Python [СМ 2, программа 2], который считает для каждой ДНК (только для одной цепи, которая имеется в файле с геномом) количество каждого нуклеотида в последовательности, а также частоту его встречаемости. Результаты приведены в Таблице 6.
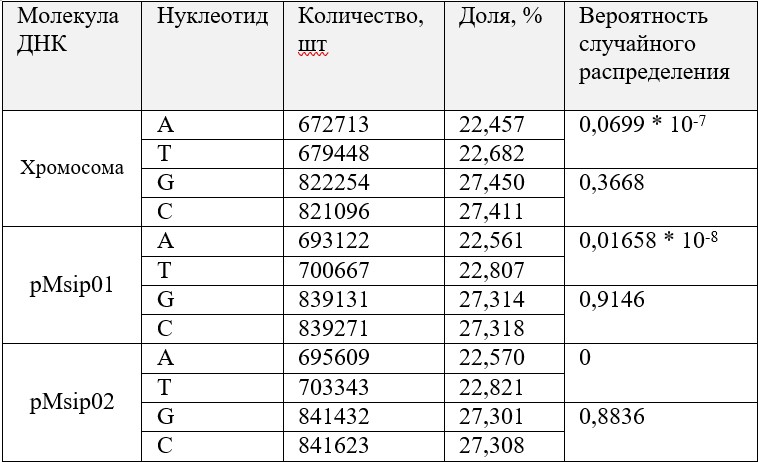
В данном разделе исследования мы хотели узнать случайное ли распределение нуклеотидов внутри пар A-T G-C, для этого мы снова использовали формулу для определения случайности распределения [СМ 1, лист «Статистика»].
При случайном распределении мы бы получили максимально близкие числа нуклеотидов в паре, в данном случае те пары, у которых значение в 5 столбце выше, чем 0,05, имеют практически равные количества нуклеотидов. К таким относятся G-C пары в каждой молекуле ДНК. То есть второе правило Чаргаффа работает для G-C пар у данной бактерии.
Наоборот, количества аденинов и тиминов сильно различаются во всех молекулах ДНК, что можно заметить из таблицы, ведь при малой вероятности, появляются серьёзные основания полагать, что эффект отражает некоторое природное явление.
СОПРОВОДИТЕЛЬНЫЕ МАТЕРИАЛЫ
БЛАГОДАРНОСТИ
Я очень благодарна всем преподавателям биоинформатики за то, что давали нам полезную информацию в течение этого семестра. Результат не заставил долго себя ждать: при исследовании бактерии в данном мини-обзоре я использовала навыки, полученные на занятиях и в ходе выполнения домашних работ.