Идея
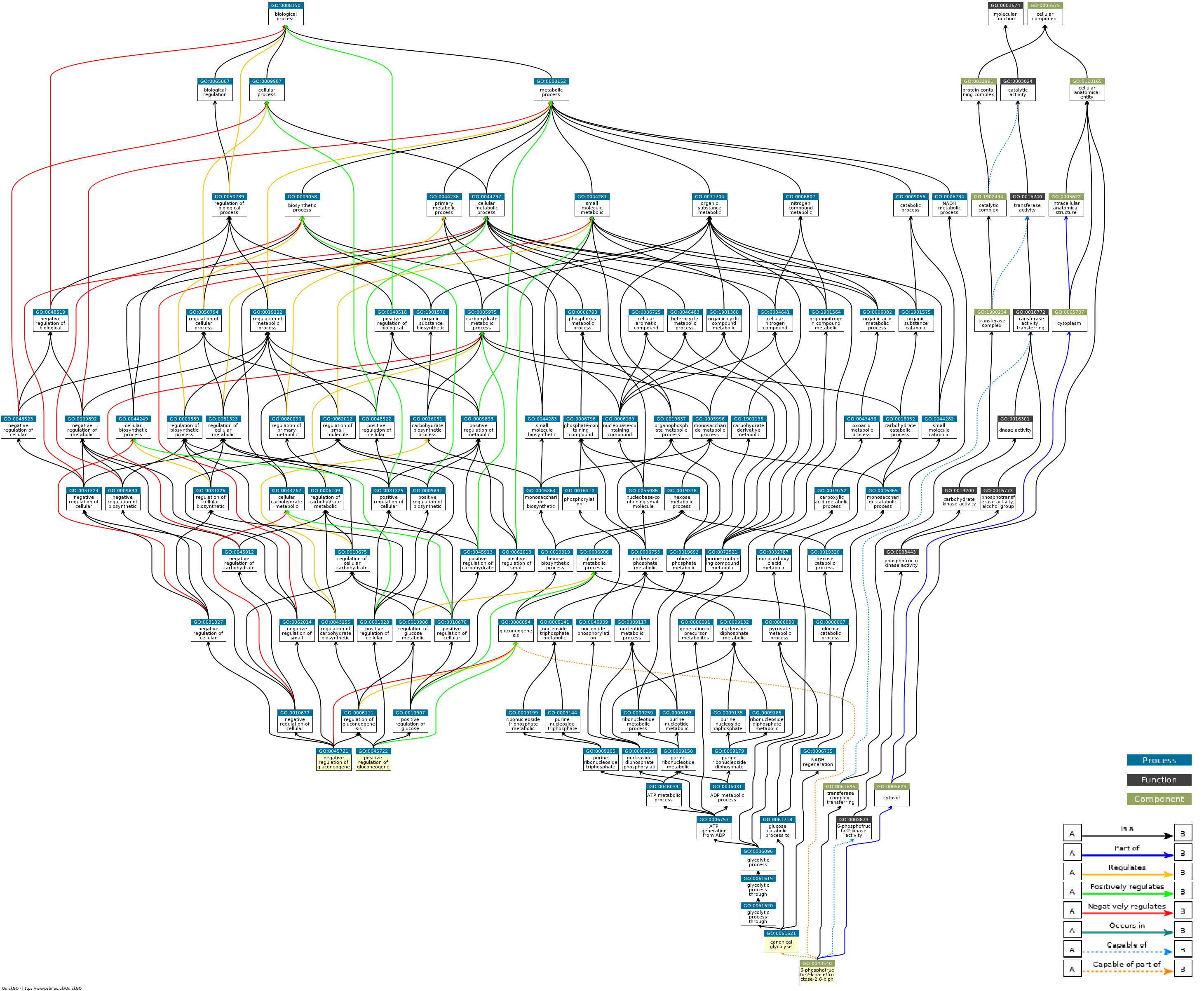
После поверхностного изучения выдачи разных баз данных для данного списка последовательностей было решено остановится на базе Panther и в качестве отчета составить граф связей между различными элементами базы, причастными к исходному списку белков.
Для этого были выбраны 5 записей из базы Biological Processes с наименьшим E-value и сведены в один граф:
Результат был признан недостаточно интересным и непрезентабельным, так как все записе в графе связанны простыми перемычками типа is a и такая схема является крайне малоинформативной и, при детальном рассмотрении всего лишь объясняет значения выбранных терминов.