Геномное окружение. База данных GO.
1.Получение информации о КОГе, к которому относится белок GO.
Для работы был выбран белок, данный в 1-ом семестре – глицин-оксидаза GLOX_BACSU, длинной в 382 а.о.
В поле поиска сервера CDD вставили последовательность этого белка в fasta-формате. Для получения результатов был выбран режим View>Full Results. Всего было найдено три КОГа (кластеры ортологичных групп), представленные в таблице ниже.
ID
Название
e-value
Остатки белка, соответствующие КОГу
Функциональная категория
Glycine/D-amino acid oxidase (Оксидаза D-аминокислот/глицина)
1.12e-55
14 -363
Amino acid transport and metabolism
Транспорт аминокислот и метаболизмL-2-hydroxyglutarate oxidase (L-2-гидроксиглутарат оксидаза)
1.03e-12
98-308
Carbohydrate transport and metabolism
Транспорт углеводов и метаболизмGlycerol-3-phosphate dehydrogenase (глицерин-3-фосфат дегидрогеназа)
2.46e-06
29-310
Energy production and conversion
Продукция энергии и ее преобразование2. Визуализация геномного окружения.
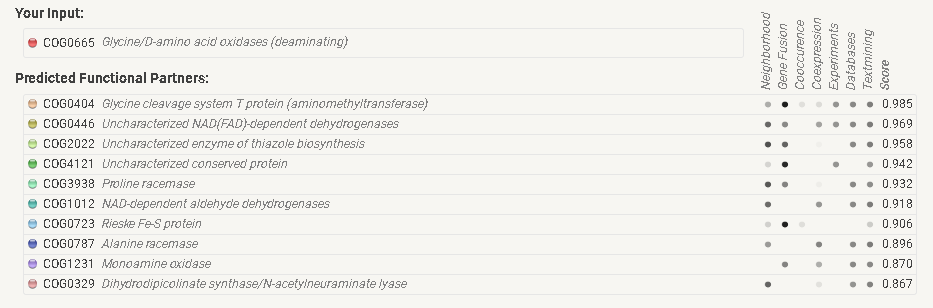
В качестве КОГа был выбран один из 3-х находок, имеющий лучший e-value COG0665.
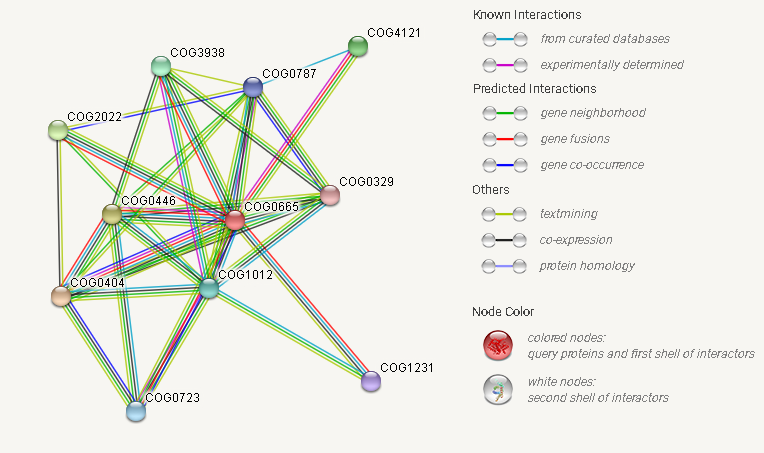
С помощью сервиса STRING было представлено геномное окружения для выбранного КОГа и расшифровка характера взаимодействия различных КОГов(рис.1).Параметры для поиска были выбраны по умолчанию.
Вершинами графа являются КОГи , а ребра графа отражают наличие свидетельств о существовании связи между их белками. Разными цветами обозначаются разные типы свидетельств: достоверно известные (из проверенных баз данных, экспериментально подтверждённые); предсказанные (соседство генов, сшивки генов, совместная встречаемость генов).
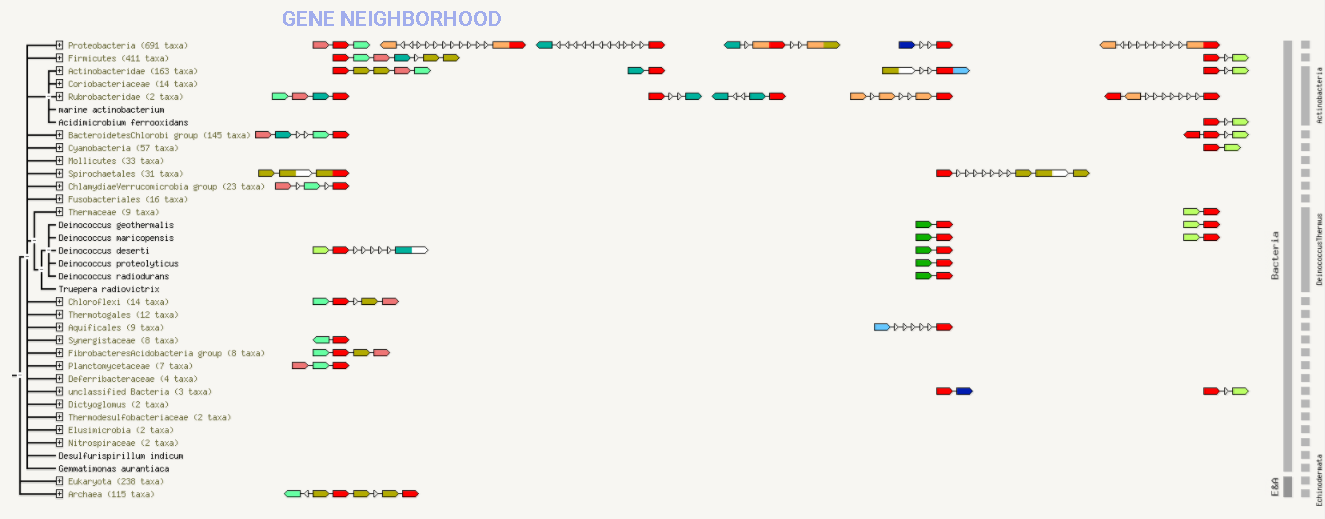
Рис.2 Найденные КОГи и их взаимодействияНа рисунке 3 представлено соседство генов.
Рис.3
О строгой консервативности окружения или о наличии конкретных паттернов говорить не приходится. Тем не менее среди часто встречающихся элементов окружения можно выделить COG3938, белки которого являются пролин-рацемазами. Также можно отметить COG0446, белки которого являются NAD(FAD)-зависимыми дегидрогеназами (неохарактеризованными), а также COG4121, состоящего из неописанных консервативных белков.
3. Отнесение белка GLOX_BACSU к терминам GO.
C помощью инструмента AmiGO BLAST в базе данных GO был найден белок глицин оксидаза (Uniprot ID: Q81UX6) из организма Bacillus anthracis, судя по выравниванию более-менее похожий на GLOX_BACSU (Uniprot ID: Q63342) c e-value 1.8 е-48.
Рис.4 Лучшее выравнивание по результатам AmiGO BLAST.
В таблице 1 описаны все GO, отнесенные к найденному белку (страница белка http://amigo1.geneontology.org/cgibin/amigo/gpassoc.cgi?gp=TIGR_CMR:BA_0730&session_id=8148amigo1500381552#assoc, данные получены по ссылке Term Associations)
Аспект
Идентификатор GO
Название термина
Перевод названия термина
Код типа достоверности
Биологический процесс
GO:0006546
Катаболизм глицина
ISS
Молекулярная функция
GO:0016647
Oxidoreductase activity, acting on the CH-NH group of donors, oxygen as acceptor
Оксидоредуктазная активность ;
ISS
Код достоверности типа ISS (Inferred from sequence similarity), связанный со схожестью последовательностей: используется для аннотации, в основе которой лежит анализ последовательностей (должен быть проведен вручную). Если анализ проведен не вручную, используется код IEA (Inferred from Electronic Annotation). Если применяется комбинация методов и инструментов, анализирующих последовательности, необходимо использовать код ISS. В случае, когда используют лишь один метод, указывается одна из подкатегорий ISS:
- ISA (Inferred from Sequence Alignment): в случае парного/множественного выравнивания
- ISO (Inferred from Sequence Orthology): при оценке ортологичности продуктов белков из разных организмов
- ISM (Inferred from Sequence Model): при использовании моделирования
ISS также используют в случае структурного сходства с экспериментально описанными продуктами генов, установленного с помощью кристаллографии, ЯМР или вычислительных предсказаний. В редком случае на практике код ISS применяют для аннотации, основанной лишь на данных о структуре. Если информация о структуре включена, то обычно она представляет собой данные моделирования вторичной структуры или предсказания структуры, основанного на последовательности. Информация о вторичной структуре бывает особенно полезна в качестве одного из компонентов предсказаний РНК-генов и в некоторых моделях доменов.