Входные данные
Мне было выдано 57 названий генов. Примерно одна треть
начинается с буквы G, которая во многих обозначает глутатион. GPX(1-8) - глутатион пероксидазы, GGT(1,5,6,7) -
гамма-глутамилтрансферазы, GSTA(1-5) - глутатион s-трансферазы и тд.
Зачем нужен глутатион: участвует в редокс-зависимых процессах определяется (регуляции клеточного редокс-зависимого
сигналинга и активности транскрипционных факторов), а также является внутриклеточным антиоксидантом, играя роль «ловушки»
свободных радикалов, косубстрата в реакциях детоксикации пероксидов, катализируемых глутатионпероксидазой (GPx) и
глутатионтрансферазой (GST), и выступает в качестве агента, восстанавливающего окисленный глутаредоксин (Grx),
необходимый для восстановления дисульфидов. (РОЛЬ ГЛУТАТИОНА, ГЛУТАТИОНТРАНСФЕРАЗЫ И ГЛУТАРЕДОКСИНА В РЕГУЛЯЦИИ
РЕДОКС-ЗАВИСИМЫХ ПРОЦЕССОВ, Е. В. КАЛИНИНА, Н. Н. ЧЕРНОВ, М. Д. НОВИЧКОВА).
1. STRING
Как только я увидела красивые графы, мне сразу захотелось испробовать эту базу данных. Зачем,
собственно, ее создали - чтобы смотреть белок белковые взаимодействия. Откуда она берет данные? Она
собирает литературные данные об известных экспериментально подтвержденных взаимодействиях. Также она
предсказывает взаимодействия на основе геномных особенностей, а также модельных организмов на основе ортологии.
На вход я подала ей файл со всеми идентификаторами, в качестве организма выбрала Mus musculus
(без выбора конкетного организма построение графа заняло бы значительно больше врмени), оказалось,
что все белки у нее есть, поэтому я получила что-то очень большое (Рис.1) и не особо читабельное.
Однако здесь можно заметить несколько отдельных групп белков, например, Odc1+Sms+Srm - группа белков,
связанных с синтегом спермина - полиамина необходимого для пролиферации клеток, Rrm1+Rrm2+Rrm2b -
субъединицы рибонуклеозиддифосфатредуктазы, поставляющей дезоксирибонуклеотиды для восстановления
ДНК в клетках, остановленных в G1 или G2.

Далее посмотрела, какие белки образуют комплексы друг с другом. Для этого в настройках для Network type установила 'physical subnetwork':

Получилось все очень логично: из мгножества субъединиц Glst** получился большущий комплекс, с каталитической
субъединицей Prdx6, который занимается восстановлением пероксида водорода и органических гидропероксидов до воды и спиртов.
А теперь я решила сделать MCL кластеризацию - поиск естественных кластеров на основе стохастического
потока. Получилось, что я правильно выявила два из четырех. Надо еще отметить этот: Anpep+Lap3+Nat8 - группа
белков, занимающихся метаболизмом белков: две аминопептидаза и N-ацетилтрансфераза. Что важно заметить,
так жто что Nat8 меньше связан с основным кластером, он еще и единственная N-ацетилтрансфераза.

Далее в разделе Analysis посмотрела на биологические процессы GO:
1. Cellular response to thyroxine stimulus
2. Glyoxylate cycle - модификация цикла трикарбоновых кислот, при которой изоцитрат расщепляется до глиоксилата и сукцината
3. Glutathione catabolic process
4. Glutathione derivative biosynthetic process
5. Glutathione biosynthetic process
Теперь мне захотелось посмотреть на что-то более оформленное, поэтому я взяла белки из этого кластера
Anpep+Lap3+Nat8 и 4 случайны, которые были связаны, вот и хотелось посмотреть как
поведет себя в этом случае алгоритм. Получилось, что теперь при MCL кластеризации они все оказываютсяя в одном,
поэтому попробуем другую - k-means. Результат на рисунке 3.

Наша группа Anpep+Lap3+Nat8 осталась вместе в одном кластере, Pgd, бывший поодаль от основой массы
оказался один, но связанный с элементом большого кластера, как это и было в большой схеме. Связи в между кластерами
специально пунктирные, чтобы различать их значимость. Кстати в красной группе нет кольцевого взаимодействия
между белками. Gss, Gclm и Chac2 работают с глутаматными производными.
А еще напоследок я решила убрать ребра, основанные на текстовом майнинге и случилось странное и доказывающее,
что он нужен: мои белки, которые действительно были правильно сгруппированы по тому, с какими веществами они
взаимодействуют, получили гражданство в других кластерах. А один и вовсе сепарировался, что не так страшно, ведь он
и так мало был связан с остальными.

2. Human Protein Atlas
Всегда интересно узнавать что-то про людей, поэтому выбрала эту базу данных. Предлагаю рассмотреть PGD, который
в прошлой части задания стоял поодаль от остальных.
Что же это за белок: Глюкозо-6-фосфатдегидрогеназа — цитозольный фермент, входящий в пентозофосфатный путь,
метаболический путь, обеспечивающий образование клеточного НАДФ-H из НАДФ+, а НАДФ-H в свою очередь необходим для поддержания уровня
восстановленного глутатиона в клетке, синтеза жирных кислот и изопреноидов.
Получается, он стоял поодаль, так как не участвует напрямую в реакциях с глутатионом, но помогает ему существовать.
Для начала я просто вбила его в поисковую строку и мне выдалось много генов, включая мой на первом месте.
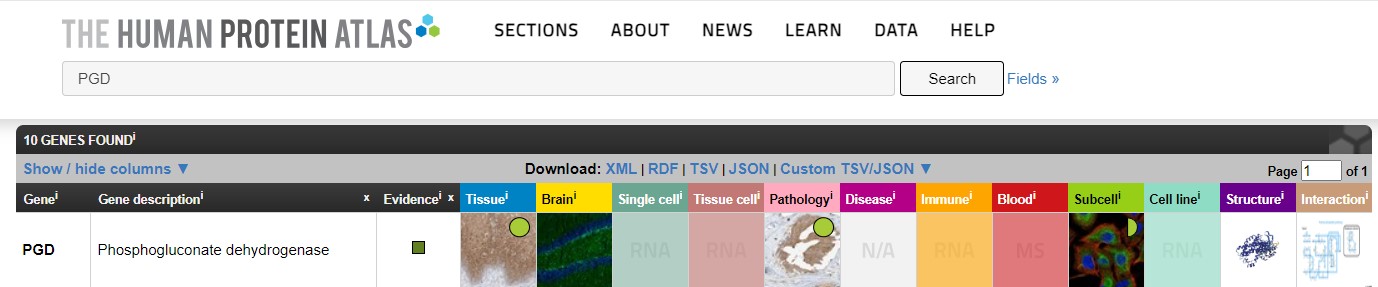
Из карточки данного гена узнаем, что это фосфоглюконат дегидрогеназа, которая
является метаболическим ферментом плазмы. Для него есть 5 транскриптов и не указано ни одного
взаимодействия с другими белками, что не сходится с там, что мы видели в прошлой части практикума -
он имеет достаточно много связей.
Теперь рассмотрим поподробнее: этот ген располагается на 1 хромосоме с 10398592 по 10420511 нуклеотиды.
Для продукта есть UniProt ID P52209. На сайте также представлена
3Д структура белка (альфа-спиральный) и его доменная архитектура со ссылками на InterPro: НАДН-связывающий домен и С-концевой.
Как я уже сказала, взаимодействия его с другими белками не указаны, но написано, что он участвует в пентозофосфатном пути.
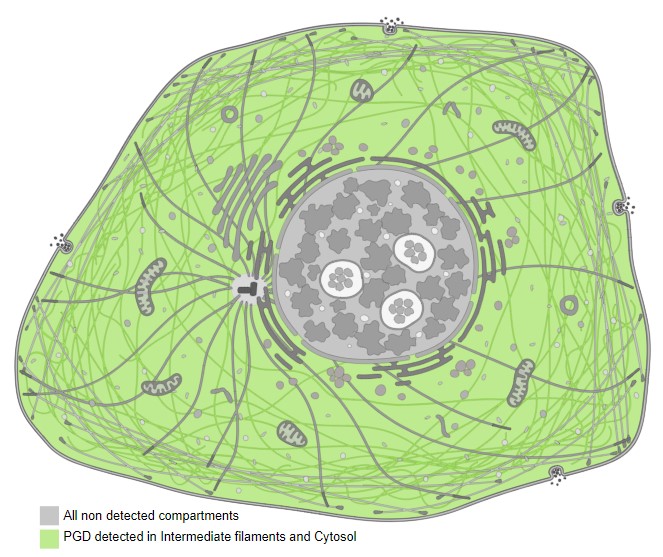
Внутри клеток он содержится на промежуточных филаментах в цитозоле.
Вообще он синтезируется во всех тканях, но его содержание повышено в клетках пищевода и костного
мозга (в основном нужен для пролиферации). В мозге содержится в глиальных клетках: астроцитах
и олигодендроцитах. Его коэффициент специфичности равен 0.36, что означает, что ему не все равно,
где экспрессироваться, но он не супер избирателен.
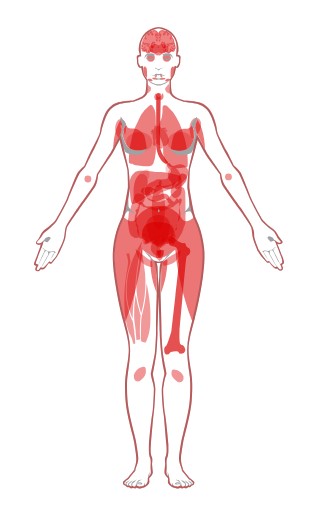
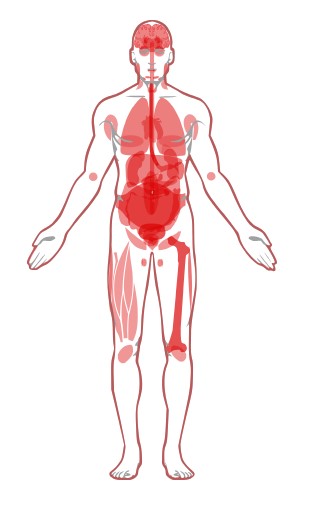
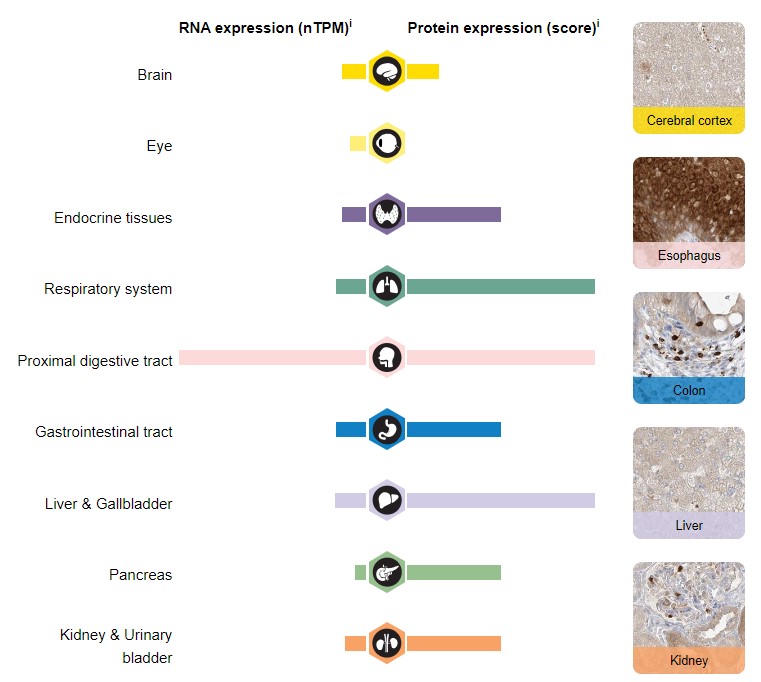
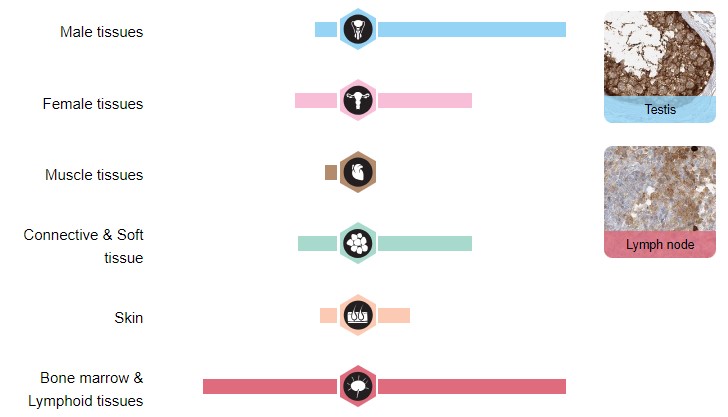
Можно сравнить его расположение у мужчин и женщин (Рис.7). А также уровни экспрессии белка и его мРНК (Рис.8).
Предполагаю, что в тех местах, где уровень белка высокий, но уровень РНК низкий, белок используется не столь
часто, то есть его не надо постоянно заменять, поэтому мало матриц. А в пищеводе и костном мозге - надо.
Есть также возможность посмотреть его содержание в различных клеточных линий, что должно быть удобно экспериментаторам.
Очень выделяется А-549. Это линия раковых клеток легких, в которых содержится супер много нашего белка. Эта информация согласуется
с той, что в легких много белка.
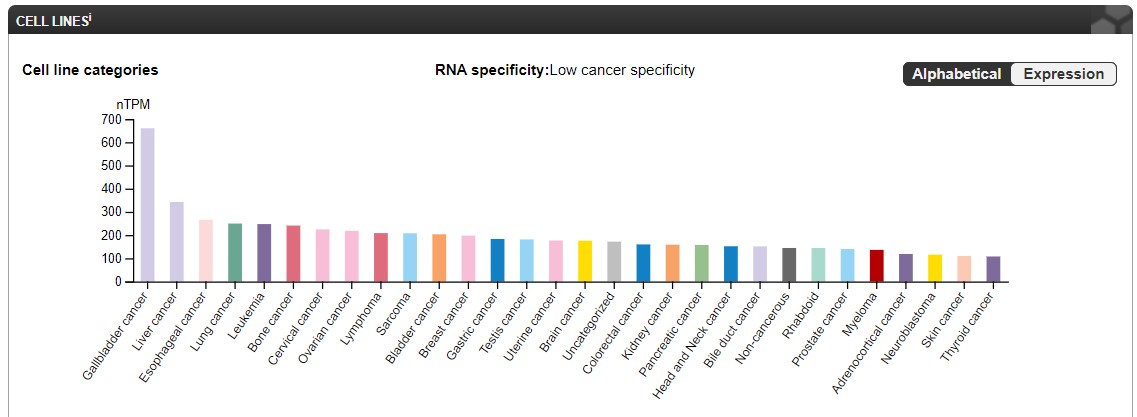
Меня насторожило его повышенное содержание в раковых клетках, поэтому я решила вообще узнать специфичен ли он к раку.
Оказалось, что нет, ведь коэффициент равен 0.20, что классифицируется как низкий уровень. А на картинке ниже можно посмотреть
при каких видах рака повышается экспрессия данного гена.
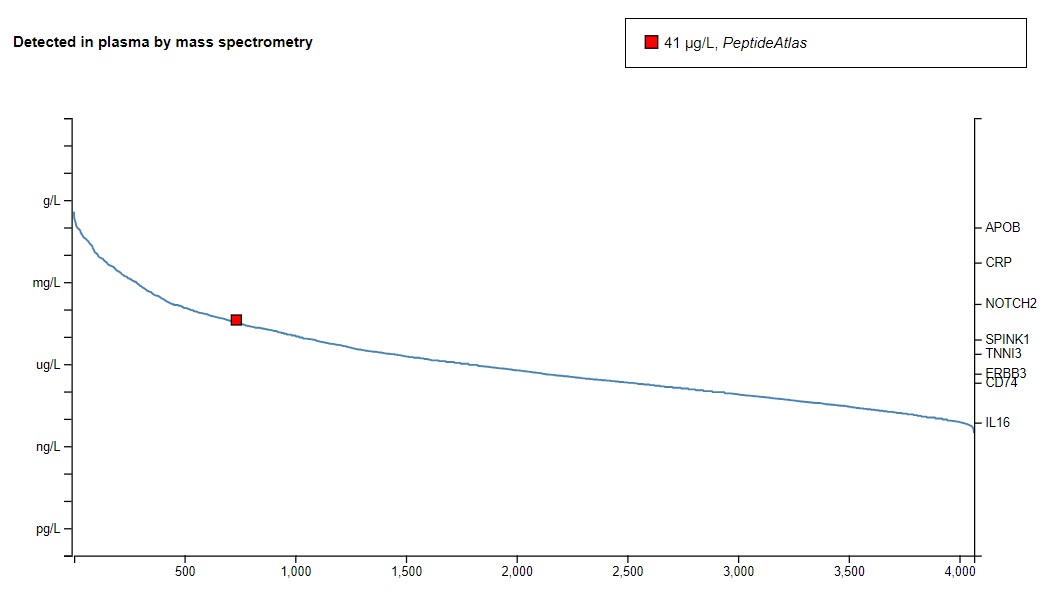
Также есть информация о содержании белка в плазме крови, полученная с помощью масс спектрометрии.
Что хочу скзазать напоследок. Обе базы данных классные! С их помощью мы смогли понять как связаны наши гены. Все
кодируемые белки в той или иной степени связаны с глутатионом: либо напрямую с ним взяимодействуют, либо косвенно, например,
делая реагенты для реакций глутатиона.