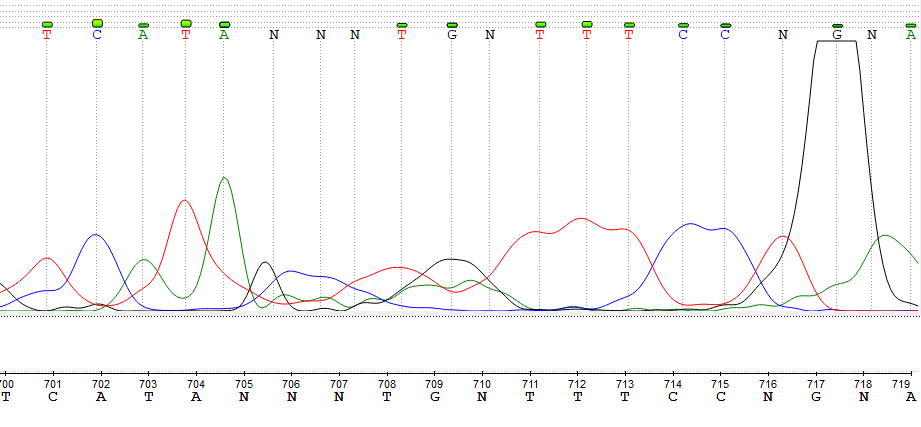
Ручная правка ридов
В ходе работы было замечено, что Pearl куда более чувствителен и зачастую опознает основание там, где UGENE сомневается. При этом решения, принятые Pearl являются правильными, что было проверено сверкой со второй последовательностью
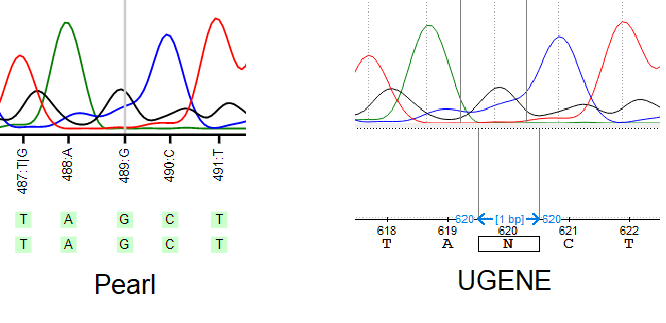
В случае же работы с UGENE абсолютное большинство полиморфизмом может быть исправлено путем сверения с реверс-ридом, так как шанс попадания полиморфизма в одно основание в обоих ридах крайне мала: